Sincronización de varios motores
La mayoría de las GPU modernas contienen varios motores independientes que proporcionan funcionalidad especializada. Muchos tienen uno o varios motores de copia dedicados y un motor de proceso, normalmente distinto del motor 3D. Cada uno de estos motores puede ejecutar comandos en paralelo entre sí. Direct3D 12 proporciona acceso específico a los motores 3D, proceso y copia, mediante colas y listas de comandos.
Motores de GPU
En el diagrama siguiente se muestran los subprocesos de CPU de un título, cada uno rellenando una o varias de las colas de copia, proceso y 3D. La cola 3D puede impulsar los tres motores de GPU; la cola de proceso puede impulsar los motores de proceso y copia; y la cola de copia simplemente el motor de copia.
A medida que los distintos subprocesos rellenan las colas, no puede haber ninguna garantía simple del orden de ejecución, por lo tanto, la necesidad de mecanismos de sincronización, cuando el título los requiera.
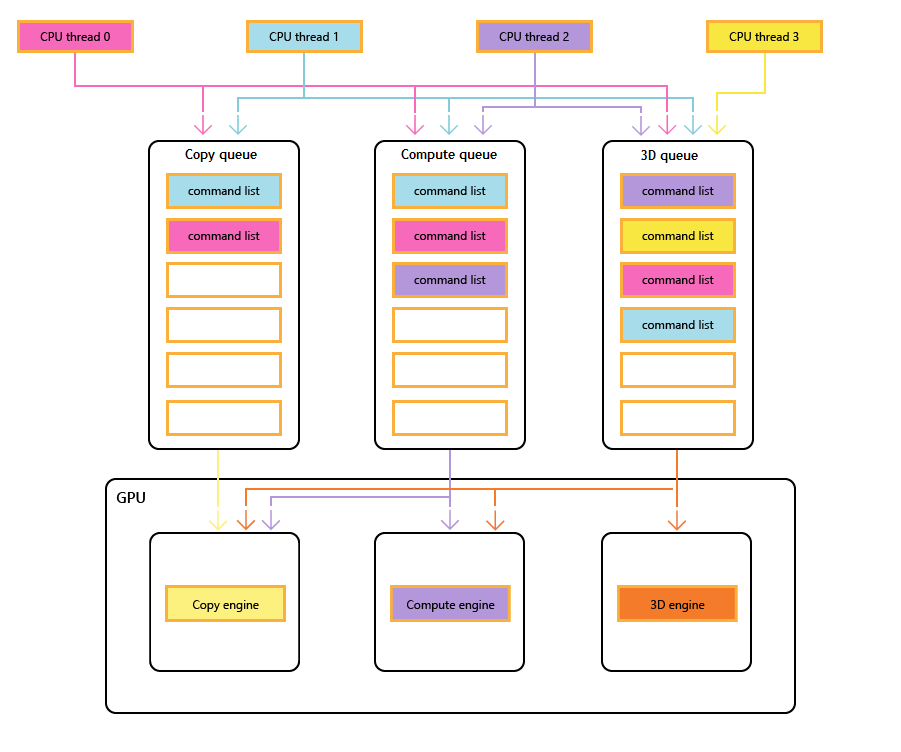
En la imagen siguiente se muestra cómo un título podría programar el trabajo en varios motores de GPU, incluida la sincronización entre motores cuando sea necesario: muestra las cargas de trabajo por motor con dependencias entre motores. En este ejemplo, el motor de copia copia primero alguna geometría necesaria para la representación. El motor 3D espera a que se completen estas copias y representa un paso previo sobre la geometría. A continuación, el motor de proceso lo consume. Los resultados del motor de proceso Dispatch, junto con varias operaciones de copia de texturas en el motor de copia, los consume el motor 3D para la llamada a Draw final.
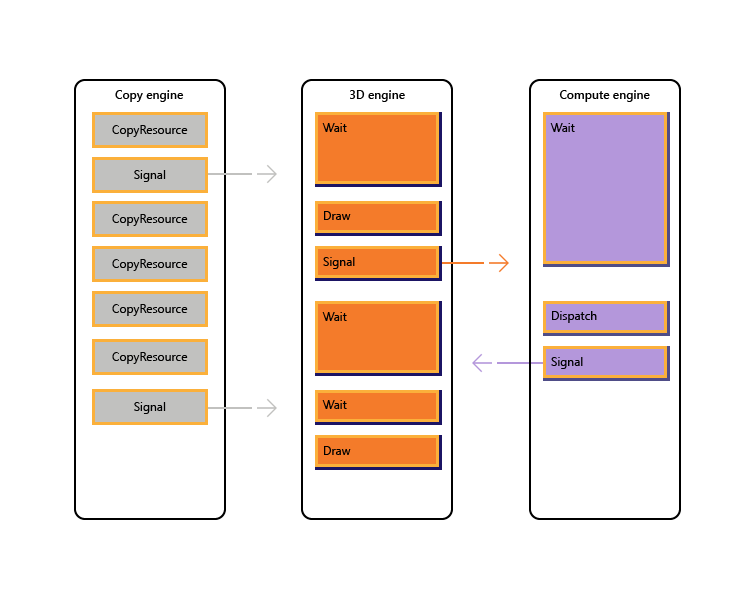
En el pseudocódigo siguiente se muestra cómo un título podría enviar dicha carga de trabajo.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
El siguiente pseudocódigo muestra la sincronización entre los motores de copia y 3D para realizar la asignación de memoria similar al montón a través de un búfer de anillo. Los títulos tienen la flexibilidad de elegir el equilibrio adecuado entre maximizar el paralelismo (a través de un búfer grande) y reducir el consumo y la latencia de memoria (a través de un búfer pequeño).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Escenarios de varios motores
Direct3D 12 permite evitar que se produzcan ineficiencias accidentales causadas por retrasos inesperados en la sincronización. También permite introducir la sincronización en un nivel superior en el que la sincronización necesaria se puede determinar con mayor certeza. Un segundo problema que soluciona varios motores es hacer que las operaciones costosas sean más explícitas, lo que incluye transiciones entre 3D y vídeo que tradicionalmente eran costosas debido a la sincronización entre varios contextos de kernel.
En concreto, se pueden abordar los siguientes escenarios con Direct3D 12.
- Trabajo de GPU asincrónico y de prioridad baja. Esto permite la ejecución simultánea de trabajo de GPU de prioridad baja y operaciones atómicas que permiten que un subproceso de GPU consuma los resultados de otro subproceso sin sincronizar sin bloquear.
- Trabajo de proceso de alta prioridad. Con el proceso en segundo plano, es posible interrumpir la representación 3D para realizar una pequeña cantidad de trabajo de proceso de alta prioridad. Los resultados de este trabajo se pueden obtener pronto para el procesamiento adicional en la CPU.
- Trabajo de proceso en segundo plano. Una cola de prioridad baja independiente para cargas de trabajo de proceso permite a una aplicación usar ciclos de GPU de reserva para realizar cálculos en segundo plano sin afectar negativamente a las tareas de representación principal (u otras). Las tareas en segundo plano pueden incluir la descompresión de recursos o la actualización de simulaciones o estructuras de aceleración. Las tareas en segundo plano deben sincronizarse en la CPU con poca frecuencia (aproximadamente una vez por fotograma) para evitar que se detenga o se ralentice el trabajo en primer plano.
- Streaming y carga de datos. Una cola de copia independiente reemplaza los conceptos D3D11 de los datos iniciales y la actualización de los recursos. Aunque la aplicación es responsable de más detalles en el modelo direct3D 12, esta responsabilidad viene con potencia. La aplicación puede controlar la cantidad de memoria del sistema dedicada a almacenar en búfer los datos de carga. La aplicación puede elegir cuándo y cómo (CPU frente a GPU, bloqueo frente a no bloqueo) para sincronizar, y puede realizar un seguimiento del progreso y controlar la cantidad de trabajo en cola.
- Mayor paralelismo. Las aplicaciones pueden usar colas más profundas para cargas de trabajo en segundo plano (por ejemplo, descodificación de vídeo) cuando tienen colas independientes para el trabajo en primer plano.
En Direct3D 12, el concepto de una cola de comandos es la representación de la API de una secuencia de trabajo aproximadamente serie enviada por la aplicación. Las barreras y otras técnicas permiten que este trabajo se ejecute en una canalización o fuera de orden, pero la aplicación solo ve una sola escala de tiempo de finalización. Esto corresponde al contexto inmediato de D3D11.
API de sincronización
Dispositivos y colas
El dispositivo Direct3D 12 tiene métodos para crear y recuperar colas de comandos de diferentes tipos y prioridades. La mayoría de las aplicaciones deben usar las colas de comandos predeterminadas porque permiten el uso compartido por parte de otros componentes. Las aplicaciones con requisitos de simultaneidad adicionales pueden crear colas adicionales. Las colas se especifican mediante el tipo de lista de comandos que consumen.
Consulte los siguientes métodos de creación de ID3D12Device.
- CreateCommandQueue : crea una cola de comandos basada en la información de una estructura de 12_COMMAND_QUEUE_DESC direct3D .
- CreateCommandList : crea una lista de comandos de tipo Direct3D 12_COMMAND_LIST_TYPE.
- CreateFence : crea una barrera, anotando las marcas en direct3D 12_FENCE_FLAGS. Las barreras se usan para sincronizar colas.
Las colas de todos los tipos (3D, proceso y copia) comparten la misma interfaz y se basan en todas las listas de comandos.
Consulte los métodos siguientes de ID3D12CommandQueue.
- ExecuteCommandLists : envía una matriz de listas de comandos para su ejecución. Cada lista de comandos definida por ID3D12CommandList.
- Señal : establece un valor de barrera cuando la cola (que se ejecuta en la GPU) alcanza un punto determinado.
- Espera : la cola espera hasta que la barrera especificada alcanza el valor especificado.
Tenga en cuenta que las colas no consumen paquetes y, por lo tanto, este tipo no se puede usar para crear una cola.
Barreras
La API de varios motores proporciona API explícitas para crear y sincronizar mediante barreras. Una barrera es una construcción de sincronización controlada por un valor UINT64. La aplicación establece los valores de barrera. Una operación de señal modifica el valor de barrera y una operación de espera se bloquea hasta que la barrera haya alcanzado el valor solicitado o mayor. Se puede desencadenar un evento cuando una barrera alcanza un valor determinado.
Consulte los métodos de la interfaz ID3D12Fence .
- GetCompletedValue : devuelve el valor actual de la valla.
- SetEventOnCompletion : hace que se active un evento cuando la barrera alcance un valor determinado.
- Señal : establece la barrera en el valor especificado.
Las barreras permiten el acceso de CPU al valor de barrera actual y esperas y señales de CPU.
El método Signal de la interfaz ID3D12Fence actualiza una barrera desde el lado de la CPU. Esta actualización se produce inmediatamente. El método Signal de ID3D12CommandQueue actualiza una barrera desde el lado de la GPU. Esta actualización se produce después de que se hayan completado todas las demás operaciones de la cola de comandos.
Todos los nodos de una configuración de varios motores pueden leer y reaccionar ante cualquier barrera que alcance el valor correcto.
Las aplicaciones establecen sus propios valores de barrera, un buen punto de partida podría aumentar una barrera una vez por fotograma.
Una valla puedeser rewound. Esto significa que el valor de barrera no tiene que incrementarse únicamente. Si una operación signal se pone en cola en dos colas de comandos diferentes, o si dos subprocesos de CPU llaman a Signal en una valla, puede haber una carrera para determinar qué señal finaliza en último lugar y, por lo tanto, qué valor de barrera es el que permanecerá. Si se vuelve a generar una barrera, se compararán las nuevas esperas (incluidas las solicitudes SetEventOnCompletion ) con respecto al nuevo valor de barrera inferior y, por lo tanto, puede que no se satisfagan, incluso si el valor de la barrera ha sido lo suficientemente alto como para satisfacerlos. Si se produce una carrera, entre un valor que satisfará una espera pendiente y un valor inferior que no lo hará, la espera se cumplirá independientemente del valor que permanezca después.
Las API de barrera proporcionan una funcionalidad de sincronización eficaz, pero pueden crear problemas potencialmente difíciles de depurar. Se recomienda que cada valla solo se use para indicar el progreso en una escala de tiempo para evitar las carreras entre señalización.
Listas de comandos de copia y proceso
Los tres tipos de lista de comandos usan la interfaz ID3D12GraphicsCommandList , pero solo se admite un subconjunto de los métodos para copiar y calcular.
Las listas de comandos de copia y proceso pueden usar los métodos siguientes.
Las listas de comandos de proceso también pueden usar los métodos siguientes.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Las listas de comandos de proceso deben establecer un proceso SQL al llamar a SetPipelineState.
No se pueden usar agrupaciones con listas de comandos de proceso o copia o colas.
Ejemplo de proceso y gráficos canalizaciones
En este ejemplo se muestra cómo se puede usar la sincronización de barreras para crear una canalización de trabajo de proceso en una cola (a pComputeQueuela que hace referencia ) que usan los gráficos en la cola pGraphicsQueue. El trabajo de proceso y gráficos se canaliza con la cola de gráficos que consume el resultado del trabajo de proceso de varios fotogramas y se usa un evento de CPU para limitar el trabajo total en cola en general.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Para admitir esta canalización, debe haber un búfer de diferentes copias de ComputeGraphicsLatency+1 los datos que pasan de la cola de proceso a la cola de gráficos. Las listas de comandos deben usar UAV e indirecto para leer y escribir desde la "versión" adecuada de los datos del búfer. La cola de proceso debe esperar hasta que la cola de gráficos haya terminado de leer de los datos de la trama N para poder escribir el marco N+ComputeGraphicsLatency.
Tenga en cuenta que la cantidad de cola de proceso trabajada en relación con la CPU no depende directamente de la cantidad de almacenamiento en búfer necesaria, sin embargo, el trabajo de GPU de puesta en cola más allá de la cantidad de espacio de búfer disponible es menos valioso.
Un mecanismo alternativo para evitar la direccionamiento indirecto sería crear varias listas de comandos correspondientes a cada una de las versiones "cuyo nombre ha cambiado" de los datos. En el ejemplo siguiente se usa esta técnica al extender el ejemplo anterior para permitir que las colas de proceso y gráficos se ejecuten de forma más asincrónica.
Ejemplo de proceso y gráficos asincrónicos
En este ejemplo siguiente se permiten que los gráficos se represente de forma asincrónica desde la cola de proceso. Todavía hay una cantidad fija de datos almacenados en búfer entre las dos fases, pero ahora el trabajo de gráficos continúa de forma independiente y usa el resultado más actualizado de la fase de proceso, como se conoce en la CPU cuando se pone en cola el trabajo de gráficos. Esto sería útil si otro origen actualizaba el trabajo de gráficos, por ejemplo, la entrada del usuario. Debe haber varias listas de comandos para permitir que los ComputeGraphicsLatency fotogramas de trabajo de gráficos estén en curso a la vez, y la función UpdateGraphicsCommandList representa la actualización de la lista de comandos para incluir los datos de entrada más recientes y leer de los datos de proceso del búfer adecuado.
La cola de proceso todavía debe esperar a que la cola de gráficos finalice con los búferes de canalización, pero se introduce una tercera barrera (pGraphicsComputeFence) para que se pueda realizar un seguimiento del progreso del proceso de lectura de gráficos frente al progreso de los gráficos en general. Esto refleja el hecho de que ahora los fotogramas gráficos consecutivos podrían leer del mismo resultado de proceso o podrían omitir un resultado de proceso. Un diseño más eficaz pero ligeramente más complicado usaría solo la barrera de gráficos único y almacenaría una asignación a los fotogramas de proceso usados por cada fotograma gráfico.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Acceso a recursos de varias colas
Para acceder a un recurso en más de una cola, una aplicación debe cumplir las reglas siguientes.
El acceso a recursos (consulte direct3D 12_RESOURCE_STATES) viene determinado por la clase de tipo de cola no objeto queue. Hay dos clases de tipo de cola: Compute/3D queue es una clase de tipo, Copy es una segunda clase de tipo. Por lo tanto, un recurso que tiene una barrera para el estado de NON_PIXEL_SHADER_RESOURCE en una cola 3D se puede usar en ese estado en cualquier cola de proceso o 3D, sujeto a los requisitos de sincronización que requieren que la mayoría de las escrituras se serialicen. Los estados de recurso que se comparten entre las dos clases de tipo (COPY_SOURCE y COPY_DEST) se consideran estados diferentes para cada clase de tipo. Por lo tanto, si un recurso pasa a COPY_DEST en una cola de copia, no es accesible como destino de copia desde colas 3D o Compute y viceversa.
Para resumir.
- Una cola "object" es cualquier cola única.
- Una cola "type" es cualquiera de estas tres: Compute, 3D y Copy.
- Una cola "clase de tipo" es cualquiera de estas dos: Compute/3D y Copy.
Las marcas COPY (COPY_DEST y COPY_SOURCE) usadas como estados iniciales representan los estados de la clase de tipo 3D/Compute. Para usar un recurso inicialmente en una cola de copia, debe iniciarse en el estado COMMON. El estado COMMON se puede usar para todos los usos de una cola de copia mediante las transiciones de estado implícitas.
Aunque el estado de recurso se comparte en todas las colas de Proceso y 3D, no se permite escribir en el recurso simultáneamente en distintas colas. "Simultáneamente" aquí significa que no se ha sincronizado, observar que la ejecución no asincrónica no es posible en algún hardware. Se aplican las reglas siguientes.
- Solo una cola puede escribir en un recurso cada vez.
- Varias colas pueden leer desde el recurso siempre y cuando no lean los bytes modificados por el escritor (leer bytes que se escriben simultáneamente generan resultados indefinidos).
- Se debe usar una barrera para sincronizarse después de escribir antes de que otra cola pueda leer los bytes escritos o realizar cualquier acceso de escritura.
Los búferes de reserva que se presentan deben estar en estado de 12_RESOURCE_STATE_COMMON direct3D.
Temas relacionados
Guía de programación de Direct3D 12
Uso de barreras de recursos para sincronizar estados de recursos en Direct3D 12