Aceleración de consultas de Azure Data Lake Storage
La aceleración de consultas permite a las aplicaciones y los marcos de análisis optimizar considerablemente el procesamiento de datos mediante la recuperación de solo los datos necesarios para realizar una operación determinada. Esto reduce el tiempo y la capacidad de procesamiento necesarios para obtener información fundamental sobre los datos almacenados.
Información general
La aceleración de consultas acepta el filtrado de predicados y proyecciones de columnas que permiten a las aplicaciones filtrar filas y columnas en el momento en que se leen los datos del disco. Solo los datos que cumplen las condiciones de un predicado se transfieren a la aplicación a través de la red. Esto reduce la latencia de red y el costo de proceso.
Puede usar SQL para especificar los predicados de filtro de fila y las proyecciones de columna en una solicitud de aceleración de consultas. Una solicitud solo procesa un archivo. Por lo tanto, no se admiten las características relacionales avanzadas de SQL, como combinaciones y agrupación por agregados. La aceleración de consultas admite datos con formato CSV y JSON como entrada para cada solicitud.
La característica de aceleración de consultas no se limita a Data Lake Storage (cuentas de almacenamiento que tienen habilitado el espacio de nombres jerárquico). La aceleración de consultas es compatible con los blobs de las cuentas de almacenamiento que no tienen habilitado un espacio de nombres jerárquico. Esto significa que puede lograr la misma reducción en la latencia de red y los costos de proceso cuando se procesan los datos que ya se han almacenado como blobs en cuentas de almacenamiento.
Para obtener un ejemplo de cómo usar la aceleración de consultas en una aplicación cliente, consulte Filtro de datos mediante la aceleración de consultas de Azure Data Lake Storage.
Flujo de datos
En el diagrama siguiente se muestra cómo una aplicación típica utiliza la aceleración de consultas para procesar los datos.
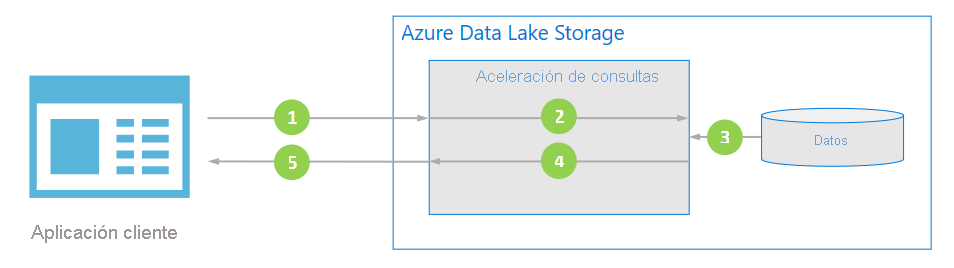
La aplicación cliente solicita datos de archivo mediante la especificación de los predicados y las proyecciones de columnas.
La aceleración de consultas analiza la consulta SQL especificada y distribuye el trabajo para analizar y filtrar los datos.
Los procesadores leen los datos del disco, analizan los datos con el formato adecuado y, a continuación, filtran los datos aplicando los predicados y las proyecciones de columnas especificados.
La aceleración de consultas combina las particiones de respuesta para devolver el flujo a la aplicación cliente.
La aplicación cliente recibe y analiza la respuesta transmitida. La aplicación no necesita filtrar otros datos y puede aplicar directamente el cálculo o la transformación que quiera.
Mejor rendimiento a un menor costo
La aceleración de consultas optimiza el rendimiento mediante la reducción de la cantidad de datos transferidos y procesados por la aplicación.
Para calcular un valor agregado, las aplicaciones normalmente recuperan todos los datos de un archivo y, a continuación, procesan y filtran los datos localmente. Un análisis de los patrones de entrada y salida para las cargas de trabajo de análisis revela que las aplicaciones normalmente solo requieren un 20 % de los datos que leen para realizar un cálculo determinado. Esta estadística es verdadera incluso después de aplicar técnicas como la eliminación de particiones. Esto significa que el 80 % de los datos se transfieren a través de la red, se analizan y se filtran mediante las aplicaciones innecesariamente. Este patrón, diseñado para quitar datos innecesarios, incurre en un costo de proceso significativo.
Aunque Azure incluye una red líder del sector, en términos de rendimiento y latencia, la transferencia innecesaria de datos a través de esa red sigue siendo costosa para el rendimiento de la aplicación. Al filtrar los datos no deseados durante la solicitud de almacenamiento, la aceleración de consultas elimina este costo.
Además, la carga de la CPU necesaria para analizar y filtrar los datos innecesarios requiere que la aplicación aprovisione un número mayor de VM más grandes con el fin de que funcionen. Al transferir esta carga de proceso a la aceleración de consultas, las aplicaciones pueden obtener un importante ahorro en los costos.
Aplicaciones que pueden beneficiarse de la aceleración de consultas
La aceleración de consultas está diseñada para marcos de análisis distribuidos y aplicaciones de procesamiento de datos.
Los marcos de análisis distribuidos, como Apache Spark y Apache Hive, incluyen una capa de abstracción de almacenamiento en el marco de trabajo. Estos motores también incluyen optimizadores de consultas que pueden incorporar conocimiento de las capacidades del servicio de E/S subyacente al determinar un plan de consulta óptimo para las consultas de usuario. Estos marcos están empezando a integrar la aceleración de consultas. Como resultado, los usuarios de estos marcos ven una latencia de consulta mejorada y un costo total de propiedad más bajo sin tener que realizar cambios en las consultas.
La aceleración de consultas también está diseñada para aplicaciones de procesamiento de datos. Normalmente, estos tipos de aplicaciones realizan transformaciones de datos a gran escala que podrían no conducir directamente a la información de análisis, por lo que no siempre usan marcos de análisis distribuidos establecidos. Estas aplicaciones suelen tener una relación más directa con el servicio de almacenamiento subyacente para que puedan beneficiarse directamente de características como la aceleración de consultas.
Para obtener un ejemplo de cómo una aplicación puede integrar la aceleración de consultas, consulte Filtro de datos mediante la aceleración de consultas de Azure Data Lake Storage.
Precios
Debido al aumento de la carga de proceso en el servicio Azure Data Lake Storage, el modelo de precios para usar la aceleración de consultas difiere del modelo de transacción de Azure Data Lake Storage normal. La aceleración de consultas cobra un costo por la cantidad de datos examinados, así como un costo por la cantidad de datos que se devuelven al autor de llamada. Para más información, consulte Precios de Azure Data Lake Storage Gen2.
A pesar del cambio en el modelo de facturación, el modelo de precios de la aceleración de consultas está diseñado para reducir el costo total de propiedad de una carga de trabajo, dada la reducción de los costos de VM mucho más caros.