Native GPU fence object
This article describes the GPU fence synchronization object that can be used for true GPU-to-GPU synchronization in GPU hardware scheduling stage 2. This feature is supported starting in Windows 11, version 24H2 (WDDM 3.2). Graphics driver developers should be familiar with WDDM 2.0 and GPU hardware scheduling stage 1.
WDDM 2.x's monitored fence synchronization object
WDDM 2.x's monitored fence synchronization object supports the following operations:
- The CPU waits on a monitored fence value, either by:
- Polling using a CPU virtual address (VA).
- Queuing a blocking wait inside Dxgkrnl that gets signaled when the CPU observes the new monitored fence value.
- CPU signal of a monitored value.
- GPU signal of a monitored value by writing to the monitored fence GPU VA and raising a monitored fence signaled interrupt to notify the CPU of the value update.
What wasn't supported was a native on-the-GPU wait for a monitored fence value. Instead, the OS held GPU work that depends on the waited value on the CPU. It only released this work to the GPU when the value is signaled.
Added GPU native fence synchronization object
Starting in WDDM 3.2, the monitored fence object was extended to support the following added features:
- GPU wait on a monitored fence value, which allows for high performance engine-to-engine synchronization without requiring a CPU roundtrip.
- Conditional interrupt notification only for GPU fence signals that have CPU waiters. This feature enables substantial power savings by enabling the CPU to enter a low power state when all GPU work is queued.
- Fence value storage in the GPU local memory (as opposed to system memory).
GPU native fence sync object design
The following diagram illustrates the basic architecture of a GPU native fence object, with a focus on the synchronization object state shared between the CPU and the GPU.
:
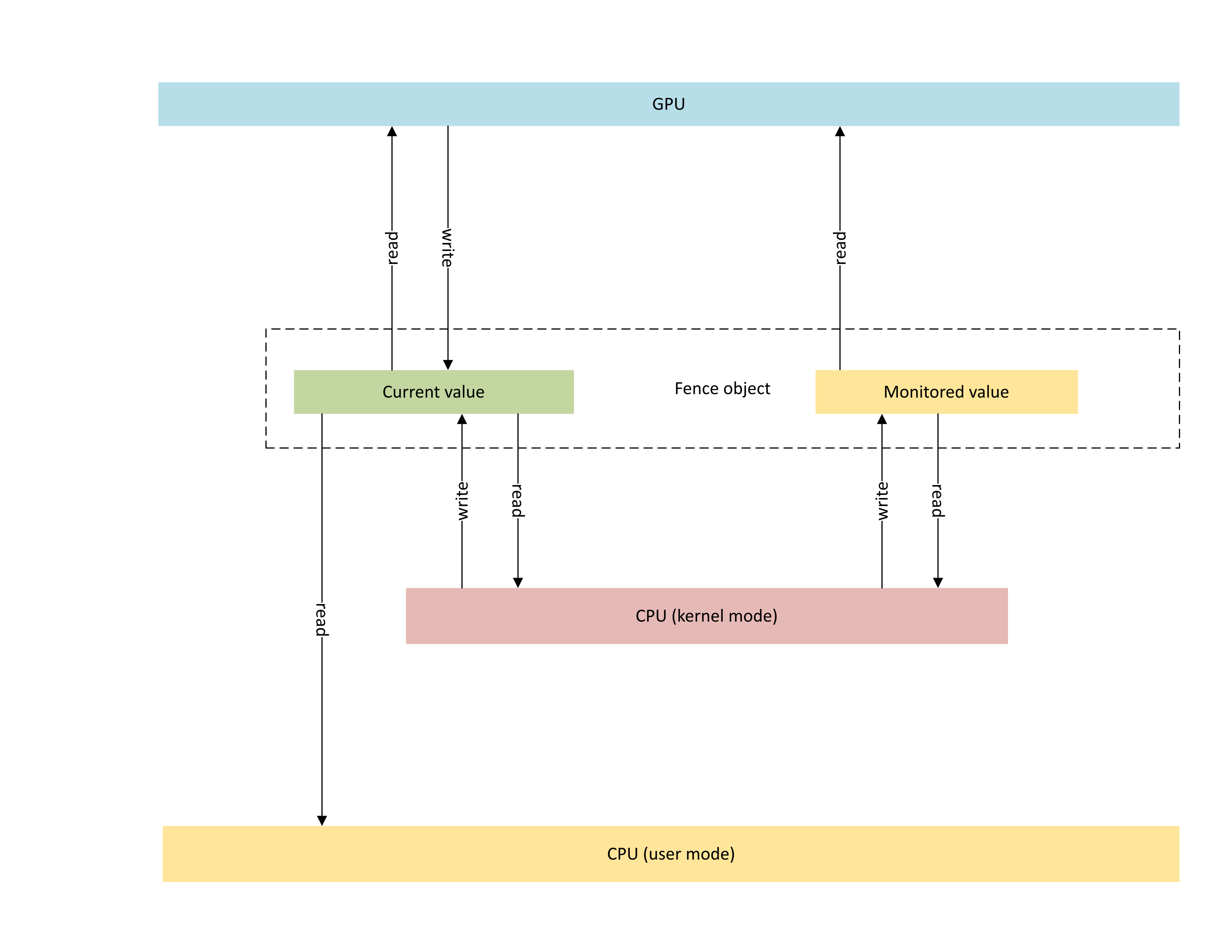
The diagram includes two main components:
Current value (referred to as CurrentValue in this article). This memory location contains the currently signaled 64-bit fence value. CurrentValue is mapped and accessible to both the CPU (writeable from kernel mode, readable from both user and kernel mode) and GPU (readable and writeable using GPU virtual address). CurrentValue requires 64-bit writes to be atomic from both the CPU and the GPU point of view. That is, updates to the high and low 32 bits can't be torn and should be visible at the same time. This concept is already present in the existing monitored fence object.
Monitored value (referred to as MonitoredValue in this article). This memory location contains the least currently waited on value by the CPU subtracted by one (1). MonitoredValue is mapped and accessible to both the CPU (readable and writeable from kernel mode, no user mode access) and GPU (readable using GPU VA, no write access). The OS maintains the list of outstanding CPU waiters for a given fence object, and it updates MonitoredValue as waiters are added and removed. When there are no outstanding waiters, the value is set to UINT64_MAX. This concept is new to the GPU native fence sync object.
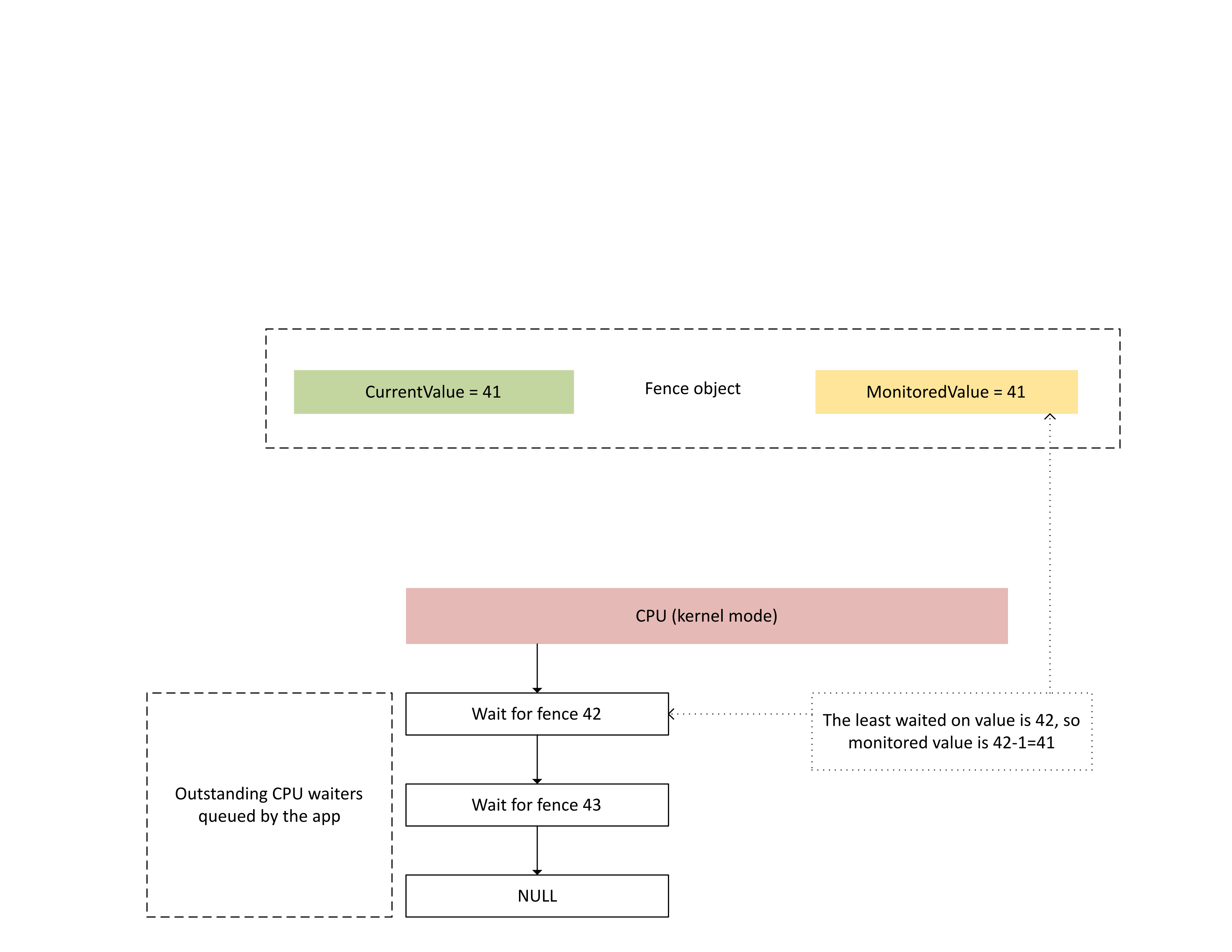
The next diagram illustrates how Dxgkrnl tracks outstanding CPU waiters on a specific monitored fence value. It also shows the set monitored fence value at a given point in time. CurrentValue and MonitoredValue are both 41, which means that:
- The GPU completed all tasks up to the fence value of 41.
- The CPU isn't waiting on any fence value less than or equal to 41.
:
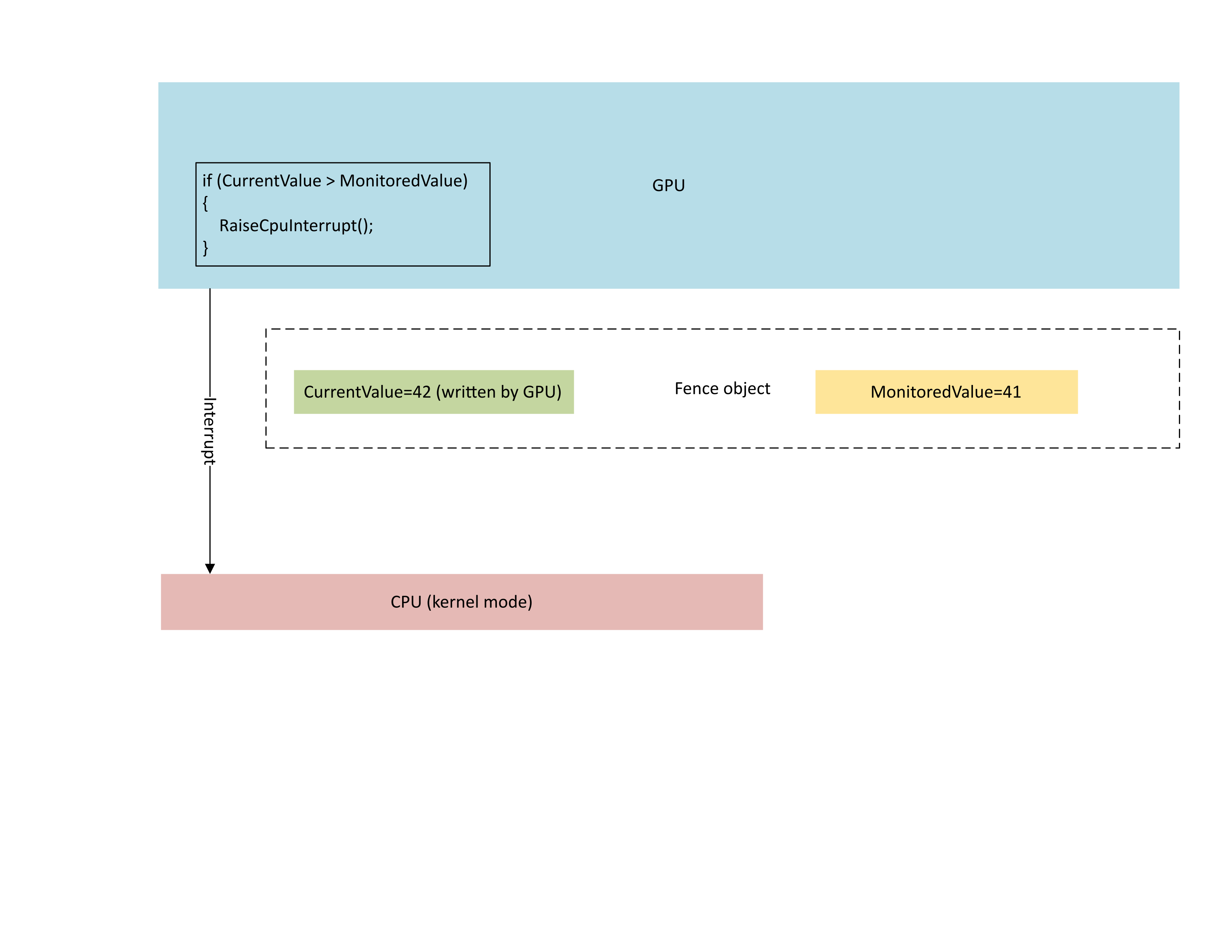
The following diagram illustrates that the GPU's context management processor (CMP) conditionally raises a CPU interrupt only if the new fence value is greater than the monitored value. Such an interrupt means there are outstanding CPU waiters that can be satisfied with the newly written value.
:
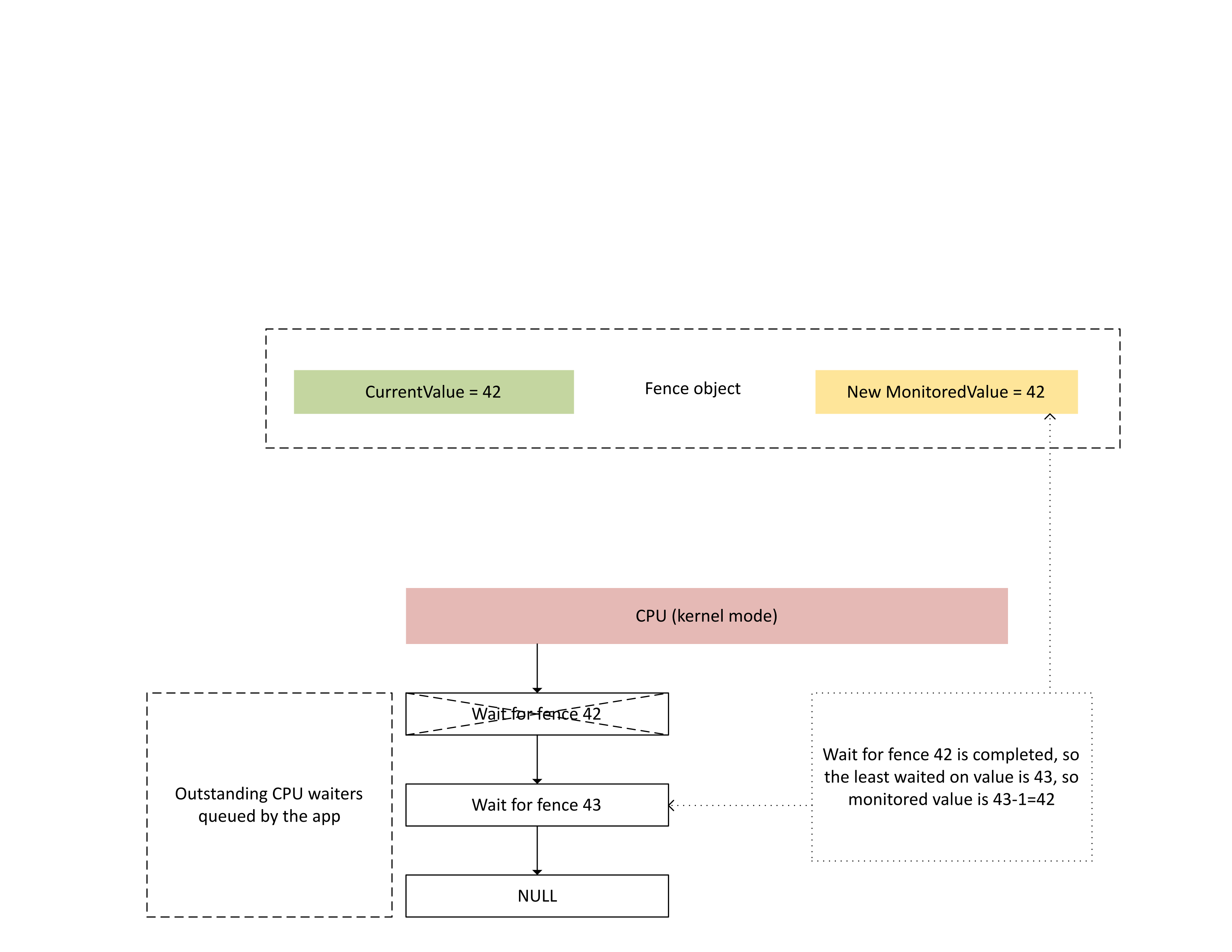
When the CPU processes this interrupt, Dxgkrnl performs the following actions as illustrated in the next diagram:
- It unblocks CPU waiters that have been satisfied with the newly written fence.
- It advances the monitored value to correspond to the least outstanding waited on value subtracted by 1.
:
Physical memory storage for current and monitored fence values
For a given fence object, CurrentValue and MonitoredValue are stored in separate locations.
Fence objects that are nonshareable have fence value storage for different fence objects within the same process packed in the same memory page. The values are packed according to the stride values specified in the native fence KMD caps described later in this article.
Fence objects that are shareable have their current and monitored values placed in memory pages that aren't shared with other fence objects.
Current value
The current value can reside either in system memory or GPU local memory, depending on the fence type specified by D3DDDI_NATIVEFENCE_TYPE.
Current value for cross adapter fences is always in system memory.
When current value is stored in system memory, storage is allocated from internal system memory pool.
When current value is stored in local memory, storage is allocated from memory segments that the driver specified in D3DKMDT_FENCESTORAGESURFACEDATA.
Monitored value
The monitored value can also reside either in system or GPU local memory, depending on D3DDDI_NATIVEFENCE_TYPE.
When monitored value is stored in system memory, the OS allocates storage from internal system memory pool.
When monitored value is stored in local memory, the OS allocates storage from memory segments that the driver specified in D3DKMDT_FENCESTORAGESURFACEDATA.
When the OS's CPU wait conditions change, it calls KMD's DxgkDdiUpdateMonitoredValues callback to instruct KMD to update the monitored value to a specified value.
Synchronization issues
The previously described mechanism has an inherent race condition between the CPU and GPU reads and writes of the current value and the monitored value. If special care isn't taken, the following issues could occur:
- The GPU could read a stale MonitoredValue and not raise an interrupt as expected by the CPU.
- A GPU engine could write a newer CurrentValue while the CMP is in the middle of deciding the interrupt condition. This newer CurrentValue might not raise the interrupt as expected, or might not be visible to the CPU as it fetches the current value.
Synchronization within the GPU between the engine and CMP
For efficiency, many discrete GPUs implement the monitored fence signal semantics using shadow state that resides in the GPU's local memory between:
The GPU engine executing the command buffer stream and conditionally raising a hardware signal to the CMP.
The GPU CMP that decides whether a CPU interrupt should be raised.
In this case, the CMP needs to synchronize memory access with the GPU engine performing the memory write to the fence value. In particular, the operation of updating a shadow MonitoredValue should be ordered from the CMP point of view:
- Write a new MonitoredValue (shadow GPU storage).
- Execute a memory barrier to synchronize memory access with the GPU engine.
- Read CurrentValue:
- If CurrentValue > MonitoredValue, raise a CPU interrupt.
- If CurrentValue <= MonitoredValue, don't raise the CPU interrupt.
For this race condition to resolve properly, it's imperative that the memory barrier in step 2 function properly. There must not be a pending memory write operation to CurrentValue in step 3 that originated from a command that hasn't seen the MonitoredValue update in step 1. This situation would generate an interrupt if the fence written in step 3 was greater than the value updated in step 1.
Synchronization between the GPU and CPU
The CPU has to perform updates of MonitoredValue and reads of CurrentValue in a way that doesn't lose interrupt notification for in-flight signals.
- The OS has to modify MonitoredValue when a new CPU waiter is added to the system, or if an existing CPU waiter is retired.
- The OS calls DxgkDdiUpdateMonitoredValues to notify the GPU of a new monitored value.
- DxgkDdiUpdateMonitoredValue executes at the device interrupt level and is thus synchronized with the monitored fence signaled interrupt service routine (ISR).
- DxgkDdiUpdateMonitoredValue must guarantee that, after it returns, the CurrentValue read by any processor core was written by the GPU CMP after having observed the new MonitoredValue.
- Upon return from DxgkDdiUpdateMonitoredValue, the OS resamples CurrentValue and satisfies any waiters that are unblocked by the new CurrentValue.
It's perfectly acceptable for the CPU to observe a newer CurrentValue than the one used by the GPU to decide whether to raise the interrupt. This situation would occasionally result in an interrupt notification that doesn't unblock any waiters. What isn't acceptable is for the CPU to not receive an interrupt notification for the most recent CurrentValue update that was monitored (that is, CurrentValue > MonitoredValue.)
Querying native fence feature enablement in OS
Drivers must query whether the native fence feature is enabled in the OS during driver initialization.Starting in WDDM 3.2, the OS uses the added IsFeatureEnabled interface to control whether certain features are enabled, including the native fence feature.
As a result, KMD must implement the IsFeatureEnabled interface. KMD's implementation must query whether the OS has enabled the DXGK_FEATURE_NATIVE_FENCE feature before advertising native fence support in DXGK_VIDSCHCAPS. The OS fails adapter initialization if KMD advertises native fence support when the OS hasn't enabled the feature.
For more information about the feature enablement interface, see Querying WDDM feature support and enablement.
DDIs to query native fence feature enablement
The following interfaces are introduced for a KMD to query whether the OS enabled the native fence feature:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
The OS implements the added DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 interface table dedicated to version 1 of DXGK_FEATURE_NATIVE_FENCE. KMD must query this feature interface table to determine the OS's capabilities. In future OS releases, the OS might introduce future versions of this interface table, detailing support for new capabilities.
Sample driver code for querying support
The following sample code shows how drivers are expected to use the DXGK_FEATURE_NATIVE_FENCE feature in the DXGK_FEATURE_INTERFACE interface for querying support.
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
Native fence capabilities
The following interfaces are updated or introduced to query native fence caps:
The NativeGpuFence field is added to DXGK_VIDSCHCAPS. If the OS enabled the DXGK_FEATURE_NATIVE_FENCE feature, the driver can declare support for native GPU fence functionality during adapter initialization by setting the DXGK_VIDSCHCAPS::NativeGpuFence bit to 1.
DXGKQAITYPE_NATIVE_FENCE_CAPS is added to DXGK_QUERYADAPTERINFOTYPE.
Dxgkrnl exposes this feature to user mode via the added corresponding D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported structure/bit.
KMTQAITYPE_WDDM_3_1_CAPS is added to KMTQUERYADAPTERINFOTYPE.
The following entities are added for a KMD to indicate its support capabilities for the native GPU fence feature.
The DXGK_NATIVE_FENCE_CAPS structure describes the GPU's native fence capabilities. When KMD sets this structure's MapToGpuSystemProcess bit, it's instructing the OS to reserve a system process GPU virtual address space for CMP use, and to create GPU VA mappings into that address space for the native fence CurrentValue and MonitoredValue. These GPU VAs are later passed to the KMD's fence creation callback as DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa and MonitoredValueSystemProcessGpuVa.
KMD returns its populated DXGK_NATIVE_FENCE_CAPS structure when its DxgkDdiQueryAdapterInfo function is called with the added DXGKQAITYPE_NATIVE_FENCE_CAPS query adapter info type.
KMD DDIs to create, open, close, and destroy a native fence object
The following KMD-implemented DDIs are introduced to create, open, close, and destroy a native fence object. Dxgkrnl calls these DDIs on behalf of user-mode components. Dxgkrnl calls them only if the OS enabled the DXGK_FEATURE_NATIVE_FENCE feature.
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
The following DDIs were updated to support native fence objects:
The following members were added to DRIVER_INITIALIZATION_DATA. Drivers that support native GPU fence objects should implement the functions and provide Dxgkrnl with pointers to them via this structure.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (added in WDDM 3.1)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (added in WDDM 3.1)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (added in WDDM 3.2)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (added in WDDM 3.2)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (added in WDDM 3.2)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (added in WDDM 3.2)
Global and local handles for shared fences
Imagine process A creates a shared native fence and process B later opens this fence.
When process A creates the shared native fence, Dxgkrnl calls DxgkDdiCreateNativeFence with the adapter driver handle on which this fence is created. The fence handle created and returned in hGlobalNativeFence is the global fence handle.
Dxgkrnl subsequently follows up with a call to DxgkDdiOpenNativeFence to open a process A's specific local handle (hLocalNativeFenceA).
When process B opens the same shared native fence, Dxgkrnl calls DxgkDdiOpenNativeFence to open a process B-specific local handle (hLocalNativeFenceB).
If process A destroys its shared native fence instance, Dxgkrnl sees that there's still a pending reference to this global fence, so only calls DxgkDdiCloseNativeFence(hLocalNativeFenceA) for the driver to clean up process A-specific structures. The hGlobalNativeFence handle still exists.
When process B destroys its fence instance, Dxgkrnl calls DxgkDdiCloseNativeFence(hLocalNativeFenceB) and then DxgkDdiDestroyNativeFence(hGlobalNativeFence) to allow KMD to destroy its global fence data.
GPU VA mappings in paging process address space for CMP use
The KMD sets the DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess cap on hardware that requires native fence GPU VAs to be also mapped into the GPU paging process address space. A set MapToGpuSystemProcess bit instructs the OS to create GPU VA mappings in the paging process address space for the native fence's CurrentValue and MonitoredValue for use by the CMP. These GPU VAs are later passed to DxgkDdiCreateNativeFence as DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa and MonitoredValueSystemProcessGpuVa.
D3DKMT kernel APIs to create, open, and destroy native fences
The following D3DKMT kernel-mode APIs are introduced to create and open a native fence object.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl calls the existing D3DKMTDestroySynchronizationObject function to close and destroy (free) an existing native fence object.
Support structures and enumerations that are introduced or updated include:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
DDI to support placement of native fence values in local memory
The following DDIs were added or changed to support placement of native fence values in local memory:
The D3DKMDT_FENCESTORAGESURFACEDATA structure is added.
The native fence MonitoredValue and CurrentValue of the native fence type D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU can be placed in local device memory. To do so, the OS will ask the driver to specify memory segments in which the fence storage should be placed. DxgkDdiGetStandardAllocation is extended to provide such information.
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE is added to DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA.
Indicating a native progress fence for hardware queues
The following update is introduced to indicate a native hardware queue progress fence object:
A NativeProgressFence flag is added for calls to DxgkDdiCreateHwQueue.
- On supported systems, the OS updates the hardware queue progress fence to a native fence. When the OS sets NativeProgressFence, it indicates to KMD that the DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence handle points to the driver handle of a native GPU fence object previously created using DxgkDdiCreateNativeFence.
Native fence signaled interrupt
The following changes are made to the interrupt mechanism to support a native fence signaled interrupt:
The DXGK_INTERRUPT_TYPE enum is updated to have a DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED interrupt type.
The DXGKARGCB_NOTIFY_INTERRUPT_DATA structure is updated to include a NativeFenceSignaled structure to denote a native fence signaled interrupt
NativeFenceSignaled is used to inform the OS that a set of native fence GPU objects monitored by the CPU were signaled on a GPU engine. If the GPU is able to determine the exact subset of objects with active CPU waiters, it passes this subset via pSignaledNativeFenceArray. The handles in this array must be valid hGlobalNativeFence handles that Dxgkrnl passed to KMD in DxgkDdiCreateNativeFence. Passing a handle to a destroyed native fence object causes a bug check.
The DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS structure is updated to include an EvaluateLegacyMonitoredFences member.
The GPU can pass a NULL pSignaledNativeFenceArray under the following conditions:
- The GPU is unable to determine the exact subset of objects with active CPU waiters.
- Multiple signal interrupts are collapsed together making it hard to determine the signaled set with active waiters.
A NULL value instructs the OS to scan all outstanding native GPU fence object waiters.
The contract between the OS and the driver is: if the OS has an active CPU waiter (as expressed by MonitoredValue), and the GPU engine signaled the object to the value that requires a CPU interrupt, the GPU must take either of the following actions:
- Include this native fence handle in the pSignaledNativeFenceArray.
- Raise a NativeFenceSignaled interrupt with a NULL pSignaledNativeFenceArray.
By default, when KMD raises this interrupt with a NULL pSignaledNativeFenceArray, Dxgkrnl only scans all pending native fence waiters and doesn't scan legacy monitored fence waiters. On hardware that can't distinguish between legacy DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED and DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED, the KMD can always raise only the introduced DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED interrupt with pSignaledNativeFenceArray = NULL and EvaluateLegacyMonitoredFences = 1, which indicates to the OS to scan all waiters (legacy monitored fence waiter & native fence waiters).
Instructing KMD to update batches of values
The following interfaced are introduced to instruct KMD to update a batch of current or monitored values:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
Cross-adapter native fences
The OS must support creating cross-adapter native fences because existing DX12 apps create and use cross-adapter monitored fences. If underlying queues and scheduling for these apps is switched to user-mode submission, then their monitored fences must also be switched to native fences (user-mode queues can't support monitored fences).
A cross-adapter fence must be created with type D3DDDI_NATIVEFENCE_TYPE_DEFAULT. Otherwise, D3DKMTCreateNativeFence fails.
All GPUs share the same copy of CurrentValue storage, which is always allocated in system memory. When the runtime creates a cross-adapter native fence on GPU1 and opens it on GPU2, the GPU VA mappings on both GPUs point to the same CurrentValue physical storage.
Each GPU gets its own copy of MonitoredValue. Hence, MonitoredValue storage can be allocated in system memory or local memory.
Cross-adapter native fences must resolve the condition where GPU1 is waiting on a native fence that GPU2 signaled. Today, there's no concept of GPU-to-GPU signals; hence, the OS explicitly resolves this condition by signaling GPU1 from the CPU. This signaling is done by setting MonitoredValue for the cross-adapter fence to 0 for its lifetime. Then, when GPU2 signals the native fence, it also raises a CPU interrupt, allowing Dxgkrnl to update CurrentValue on GPU1 (using DxgkDdiUpdateCurrentValuesFromCpu with the NotificationOnly flag set TRUE) and unblock any pending CPU/GPU waiters of that GPU.
Although MonitoredValue is always 0 for cross-adapter native fences, wait and signals submitted on the same GPU still benefit from faster on GPU synchronization. However, the power benefit of reduced CPU interrupts is lost because CPU interrupts will be raised unconditionally, even if there were no CPU waiters or waiters on the other GPU. This trade-off is made to keep the design and implementation cost of cross-adapter native fence simple.
The OS supports the scenario where a native fence object is created on GPU1 and opened on GPU2, where GPU1 supports the feature and GPU2 doesn't. The fence object is opened as a regular MonitoredFence on GPU2.
The OS supports the scenario where a regular monitored fence object is created on GPU1 and opened as a native fence on GPU2, which supports the feature. The fence object is opened as a native fence on GPU2.
Cross-adapter wait/signal combinations
The tables in the following subsections take an example of an iGPU and dGPU system, and list the various configurations that are possible for native fence wait/signal from the CPU/GPU. The following two cases are considered:
- Both GPUs support native fences.
- The iGPU doesn't support native fences, but the dGPU does support native fences.
The second scenario is also similar to the case where both GPUs support native fences, but native fence wait/signal is submitted to a kernel-mode queue on the iGPU.
The tables should be read by selecting a pair of wait and signal from the columns, for example WaitFromGPU - SignalFromGPU or WaitFromGPU - SignalFromCPU, et cetera.
Scenario 1
In Scenario 1, both dGPU and iGPU support native fences.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD inserts a wait for hfence CurrentValue == 10 instruction in the command buffer | Runtime calls D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch tracks this sync object in its native fence CPU waiter list | |||
| UMD inserts a write hFence CurrentValue = 10 signal instruction in the command buffer | Runtime calls D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch receives a native fence signaled ISR when CurrentValue is written (because MonitoredValue == 0 always) | VidSch calls DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propagates the signal (hFence, 10) to the iGPU | VidSch propagates the signal (hFence, 10) to iGPU | ||
| VidSch receives the propagated signal and calls DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch receives the propagated signal and calls DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD rescans the run list to unblock HW channel that was waiting on hFence | VidSch unblocks the CPU wait condition by signaling the KEVENT |
Scenario 2a
In Scenario 2a, the iGPU doesn't support native fences but the dGPU does. A wait is submitted on the iGPU and a signal is submitted on the dGPU.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| Runtime calls D3DKMTWaitForSynchronizationObjectFromGpu | Runtime calls D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch tracks this sync object in its monitored fence waiting list | VidSch tracks this sync object in its monitored fence CPU waiter list head | ||
| UMD inserts a write hFence CurrentValue = 10 signal instruction in command buffer | Runtime calls D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch receives NativeFenceSignaledISR when CurrentValue is written (because MV == 0 always) | VidSch calls DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propagates the signal (hFence, 10) to iGPU | VidSch propagates the signal (hFence, 10) to iGPU | ||
| VidSch receives the propagated signal and observes new fence value | VidSch receives the propagated signal and observes new fence value | ||
| VidSch scans its monitored fence waiting list and unblocks software contexts | VidSch scans its monitored fence CPU waiter list head and unblocks CPU wait by signaling the KEVENT |
Scenario 2b
In Scenario 2b, native fence support remains the same (iGPU doesn't support, dGPU does). This time, a signal is submitted on the iGPU and a wait is submitted on the dGPU.
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD inserts a wait for hfence CurrentValue == 10 instruction in command buffer | Runtime calls D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch tracks this sync object in its native fence CPU waiter list | |||
| UMD calls D3DKMTSignalSynchronizationObjectFromGpu | UMD calls D3DKMTSignalSynchronizationObjectFromCpu | ||
| When packet is at the head of the software context, VidSch updates fence value directly from CPU | VidSch updates fence value directly from CPU | ||
| VidSch propagates the signal (hFence, 10) to dGPU | VidSch propagates the signal (hFence, 10) to dGPU | ||
| VidSch receives the propagated signal and calls DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch receives the propagated signal and calls DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD rescans the run list to unblock HW channel that was waiting on hFence | VidSch unblocks the CPU wait condition by signaling the KEVENT |
Future GPU-to-GPU cross-adapter signal
As described in Synchronization issues, for cross-adapter native fences, we lose power savings because a CPU interrupt is raised unconditionally.
In a future release, the OS will develop an infrastructure to allow a GPU signal on one GPU to interrupt other GPUs by writing to a common doorbell memory, allowing other GPUs to wake up, process its run-list and unblock ready HW queues.
The challenge for this work is to design:
- The common doorbell memory.
- An intelligent payload or handle that a GPU can write to the doorbell that allows other GPUs to determine which fence was signaled so that it can only scan a subset of HWQueues.
With such a cross-adapter signal, it might even be possible for GPUs to share the same copy of native fence storage (a linear format cross-adapter allocation, similar to cross-adapter scan out allocations) from which all GPUs read and write to.
Native fence log buffer design
With native fences and user-mode submission, Dxgkrnl doesn't have visibility of when native GPU waits and signals enqueued from UMD are unblocked on the GPU for a particular HWQueue. With native fences, a monitored fence signaled interrupt could be suppressed for a given fence.
:

A way to recreate the fence operations as shown in this GPUView image is needed. The dark pink boxes are signals and light pink boxes are waits. Each box begins when the operation was submitted on the CPU to Dxgkrnl and ends when Dxgkrnl completes the operation on CPU. This way we're able to study the entire lifetime of a command.
So, at a high level, the per HWQueue conditions required to be logged are:
| Condition | Meaning |
|---|---|
| FENCE_WAIT_QUEUED | CPU Timestamp of when the UMD inserts a GPU Wait instruction in the command queue |
| FENCE_SIGNAL_QUEUED | CPU Timestamp of when the UMD inserts a GPU signal instruction in the command queue |
| FENCE_SIGNAL_EXECUTED | GPU timestamp of when a signal command is executed on GPU for a HWQueue |
| FENCE_WAIT_UNBLOCKED | GPU timestamp of when a wait condition is satisfied on GPU and the HWQueue is unblocked |
Native fence log buffer DDIs
The following DDI, structures, and enums are introduced to support native fence log buffers:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- A log buffer that contains a header and array of log entries. The header identifies whether the entries are for a wait or signal, and each entry identifies the type of operation (executed or unblocked):
The log buffer design is meant for native fence and user-mode submission queues where the log buffer payload is written by the GPU engine/CMP, without involvement from Dxgkrnl or KMD. Hence, UMD will insert an instruction while generating the wait/signal command buffer, programming the GPU to write the log buffer payload into the log buffer entry on execution. For non-user-mode submission (that is, kernel-mode queues), the wait and signals are software commands inside Dxgkrnl, so we already know the timestamps and other details of these operations and we don't require hardware/KMD to update the log buffer. For such kernel mode queues, Dxgkrnl won't create a log buffer.
Log buffer mechanism
Dxgkrnl allocates two dedicated 4-KB log buffers per HWQueue.
- One for logging waits.
- One for logging signals.
These log buffers have mappings for the kernel-mode CPU VA (LogBufferCpuVa), a GPU VA in process address space (LogBufferGpuVa), and the CMP VA (LogBufferSystemProcessGpuVa), so that they can are read/write to KMD, the GPU engine, and CMP. Dxgkrnl calls DxgkDdiSetNativeFenceLogBuffer twice: once to set the log buffer for logging waits and once to set the log buffer for logging signals.
Immediately after UMD inserts a native fence wait or signal instruction in the command list, it also inserts a command instructing the GPU to write a payload at a particular entry into the log buffer.
After the GPU engine executes the fence operation, it sees the UMD instruction to write a payload to a given entry into the log buffer. In addition, the GPU also writes the current FenceEndGpuTimestamp into this log buffer entry.
While the UMD can't access the GPU-accessible log buffer, it controls the progression of the log buffer. That is, UMD determines the next free entry to write to, if any, and programs the GPU with this information. When the GPU writes to the log buffer, it increments the FirstFreeEntryIndex value in the log header. UMD must ensure that writes to log entries are monotonically increasing.
Consider the following scenario:
- There are two HWQueues, HWQueueA and HWQueueB, with corresponding fence log buffers with GPU VAs of FenceLogA and FenceLogB. HWQueueA is associated with the log buffer for logging waits and HWQueueB is associated with the log buffer for logging signals.
- There's a native fence object with a user-mode D3DKMT_HANDLE of FenceF.
- A GPU wait on FenceF for Value V1 is queued to HWQueueA at time CPUT1. When UMD builds the command buffer, it inserts a command instructing the GPU to log the payload: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- A GPU signal to FenceF with Value V1 is queued to HWQueueB at time CPUT2. When UMD builds the command buffer, it inserts a command instructing the GPU to log the payload: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED).
After the GPU scheduler executes the GPU signal on HWQueueB at GPU time GPUT1, it reads the UMD payload and logs the event in the OS-provided fence log for HWQueueB:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
After the GPU scheduler observes HWQueueA is unblocked at GPU time GPUT2, it reads the UMD payload and logs the event in the OS-provided fence log for HWQueueA:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl can destroy and recreate a log buffer. Each time it does, it calls DxgkDdiSetNativeFenceLogBuffer to inform KMD of the new location.
CPU timestamps of fence queued operations
There's little benefit to making the UMD log these CPU timestamps given that:
- A command list can be recorded several minutes before GPU execution of a command buffer that includes the command list.
- These several minutes can be out-of-order with other sync objects that are in the same command buffer.
There's a cost to including the CPU timestamps in UMD's instructions to the GPU-written log buffer, so CPU timestamps aren't included in the log entry payload.
Instead, the runtime or UMD can emit a native fence-queued ETW event with the CPU timestamp at the time a command list is being recorded. Tools can thus build a timeline of fence-queued and completed events by combining the CPU timestamp from this new event and the GPU timestamp from the log buffer entry.
Order of operations on GPU when signaling or unblocking a fence
The UMD must ensure that it maintains the following order when it builds a command list instructing the GPU to signal/unblock a fence:
- Write the new fence value to fence GPU VA/CMP VA.
- Write the log payload to the corresponding log buffer GPU VA/CMP VA.
- Raise a native fence signaled interrupt if necessary.
This order of operations ensures that Dxgkrnl sees the most recent log entries when the interrupt is raised to the OS.
Log buffer overrun is permitted
The GPU can overrun the log buffer by overwriting to entries not yet seen by the OS. It does so by incrementing the WraparoundCount.
When the OS eventually reads the log, it can detect that an overrun occurred by comparing the new WraparoundCount value in the log header with its cached value. If an overrun occurred, the OS has the following fallback options:
- To unblock fences when an overrun occurs, the OS scans all the fences and determines which waiters were unblocked.
- If tracing was enabled, the OS can emit a flag in the trace to notify a user that events were lost. Also, when tracing is enabled, the OS first increases the size of the log buffer to prevent overruns in the first place.
It's not necessary for UMD to implement back pressure support while progressing the log buffer entries.
Empty or repeated log buffer timestamps
In common cases, Dxgkrnl expects that timestamps in log entries are monotonically increasing. However, there are scenarios when the timestamps of subsequent log entries are zero or the same as previous log entries.
For example, in a scenario with linked display adapters, one of the chained adapters in the LDA can skip the fence write operation. In this case, its log buffer entry has a zero timestamp. Dxgkrnl handles such a case. That said, Dxgkrnl never expects the timestamp of a given log entry to be less than that of the previous log entry; that is, timestamps can never go backwards.
Synchronously updating the native fence log
GPU writes to update the fence value and corresponding log buffer must ensure that writes are fully propagated before CPU reads. This requirement necessitates the use of memory barriers. For example:
- Signal Fence(N): write N as a new current value
- Write LOG entry including GPU timestamp
- MemoryBarrier
- Increment FirstFreeEntryIndex
- MemoryBarrier
- Monitored fence interrupt (N): read Address "M" and compare the value with N to decide about delivering the CPU interrupt
It's too expensive to insert two barriers on every GPU signal, especially when it's likely that the conditional interrupt check isn't satisfied and no CPU interrupt is necessary. As a result, the design moves the cost of inserting one of the memory barriers from the GPU (producer) to the CPU (consumer). Dxgkrnl calls the introduced DxgkDdiUpdateNativeFenceLogs function to cause KMD to synchronously flush pending native fence log writes on demand (similar to how DxgkddiUpdateflipqueuelog was introduced for HW flip queue log flush).
For GPU operations:
- Signal Fence(N): write N as a new current value
- Write LOG entry including the GPU timestamp
- Increment FirstFreeEntryIndex
- MemoryBarrier => Ensures FirstFreeEntryIndex is fully propagated
- Monitored fence interrupt (N): read Address "M" and compare the value with N to decide about delivering the interrupt
For CPU operations:
In Dxgkrnl’s native fence signaled interrupt handler (DISPATCH_IRQL):
- For each HWQueue Log: Read FirstFreeEntryIndex and determine if new entries are written.
- For every HWQueue log with new entries: Call DxgkDdiUpdateNativeFenceLogs and provide the kernel handles for those HWQueues. In this DDI, KMD inserts a memory barrier to each given HWQueue, which ensures that all log entry writes are committed.
- Dxgkrnl reads log entries to extract timestamp payload.
So, as long as the hardware inserts a memory barrier after writes to FirstFreeEntryIndex, Dxgkrnl always calls KMD's DDI, allowing KMD to insert a memory barrier before Dxgkrnl reads any log entries.
Future hardware requirements
Most current generation hardware might only support writing the kernel handle of the fence object it signaled in the native fence signaled interrupt. This design is described earlier in Native fence signaled interrupt. In this case, Dxgkrnl handles the interrupt payload, as follows:
- The OS performs a read (potentially across PCI) of the fence value.
- Knowing which fence was signaled and the fence value, the OS awakens CPU waiters that are waiting on that fence/value.
- Separately, for the parent device of this fence, the OS scans the log buffers of all its HWQueues. The OS then reads the last written log buffer entries to determine which HWQueue did the signal and extracts the corresponding timestamp payload. This approach might redundantly read some fence values across PCI.
On future platforms, Dxgkrnl prefers to obtain an array of kernel HwQueue handles in the native fence signaled interrupt. This approach enables the OS to:
- Read the latest log buffer entries for that HwQueue. The user device isn't known to the interrupt handler; therefore, this HwQueue handle needs to be a kernel handle.
- Scan the log buffer for log entries that indicate which fences have been signaled, and to what values. Reading only the log buffer ensures a single read over PCI instead of having to redundantly read fence values and the log buffer. This optimization succeeds as long as the log buffer hasn't been overrun (dropping entries that Dxgkrnl never read).
- If the OS detects that the log buffer was overrun, it falls back to the nonoptimized path that reads the live value of every fence owned by the same device. Performance is proportional to the number of fences owned by the device. If the fence value is in video memory, then these reads are cache-coherent across PCI.
- Knowing which fences have been signaled and the fence values, the OS awakens CPU waiters that are waiting on those fences/values.
Optimized native fence signaled interrupt
In addition to the changes described in Native fence signaled interrupt, the following change is also made to support the optimized approach:
- The OptimizedNativeFenceSignaledInterrupt cap is added to DXGK_VIDSCHCAPS.
If supported by the hardware, then instead of filling out an array of fence handles that got signaled, the GPU should only mention the KMD handle of the HWQueue that was running when the interrupt was raised. Dxgkrnl scans the fence log buffer for this HWQueue and reads all the fences operations that were completed by the GPU since the last update and unblocks any corresponding CPU waiters. If the GPU couldn't determine which subset of fences were signaled, then it should specify a NULL HWQueue handle. When Dxgkrnl sees a NULL HWQueue handle, it falls back to rescan the log buffer of all HWQueues on this engine to determine which fences got signaled.
Support for this optimization is optional; KMD should set the DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt cap if it's supported by the hardware. If the OptimizedNativeFenceSignaledInterrupt cap isn't set, then the GPU/KMD should follow the behavior described in Native fence signaled interrupt.
Example of optimized native fence signaled interrupt
HWQueueA: GPU Signal to Fence F1, Value V1 -> Write to log buffer entry E1 -> no interrupt required
HWQueueA: GPU Signal to Fence F1, Value V2 -> Write to log buffer entry E2 -> no interrupt required
HWQueueA: GPU Signal to Fence F2, Value V3 -> Write to log buffer entry E3 -> no interrupt required
HWQueueA: GPU Signal to Fence F2, Value V3 -> Write to log buffer entry E4 -> interrupt raised
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl reads the log buffer for HWQueueA. It reads log buffer entries E1, E2, E3, and E4 to observe signaled fences F1 @ Value V1, F1 @ Value V2, F2 @ Value V3, and F2 @ Value V3, and unblocks any waiters waiting on those fences and values
Optional and Mandatory Logging
Support for native fence logging for DXGK_NATIVE_FENCE_LOG_TYPE_WAITS and DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS is mandatory.
In the future, other logging types might be added for only when tools such as GPUView enable verbose ETW logging in the OS. The OS must inform both UMD and KMD of when verbose logging is enabled and disabled so that logging of those verbose events are selectively enabled.