Identificación de información confidencial y clasificada de seguridad para el cumplimiento del gobierno australiano con PSPF
En este artículo se proporcionan instrucciones para las organizaciones gubernamentales australianas sobre el uso de Microsoft Purview para identificar información confidencial y clasificada de seguridad. Su propósito es ayudar a esas organizaciones a fortalecer su enfoque en cuanto a la seguridad de los datos y su capacidad de cumplir los requisitos descritos en el Marco de directivas de seguridad de protección (PSPF) y el Manual de seguridad de la información (ISM).
La clave para proteger la información y protegerla de la pérdida de datos es comprender primero qué es la información. En este artículo se exploran los métodos de identificación de información en un entorno de Microsoft 365 de organizaciones. A menudo, estos enfoques se conocen como conocer los aspectos de datos de Microsoft Purview. Una vez identificada, la información se puede proteger a través del etiquetado automático de confidencialidad y la prevención de pérdida de datos (DLP).
Tipos de información confidencial
Los tipos de información confidencial (SIT) son clasificadores basados en patrones. Detectan información confidencial a través de expresiones regulares (RegEx) o palabras clave.
Hay muchos tipos diferentes de SIT que son relevantes para las organizaciones gubernamentales australianas:
- SITS precompilado creado por Microsoft, varios de los cuales se alinean con los tipos de datos comunes de Australia.
- Los SIT personalizados se crean en función de los requisitos de la organización.
- Los SIT de entidad con nombre incluyen identificadores complejos basados en diccionarios, como direcciones físicas australianas.
- Los SIT de coincidencia exacta de datos (EDM) se generan en función de la información confidencial real.
- Los SIT de huellas digitales de documentos se basan en el formato de los documentos en lugar de en su contenido.
- Los SIT pertinentes para la seguridad de la red o la información , aunque técnicamente precompilados, tienen una relevancia especial para los equipos cibernéticos que trabajan para organizaciones gubernamentales australianas, por lo que son dignos de su propia categoría.
Tipos de información confidencial creados previamente
Los tipos de información confidencial creados previamente se basan en tipos comunes de información que los clientes suelen considerar confidenciales. Pueden ser genéricos y tener relevancia global (por ejemplo, números de tarjeta de crédito) o tener relevancia local (por ejemplo, números de cuenta bancaria australiana).
La lista completa de SIT precompilados de Microsoft se puede encontrar en definiciones de entidades de tipo de información confidencial
Los SIT específicos de Australia incluyen:
- Número de cuenta bancaria australiana
- Número de licencia de conducir de Australia
- Número de pasaporte australiano
- Direcciones físicas australianas
- Número de archivo de impuestos de Australia
- Número de negocio de Australia
- Número de empresa australiana
- Número de cuenta médica australiana
Estos SIT se pueden encontrar en el portal de clasificación de datos de Microsoft Purview en Clasificadores> Tiposde información confidencial.
Los SIT precompilados son valiosos para las organizaciones que inician su Information Protection o recorrido de gobernanza, ya que proporcionan un punto de partida para habilitar funcionalidades como DLP y etiquetado automático. Las dos maneras más sencillas de usar estos SIT son:
Uso de SIT precompilados a través de plantillas de directiva DLP
Algunos SIT precompilados se incluyen en las plantillas de directiva DLP creadas por Microsoft que se alinean con las regulaciones australianas. Las siguientes plantillas de directiva DLP que se alinean con los requisitos de Australia están disponibles para su uso:
- Ley de privacidad de Australia mejorada
- Datos financieros de Australia
- Estándar de seguridad de datos PCI (PCI DSS)
- Datos de identificación personal (PII) de Australia
La habilitación de directivas DLP basadas en estas plantillas permite la supervisión inicial de eventos de pérdida de datos, que constituyen un excelente punto de partida para las organizaciones que presentan DLP de Microsoft 365. Una vez implementadas, estas directivas proporcionan información sobre la extensión de un problema de pérdida de datos de las organizaciones y pueden ayudar a tomar decisiones sobre los pasos siguientes.
El uso de estas plantillas de directiva se explora aún más en la limitación de la distribución de información confidencial.
Uso de SIT precompilados en el etiquetado automático de confidencialidad
Si se detecta que un artículo contiene un número de cuenta médica australiana, uno o varios términos médicos y un nombre completo, podría ser justo suponer que el artículo contiene información médica de identificación personal y podría constituir un registro médico. En función de esta suposición, podemos sugerir a un usuario que el elemento se etiquete como "OFICIAL: Privacidad personal confidencial", o cualquier etiqueta que sea más adecuada en su organización para la identificación y protección de los registros de estado.
Para obtener más información sobre dónde esta característica puede ayudar a las organizaciones gubernamentales a cumplir con el cumplimiento de PSPF, consulte aplicación automática de etiquetas de confidencialidad y escenarios de etiquetado automático basado en cliente para el Gobierno de Australia.
Tipos de información confidencial personalizados
Además de los SIT precompilados, las organizaciones pueden crear SIT en función de sus propias definiciones de información confidencial. Algunos ejemplos de información relevante para las organizaciones gubernamentales australianas que podrían identificarse a través de SIT personalizada son:
- Marcas de protección
- Id. de despacho o id. de aplicación de despacho
- Clasificaciones de otros estados o territorios
- Clasificaciones que no deben aparecer en la plataforma (por ejemplo, TOP SECRET)
- Reuniones informativas o correspondencia de los ministros
- Número de solicitud de libertad de información (FOI)
- Información relacionada con la probidad
- Términos relacionados con sistemas confidenciales, proyectos o aplicaciones
- Marcas de párrafo
- Números de registro de recorte o objetivo
Los SIT personalizados se componen de un identificador principal, que puede basarse en una expresión regular o palabras clave, el nivel de confianza y los elementos auxiliares opcionales.
Para obtener una explicación más detallada de los SIT y sus componentes, consulte Información sobre los tipos de información confidencial.
Expresiones regulares (RegEx)
Las expresiones regulares son identificadores basados en código que se pueden usar para identificar patrones de información. Por ejemplo, si un número de Libertad de información (FOI) se compone de las letras FOI seguidas de un año de cuatro dígitos, un guion y otros tres dígitos (por ejemplo, FOI2023-123), se podría representar en una expresión regular de:
[Ff][Oo][Ii]20[01234]\d{1}-\d{3}
Para explicar esta expresión:
-
[Ff][Oo][Ii]coincide con las letras F, O e I de mayúsculas o minúsculas. -
20coincide con el número 20 como la primera mitad del año de cuatro dígitos. -
[0123]coincide con 0, 1, 2 o 3 en el tercer dígito de nuestro valor de año de cuatro dígitos, lo que nos permite hacer coincidir los números foi desde el año 2000 hasta el 2039. -
-coincide con un guion. -
\d{3}coincide con tres dígitos cualquiera.
Sugerencia
Copilot es bastante experto en generar expresiones regulares (RegEx). Puede usar el lenguaje natural para pedir a Copilot que genere RegEx automáticamente.
Lista de palabras clave o un diccionario de palabras clave
Las listas de palabras clave y los diccionarios constan de palabras, términos o frases que probablemente se incluirán en los elementos que está buscando identificar. La información sobre gabinetes o la solicitud de licitación son términos que podrían ser útiles como palabras clave.
Las palabras clave pueden distinguir mayúsculas de minúsculas o no distinguir entre mayúsculas y minúsculas. El caso puede ser útil para eliminar falsos positivos. Por ejemplo, official es más probable que se use minúsculas en la conversación general, pero en mayúsculas OFFICIAL tiene mayor probabilidad de formar parte de un marcado protector.
Los diccionarios de palabras clave que contienen conjuntos de datos grandes también se pueden cargar mediante formato CSV o TXT . Para obtener más información sobre cómo cargar un diccionario de palabras clave, vea cómo crear un diccionario de palabras clave.
Nivel de confianza
Algunas palabras clave o expresiones regulares pueden proporcionar una coincidencia precisa sin necesidad de refinamiento. Es poco probable que la expresión libertad de información (FOI) incluida en el ejemplo anterior de un valor aparezca en una conversación general y, cuando aparezca en la correspondencia, es probable que coincida con la información pertinente. Sin embargo, si intentamos coincidir con un número de empleado del servicio público australiano, que se representa como ocho dígitos numéricos, es probable que nuestra coincidencia genere numerosos falsos positivos. El nivel de confianza nos permite asignar una probabilidad de que la presencia de la palabra clave o el patrón en un elemento, como un correo electrónico o un documento, sea realmente lo que estamos buscando. Para más información sobre los niveles de confianza, consulte Administración de los niveles de confianza.
Elementos principales y auxiliares
Los SIT personalizados también tienen un concepto de elementos principales y auxiliares. El elemento principal es el patrón clave que queremos detectar en el contenido. Los elementos auxiliares se pueden agregar a una base de datos principal para crear un caso para que la aparición de un valor sea una coincidencia precisa. Por ejemplo, si intentamos hacer coincidir en función de un número de empleado de ocho dígitos numéricos, podríamos usar palabras clave de "número de empleado" o número AGSde gobierno australiano, o base de datos APSED de empleados de servicios públicos de Australia como elemento auxiliar para aumentar la confianza de que la coincidencia es pertinente. Para obtener más información sobre cómo crear elementos principales y auxiliares, consulte Descripción de los elementos.
Proximidad de caracteres
El valor final que normalmente se configuraría en una SIT es la proximidad de caracteres. Esta es la distancia entre los elementos primarios y auxiliares. Si esperamos que la palabra clave AGS esté cerca de nuestro valor numérico de ocho dígitos, configuraremos una proximidad de 10 caracteres. Si no es probable que los elementos principales y auxiliares aparezcan uno junto al otro, establecemos el valor de proximidad para que sea un mayor número de caracteres. Para obtener más información sobre cómo crear proximidad de caracteres, consulte Descripción de la proximidad.
SIT para identificar marcas de protección
Una manera valiosa para que las organizaciones gubernamentales australianas hagan uso de sits personalizados es identificar las marcas protectoras. En una organización de Greenfield, todos los elementos de un entorno tienen una etiqueta de confidencialidad aplicada. Sin embargo, la mayoría de las organizaciones gubernamentales tienen etiquetado heredado que requiere la modernización de Microsoft Purview. Los SIT se usan para identificar y aplicar marcas a:
- Archivos heredados marcados
- Archivos marcados generados por entidades externas
- Email conversaciones iniciadas y marcadas externamente
- Correos electrónicos que han perdido su información de etiqueta (encabezados x)
- Correos electrónicos, que han tenido sus etiquetas degradadas incorrectamente
Cuando se identifica este marcador, se recomienda al usuario la detección y se le proporciona una recomendación de etiqueta. Si aceptan la recomendación, las protecciones basadas en etiquetas se aplican al elemento. Estos conceptos se describen en escenarios de etiquetado automático basados en cliente para el gobierno australiano.
Los SIT basados en clasificación también son útiles en DLP. Algunos ejemplos son:
- Un usuario recibe información e la identifica como confidencial a través de su marcado, pero no quiere reclasificarla, ya que no se traduce en una clasificación PSPF (por ejemplo, "OFFICIAL Sensitive NSW Government"). La construcción de una directiva DLP para proteger la información incluida en función del marcado en lugar de la etiqueta aplicada significa que se puede aplicar una medida de seguridad de datos.
- Un usuario copia texto de una conversación de correo electrónico, que incluye un marcado de protección. Pegan la información en un chat de Teams con un participante externo que no debería tener acceso a la información. A través de una directiva DLP que se aplica al servicio Teams, se puede detectar el marcado y evitar la divulgación.
- Un usuario degrada incorrectamente una etiqueta de confidencialidad en una conversación de correo electrónico (ya sea de forma malintencionada o por error del usuario). Como las marcas de protección se aplicaron al correo electrónico anteriormente son visibles en el cuerpo del correo electrónico, Microsoft Purview detecta que las marcas actuales y anteriores están mal alineadas. En función de la configuración, la acción registra el evento, avisa al usuario o bloquea el correo electrónico.
- Se envía un correo electrónico marcado a un destinatario externo que está haciendo uso de una plataforma de correo electrónico o cliente no empresarial. La plataforma o el cliente quita los metadatos del correo electrónico (encabezados x), lo que hace que el correo electrónico de respuesta del destinatario externo no tenga una etiqueta de confidencialidad aplicada cuando llega al buzón de usuario de la organización. La detección del marcado anterior a través de una SIT permite volver a aplicar la etiqueta de forma transparente o recomienda que el usuario vuelva a aplicar la etiqueta en su siguiente respuesta.
En cada uno de estos escenarios, los SIT basados en clasificación se podrían usar para detectar marcas de protección aplicadas y mitigar la posible vulneración de datos.
Sintaxis sit de ejemplo para detectar marcas de protección
Las siguientes expresiones regulares se pueden usar en SIT personalizados para identificar marcas de protección.
Importante
La creación de SIT para identificar marcas protectoras ayuda en el cumplimiento de PSPF. Los SIT basados en clasificación también se usan en escenarios de DLP y etiquetado automático.
| Nombre de SIT | Expresión regular |
|---|---|
| Regexno oficial 1 | UNOFFICIAL |
| OFFICIAL Regex1,2 | (?<!UN)OFFICIAL |
| Official Sensitive Regex1,3,4,5 | OFFICIAL[:- ]\s?Sensitive(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET) |
| OFFICIAL Sensitive Personal Privacy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| Official Sensitive Legal Privilege Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| OFICIAL Confidencial Secreto Legislativo Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| GABINETE NACIONAL CONFIDENCIAL OFICIAL Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| REGEXPROTEGIDO 1,3,5 | PROTECTED(?!,\sACCESS=)(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET)(?!(?:\s\|\/\/\|\s\/\/\s)CABINET) |
| PROTECTED Personal Privacy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| Regex1,5 de privilegios legales protegidos | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| REGEX1,5 DE SECRETO LEGISLATIVO PROTEGIDO | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| GABINETE NACIONAL PROTEGIDO Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| ARMARIO PROTEGIDO Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)CABINET |
Al evaluar los ejemplos anteriores de SIT, tenga en cuenta la siguiente lógica de expresión:
- 1 Estas expresiones coinciden con las marcas aplicadas a ambos documentos (por ejemplo, OFFICIAL: Sensitive NATIONAL CABINET) y correo electrónico (por ejemplo, "[SEC=OFFICIAL:Sensitive, CAVEAT=NATIONAL-CABINET]").
-
2 El aspecto negativo de OFFICIAL Regex (
(?<!UN)) impide que los elementos NO OFICIALES coincidan como OFICIALES. -
3Official Sensitive Regex and PROTECTED Regex use lookaheads negativos (
(?!)) para asegurarse de que los marcadores de administración de información (IMM) o advertencia no se apliquen después de la clasificación de seguridad. Esto ayuda a evitar que los elementos con IMM o advertencias se identifiquen como la versión no IMM o advertencia de la clasificación. -
4 El uso de
[:\- ]en OFFICIAL: Sensitive está pensado para permitir la flexibilidad en el formato de esta marca y es importante debido al uso de caracteres de dos puntos en encabezados X. -
5
(?:\s\|\/\/\|\s\/\/\s)se usa para identificar el espacio entre los componentes de marcado y permite un solo espacio, espacio doble, barra diagonal doble o barra diagonal doble con espacios. Esto está pensado para permitir las diferentes interpretaciones del formato de marcado PSPF que existe entre las organizaciones gubernamentales australianas.
Tipos de información confidencial de entidades con nombre
Los SIT de entidad con nombre son identificadores complejos basados en patrones y diccionarios creados por Microsoft, que se pueden usar para detectar información como:
- nombres de Personas
- Direcciones físicas
- Términos y condiciones médicos
Los SIT de entidad con nombre se pueden usar de forma aislada, pero también pueden ser útiles como elementos auxiliares. Por ejemplo, un término médico existente dentro de un correo electrónico puede no ser útil como una indicación de que el elemento contiene información confidencial. Sin embargo, un término médico cuando se empareja con un valor que podría indicar un número de cliente o paciente y un nombre y un nombre de familia, proporcionaría una fuerte indicación de que el elemento es confidencial.
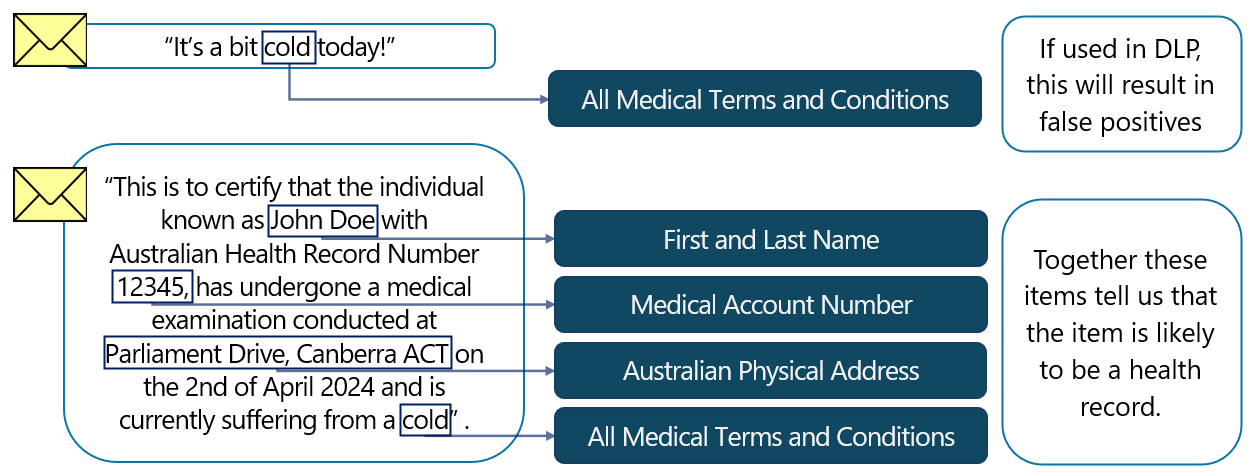
Los SIT de entidad con nombre se pueden emparejar con SIT personalizados, usarse como elementos auxiliares o incluso incluirlos con otros SIT en las directivas DLP.
Para obtener más información sobre los SIT de entidad con nombre, consulte información sobre las entidades con nombre.
Coincidencia exacta de datos con tipos de información confidencial
Los SIT de coincidencia exacta de datos (EDM) se generan en función de los datos reales. Los valores numéricos, como los identificadores numéricos de cliente, son difíciles de coincidir a través de SIT estándar debido a conflictos con otros valores numéricos, como números de teléfono. Los elementos auxiliares mejoran la coincidencia y reducen los falsos positivos.
Exact Data Match ayuda a las organizaciones gubernamentales australianas que tienen sistemas, que contienen datos relacionados con empleados, clientes o ciudadanos para identificar con precisión esta información.
Para obtener más información para implementar SIT de EDM, consulte información sobre los tipos de información confidencial basados en coincidencias de datos exactas.
Creación de huella digital de documento
La huella digital de documentos es una técnica de identificación de información que, en lugar de buscar valores contenidos en un elemento, examina en su lugar el formato y la estructura del elemento. Básicamente, esto nos permite convertir un formulario estándar en un tipo de información confidencial que se puede usar para identificar información.
Las organizaciones gubernamentales pueden usar el método de identificación de contenido con huella digital de documentos para identificar los elementos que se han generado a través de un flujo de trabajo o formularios enviados por otras organizaciones o miembros del público.
Para obtener información sobre la implementación de huellas digitales de documentos, consulte huella digital de documentos.
Tipos de información confidencial relacionados con la red o la seguridad
Hay numerosos usos para SIT más allá de la identificación de información confidencial o clasificada de seguridad. Uno de estos usos es la detección de credenciales. Los SIT precompilados se proporcionan para los siguientes tipos de credenciales:
- Credenciales de inicio de sesión de usuario
- Microsoft Entra ID tokens de acceso de cliente
- Azure Batch claves de acceso compartido
- Firmas de acceso compartido de la cuenta de Azure Storage
- Claves de API o secreto de cliente
Estos SIT precompilados se usan de forma independiente y también se agrupan en una SIT denominada Todas las credenciales.Todas las credenciales SIT son útiles para los equipos cibernéticos que la usan en:
- Directivas DLP para identificar y evitar el movimiento lateral por parte de usuarios malintencionados o atacantes externos.
- Directivas de etiquetado automático para aplicar cifrado a elementos que no deben contener credenciales, bloquear a los usuarios fuera de los archivos y permitir que comiencen las acciones de corrección.
- Directivas DLP para evitar que los usuarios compartan sus credenciales con otros usuarios en las directivas de la organización.
- Para resaltar los elementos almacenados en ubicaciones de SharePoint o Exchange, que retienen inapropiadamente la información de credenciales.
Los SIT precompilados también existen para las direcciones de red (IPv4 e IPv6) y son útiles para proteger elementos que contienen información de red o impedir que los usuarios compartan direcciones IP por correo electrónico, chat de Teams o mensajes de canal.
Clasificadores capacitados
Los clasificadores que se pueden entrenar son modelos de aprendizaje automático que se pueden entrenar para reconocer información confidencial. Al igual que con los SIT, Microsoft proporciona clasificadores previamente entrenados. En la tabla siguiente se muestra un extracto de clasificadores previamente entrenados que son pertinentes para las organizaciones gubernamentales australianas:
| Categoría clasificador | Clasificadores entrenables de ejemplo |
|---|---|
| Financiera | Extractos bancarios, presupuesto, informes de auditoría financiera, estados financieros, impuestos, estados de cuentas, Estimaciones presupuestarias (BE), Declaración de actividad empresarial (BAS). |
| Business | Procedimientos operativos, acuerdos de no divulgación, adquisiciones, palabras de código de proyecto, Estimaciones del Senado (SE), Preguntas sobre aviso (QoNs). |
| Recursos humanos | Reanudaciones, expedientes de acción disciplinaria de empleados, contrato de empleo, autorizaciones de la Agencia australiana de investigación de seguridad (AGSVA), programa de préstamos de educación superior (HELP), identificación militar, autorización de trabajo extranjero (FWA). |
| Médica | Salud, formularios médicos, MyHealth Record. |
| Legal | Asuntos legales, contratos, contratos de licencia. |
| Técnico | Archivos de desarrollo de software, documentos de proyecto, archivos de diseño de red. |
| Comportamiento | lenguaje ofensivo, blasfemia, amenaza, acoso dirigido, discriminación, connivencia normativa, queja del cliente. |
Algunos ejemplos de cómo las organizaciones gubernamentales podrían usar estos clasificadores precompilados incluyen:
- Las reglas de negocios pueden dictar que algunos elementos de la categoría de RR. HH., como los reanudados, deben marcarse como "OFICIAL: Privacidad personal confidencial" debido a que contienen información personal confidencial. Para estos elementos, se podría configurar una recomendación de etiqueta mediante el etiquetado automático basado en cliente.
- Los archivos de diseño de red, especialmente para redes seguras, deben tratarse cuidadosamente para evitar riesgos. Estas podrían ser dignas de una etiqueta PROTEGIDA o, al menos, directivas DLP que impiden la divulgación no autorizada a usuarios no autorizados.
- Los clasificadores de comportamiento son interesantes y, aunque es posible que no tengan una correlación directa con las marcas protectoras o los requisitos dlp, todavía pueden tener un alto valor empresarial. Por ejemplo, se podría notificar a los equipos de RR. HH. las repeticiones de acoso o proporcionar la capacidad de mostrar la correspondencia marcada a través del cumplimiento de comunicaciones.
Las organizaciones también pueden entrenar sus propios clasificadores. Los clasificadores se pueden entrenar proporcionándoles conjuntos de muestras positivas y negativas. El clasificador procesa los ejemplos y compila un modelo de predicción. Una vez completado el entrenamiento, se pueden usar clasificadores para la aplicación de etiquetas de confidencialidad, directivas de cumplimiento de comunicaciones y directivas de etiquetado de retención. El uso de clasificadores en directivas DLP está disponible en versión preliminar.
Para obtener más información sobre los clasificadores que se pueden entrenar, consulte Más información sobre los clasificadores que se pueden entrenar.
Uso de información confidencial identificada
Una vez que la información se identifica a través de SIT o clasificador (a través del conocimiento de los aspectos de datos de Microsoft Purview), podemos usar este conocimiento para ayudarnos a completar los otros tres pilares de la administración de información de Microsoft 365, a saber:
- Proteja sus datos,
- Evitar la pérdida de datos y
- Gobierno de datos
En la tabla siguiente se proporcionan ventajas y ejemplos de cómo el conocimiento de un elemento que contiene información confidencial podría ayudar con la administración de la información en la plataforma de Microsoft 365:
| Funcionalidad | Ejemplo de uso |
|---|---|
| Prevención de pérdida de datos | Ayuda a la administración al reducir los riesgos de derrame de datos. |
| Etiquetado de confidencialidad | Recomienda aplicar la etiqueta de confidencialidad adecuada. Una vez etiquetadas, las protecciones relacionadas con la etiqueta se aplican a la información. |
| Etiquetado de retención | Aplica automáticamente una etiqueta de retención, lo que permite cumplir los requisitos de administración de archivos o registros. |
| Explorador de contenido | Vea dónde residen los elementos que contienen información confidencial en los servicios de Microsoft 365, incluidos SharePoint, Teams, OneDrive y Exchange. |
| Administración de riesgos de Insider | Supervise la actividad del usuario en torno a la información confidencial, establezca un nivel de riesgo de usuario en función del comportamiento y escale el comportamiento sospechoso a los equipos pertinentes. |
| Cumplimiento de la comunicación | Correspondencia de alto riesgo de pantalla, incluido cualquier chat o correo electrónico que contenga contenido confidencial o sospechoso. El cumplimiento de las comunicaciones puede ayudar a garantizar que el Gobierno australiano cumpla las obligaciones de probidad. |
| Microsoft Priva | Detecte el almacenamiento de información confidencial, incluidos los datos personales en ubicaciones como OneDrive, y guíe a los usuarios sobre el almacenamiento correcto de información. |
| eDiscovery | Muestre información confidencial como parte de los procesos de RR. HH. o FOI y aplique retenciones a información que podría formar parte de una solicitud o investigación activa. |
Explorador de contenido
El explorador de contenido de Microsoft 365 permite a los responsables de cumplimiento, seguridad y privacidad obtener una información rápida pero completa sobre dónde reside la información confidencial en un entorno de Microsoft 365. Esta herramienta permite a los usuarios autorizados examinar ubicaciones y elementos por tipo de información. El servicio indexa y expone los elementos que residen en Exchange, OneDrive y SharePoint. Los elementos ubicados en los sitios de equipo subyacentes de SharePoint de Teams también están visibles.
A través de esta herramienta podemos seleccionar un tipo de información confidencial o una etiqueta de confidencialidad, ver el número de elementos que se alinean con él en cada uno de los servicios de Microsoft 365:
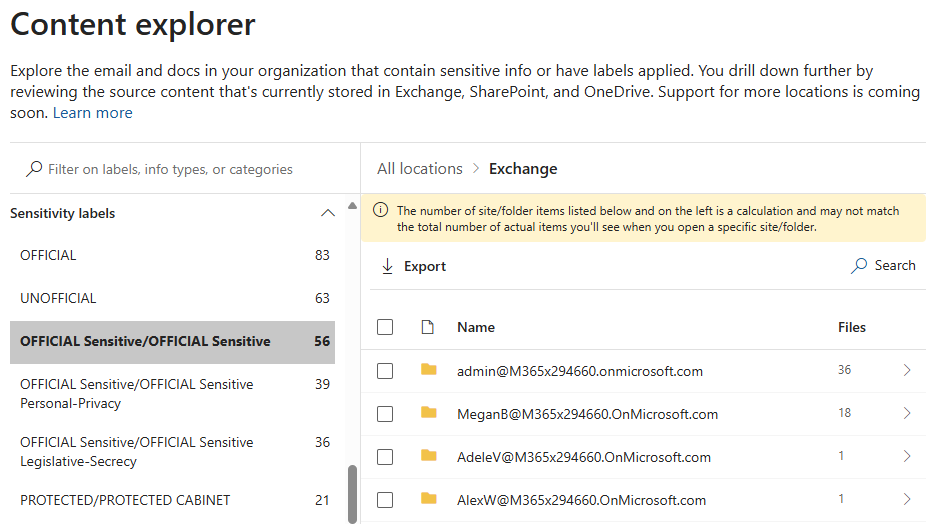
El explorador de contenido puede proporcionar información valiosa sobre las ubicaciones en las que residen elementos confidenciales o clasificados de seguridad en un entorno. Es poco probable que esta visión consolidada de la ubicación de la información sea posible a través de sistemas locales.
Para las organizaciones que incluyen etiquetas que no se permiten dentro de la cuenta de la organización (por ejemplo, SECRET o TOP SECRET) junto con directivas de etiquetado automático asociadas para aplicar las etiquetas, el explorador de contenido puede encontrar información que no se debe almacenar en la plataforma. Como el explorador de contenido también puede exponer SIT, se podría lograr un enfoque similar a través de SIT para identificar marcas de protección.
Para obtener más información sobre el Explorador de contenido, consulte Introducción al explorador de contenido.