Migración de un almacén HDFS local a Azure Storage con Azure Data Box
Puede migrar datos de un almacén HDFS local de su clúster de Hadoop a Azure Storage (Blob Storage o Data Lake Storage) mediante un dispositivo Data Box. Dispone de dos opciones en Data Box Disk: Data Box de 80 TB de datos o Data Box Heavy de 770 TB.
En este artículo le ayudamos a completar estas tareas:
- Prepárese para migrar los datos.
- Copie los datos en un dispositivo Azure Data Box Disk, Data Box o Data Box Heavy.
- Devolución del dispositivo a Microsoft
- Aplicación de permisos de acceso a archivos y directorios (solo Data Lake Storage)
Requisitos previos
Necesita lo siguiente para completar la migración.
Una cuenta de Azure Storage.
Un clúster de Hadoop local que contenga los datos de origen.
Un dispositivo Azure Data Box.
Cablee y conecte su instancia de Data Box o Data Box Heavy a una red local.
Si estás listo, comencemos.
Copia de los datos a un dispositivo Data Box
Si los datos caben en un solo dispositivo Data Box, cópielos en el dispositivo.
Si el tamaño de los datos supera la capacidad del dispositivo Data Box, use el procedimiento opcional para dividir los datos entre varios dispositivos Data Box y, luego, realice este paso.
Para copiar los datos del almacén HDFS local a un dispositivo Data Box, deberá configurar algunas cosas y, después, usar la herramienta DistCp.
Siga estos pasos para copiar los datos mediante las API REST de Blob Storage o del almacenamiento de objetos en el dispositivo Data Box. La interfaz de la API de REST hace que el dispositivo aparezca como un almacén HDFS para el clúster.
Antes de copiar los datos a través de REST, identifique las primitivas de seguridad y de conexión para conectarse a la interfaz de REST en la instancia de Data Box o Data Box Heavy. Inicie sesión en la interfaz de usuario web local de Data Box y vaya a la página Conectar y copiar. En las cuentas de Azure Storage para su dispositivo, en Configuración de acceso, busque REST y selecciónelo.
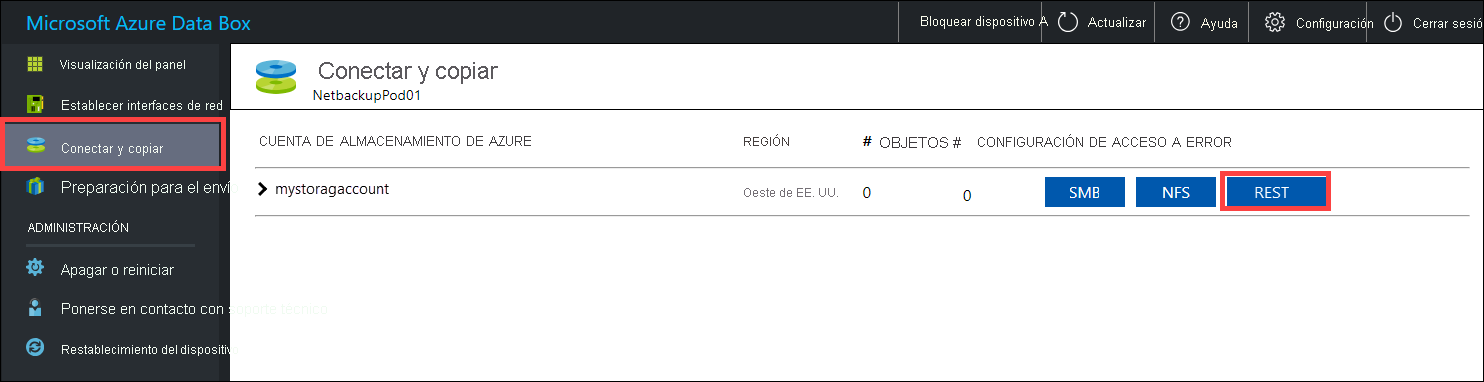
En el cuadro de diálogo Acceder a la cuenta de almacenamiento y cargar datos, copie el valor de Punto de conexión de Blob service y la Clave de cuenta de almacenamiento. En el punto de conexión de Blob service, omita el
https://y la barra diagonal final.En este caso, el punto de conexión es
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. La parte del host del URI que va a usar esmystorageaccount.blob.mydataboxno.microsoftdatabox.com. Para obtener un ejemplo, vea cómo conectarse con REST a través de http.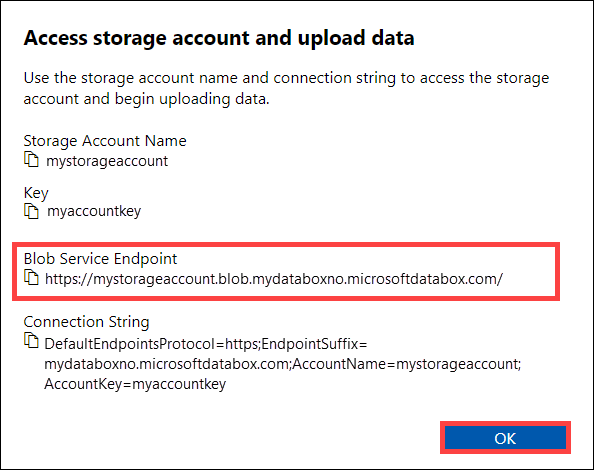
Agregue el punto de conexión y la dirección IP del nodo de Data Box o Data Box Heavy a
/etc/hostsen cada nodo.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comSi usa otro mecanismo para DNS, debe asegurarse de que el punto de conexión de Data Box se pueda resolver.
Establezca la variable
azjarsdel shell en la ubicación de los archivos jarhadoop-azureyazure-storage. Encontrará estos archivos en el directorio de instalación de Hadoop.Para determinar si existen estos archivos, use el siguiente comando:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Reemplace el marcador de posición<hadoop_install_dir>por la ruta de acceso al directorio en el que ha instalado Hadoop. Asegúrese de usar rutas de acceso completas.Ejemplos:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarCree el contenedor de almacenamiento que quiere usar para la copia de los datos. También debe especificar un directorio de destino como parte de este comando. En este momento, podría ser un directorio de destino ficticio.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Reemplace el marcador de posición
<blob_service_endpoint>por el nombre del punto de conexión de Blob service.Reemplace el marcador de posición
<account_key>por la clave de acceso de la cuenta.Reemplace el marcador de posición
<container-name>por el nombre del contenedor.Reemplace el marcador de posición
<destination_directory>por el nombre del directorio en el que quiere copiar los datos.
Ejecute un comando de lista para asegurarse de que se han creado el contenedor y el directorio.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Reemplace el marcador de posición
<blob_service_endpoint>por el nombre del punto de conexión de Blob service.Reemplace el marcador de posición
<account_key>por la clave de acceso de la cuenta.Reemplace el marcador de posición
<container-name>por el nombre del contenedor.
Copie los datos de HDFS de Hadoop a Blob Storage de Data Box, en el contenedor que creó anteriormente. Si no se encuentra el directorio en el que se va a copiar, el comando lo crea automáticamente.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Reemplace el marcador de posición
<blob_service_endpoint>por el nombre del punto de conexión de Blob service.Reemplace el marcador de posición
<account_key>por la clave de acceso de la cuenta.Reemplace el marcador de posición
<container-name>por el nombre del contenedor.Reemplace el marcador de posición
<exclusion_filelist_file>por el nombre del archivo que contiene la lista de exclusiones de archivos.Reemplace el marcador de posición
<source_directory>por el nombre del directorio que contiene los datos que quiere copiar.Reemplace el marcador de posición
<destination_directory>por el nombre del directorio en el que quiere copiar los datos.
La opción
-libjarsse usa para hacer que el archivohadoop-azure*.jary el archivo dependienteazure-storage*.jarestén disponibles paradistcp. Esto ya puede ocurrir en algunos clústeres.En el ejemplo siguiente se muestra cómo se usa el comando
distcppara copiar datos.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataPara mejorar la velocidad de copia:
Pruebe a cambiar el número de asignadores. (El número predeterminado de asignadores es 20. En el ejemplo anterior se usan
m= 4 asignadores).Pruebe a usar
-D fs.azure.concurrentRequestCount.out=<thread_number>. Reemplace el valor<thread_number>por el número de subprocesos por asignador.m*<thread_number>es el producto del número de asignadores y el número de subprocesos por asignador y no debe ser superior a 32.Pruebe a ejecutar varios
distcpen paralelo.Recuerde que los archivos grandes tienen un mejor rendimiento que los pequeños.
Si tiene archivos de un tamaño superior a 200 GB, es recomendable que cambie el tamaño de bloque a 100 MB con los parámetros siguientes:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Envío de Data Box a Microsoft
Siga estos pasos para preparar y enviar el dispositivo Data Box a Microsoft.
En primer lugar, prepárese para enviar Data Box o Data Box Heavy.
Una vez completada la preparación del dispositivo, descargue los archivos BOM. Usará estos archivos BOM o de manifiesto más adelante para comprobar los datos cargados en Azure.
Apague el dispositivo y quite los cables.
Póngase en contacto con UPS para programar la recogida del dispositivo.
Para los dispositivos Data Box, vea Devolución de Data Box.
Para los dispositivos Data Box Heavy, vea Devolución de Data Box Heavy.
Cuando Microsoft reciba el dispositivo, se conectará a la red del centro de datos y los datos se cargarán a la cuenta de almacenamiento que especificó al realizar el pedido del dispositivo. Compruebe con los archivos BOM que todos los datos se han cargado en Azure.
Aplicación de permisos de acceso a archivos y directorios (solo Data Lake Storage)
Ya tiene los datos en su cuenta de Azure Storage. Ahora aplique los permisos de acceso a archivos y directorios.
Nota:
Este paso solo es necesario si usa Azure Data Lake Storage como almacén de datos. Si solo usa una cuenta de Blob Storage sin espacio de nombres jerárquico como almacén de datos, puede omitir esta sección.
Creación de una entidad de servicio para la cuenta habilitada de Azure Data Lake Storage
Para crear una entidad de servicio, consulte Uso del portal para crear una aplicación de Microsoft Entra y una entidad de servicio con acceso a los recursos.
Al realizar los pasos que se describen en la sección Asignación de la aplicación a un rol, asegúrese de asignar el rol de Colaborador de datos de blobs de almacenamiento a la entidad de servicio.
Al realizar los pasos de la sección Obtención de valores para iniciar sesión del artículo, guarde los valores del identificador de aplicación y el secreto de cliente en un archivo de texto. ya que los necesitará pronto.
Generación de una lista de los archivos copiados con sus permisos
En el clúster de Hadoop local, ejecute este comando:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Este comando genera una lista de los archivos copiados con sus permisos.
Nota:
En función del número de archivos en HDFS, este comando puede tardar mucho tiempo en ejecutarse.
Generación de una lista de identidades y asignación de estas a las identidades de Microsoft Entra
Descargue el script
copy-acls.py. Consulte la sección Descarga de scripts auxiliares y configuración del nodo perimetral para ejecutarlos de este artículo.Ejecute este comando para generar una lista de identidades únicas.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gEste script genera un archivo denominado
id_map.jsonque contiene las identidades que necesita para asignarlas a identidades basadas en ADD.Abra el archivo
id_map.jsonen un editor de texto.Para cada objeto JSON que aparece en el archivo, actualice con la identidad asignada adecuada el atributo
targetde un nombre principal de usuario (UPN) de Microsoft Entra o de un ObjectId (OID). Cuando haya acabado, guarde el archivo, ya que lo necesitará en el paso siguiente.
Aplicación de permisos a los archivos copiados y de asignaciones de identidades
Ejecute este comando para aplicar permisos a los datos que ha copiado en la cuenta habilitada de Data Lake Storage:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Reemplace el marcador de posición
<storage-account-name>por el nombre de la cuenta de almacenamiento.Reemplace el marcador de posición
<container-name>por el nombre del contenedor.Reemplace los marcadores de posición
<application-id>y<client-secret>por el identificador de aplicación y el secreto de cliente que recopiló al crear la entidad de servicio.
Apéndice: Dividir datos entre varios dispositivos Data Box
Antes de mover los datos a un dispositivo Data Box, debe descargar algunos scripts auxiliares, asegurarse de que los datos están organizados de modo que quepan en un dispositivo Data Box y excluir los archivos innecesarios.
Descarga de scripts auxiliares y configuración del nodo perimetral para ejecutarlos
En el nodo principal o perimetral del clúster de Hadoop local, ejecute este comando:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderEste comando clona el repositorio de GitHub que contiene los scripts auxiliares.
Asegúrese de que el paquete jq está instalado en el equipo local.
sudo apt-get install jqInstale el paquete de Python Requests.
pip install requestsEstablezca permisos de ejecución en los scripts necesarios.
chmod +x *.py *.sh
Comprobación de que los datos están organizados de modo que quepan en un dispositivo Data Box
Si el tamaño de los datos supera el tamaño de un dispositivo Data Box, tiene la opción de dividir los archivos en grupos que se pueden almacenar en varios dispositivos Data Box.
Si los datos no superan el tamaño de un dispositivo Data Box, puede pasar a la sección siguiente.
Con permisos elevados, ejecute el script
generate-file-listque descargó con las instrucciones en la sección anterior.Esta es una descripción de los parámetros del comando:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Copie las listas de archivos generadas en HDFS con el fin de que estén accesibles para el trabajo DistCp.
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Exclusión de archivos innecesarios
Tendrá que excluir algunos directorios del trabajo DisCp. Por ejemplo, excluya los directorios con información de estado que mantienen el clúster en ejecución.
En el clúster de Hadoop local donde va a iniciar el trabajo DistCp, cree un archivo que especifique la lista de directorios que quiere excluir.
Este es un ejemplo:
.*ranger/audit.*
.*/hbase/data/WALs.*
Pasos siguientes
Aprenda cómo funciona Data Lake Storage con clústeres de HDInsight. Para obtener más información, consulte Uso de Data Lake Storage con clústeres de Azure HDInsight.