Anreicherung unstrukturierter klinischer Notizen (Vorschauversion) in Datenlösungen für das Gesundheitswesen verwenden
[Dieser Artikel ist Teil der Dokumentation zur Vorabversion und kann geändert werden.]
Anmerkung
Dieser Inhalt wird derzeit aktualisiert.
Die Anreicherung unstrukturierter klinischer Notizen (Vorschauversion) verwendet Text Analytics for Health von Azure KI Language, um wichtige FHIR (Fast Healthcare Interoperability Resources)-Entititäten aus unstrukturierten klinische Notizen zu extrahieren. Aus diesen klinischen Notizen werden strukturierte Daten erstellt. Sie können diese strukturierten Daten dann analysieren, um Erkenntnisse, Vorhersagen und Qualitätsmaßnahmen abzuleiten, um die Gesundheitsergebnisse der Patienten zu verbessern.
Weitere Informationen zu dieser Funktion sowie zur Bereitstellung und Konfiguration finden Sie unter:
- Überblick über die Anreicherung unstrukturierter klinischer Notizen (Vorschauversion)
- Anreicherung unstrukturierter klinischer Notizen (Vorschauversion) bereitstellen und konfigurieren
Die Anreicherung unstrukturierter klinischer Notizen (Vorschauversion) hat eine direkte Abhängigkeit von der Funktion „Datengrundlagen für das Gesundheitswesen“. Stellen Sie sicher, dass Sie zuerst die Pipelines für die Datengrundlagen für das Gesundheitswesen erfolgreich eingerichtet und ausgeführt haben.
Anforderungen
- Datenlösungen für das Gesundheitswesen in Microsoft Fabric bereitstellen
- Installieren Sie die grundlegenden Notebooks und Pipelines unter Datengrundlagen für das Gesundheitswesen bereitstellen.
- Richten Sie den Azure Language Service ein, siehe dazu Azure Language Service einrichten.
- Anreicherung unstrukturierter klinischer Notizen (Vorschauversion) bereitstellen und konfigurieren
- Stellen Sie OMOP-Transformationen bereit und konfigurieren Sie diese. Dieser Schritt ist optional.
NLP-Erfassungsdienst
Das Notebook healthcare#_msft_ta4h_silver_ingestion führt das Modul NLPIngestionService in der Bibliothek für Datenlösungen für das Gesundheitswesen aus, um den Text Analytics for Health-Dienst aufzurufen. Dieser Dienst extrahiert unstrukturierte klinische Notizen aus der FHIR-Ressource DocumentReference.Content, um eine vereinfachte Ausgabe zu erstellen. Weitere Informationen finden Sie unter Überprüfen der Notebook-Konfiguration.
Datenspeicherung in der Silberschicht
Nach der NLP (Verarbeitung natürlicher Sprache)-API-Analyse wird die strukturierte und vereinfachte Ausgabe in den folgenden nativen Tabellen im Healthcare#_msft_silver Lakehouse gespeichert:
- nlpentity: Enthält die vereinfachten Entitäten, die aus den unstrukturierten klinischen Notizen extrahiert wurden. Jede Zeile ist ein einzelner Begriff, der nach Durchführung der Textanalyse aus dem unstrukturierten Text extrahiert wurde.
- nlprelationship: Stellt die Beziehung zwischen den extrahierten Entitäten bereit.
- nlpfhir: Enthält das FHIR-Ausgabepaket als JSON-Zeichenfolge.
Um den Zeitstempel der letzten Aktualisierung nachzuverfolgen, verwendet NLPIngestionService das Feld parent_meta_lastUpdated in allen drei Tabellen des Silver Lakehouse. Durch diese Nachverfolgung wird sichergestellt, dass das Quelldokument DocumentReference, bei dem es sich um die übergeordnete Ressource handelt, zuerst gespeichert wird, um die referenzielle Integrität zu wahren. Dieser Prozess hilft, Inkonsistenzen in den Daten und verwaiste Ressourcen zu vermeiden.
Wichtig
Derzeit gibt Text Analytics for Health Vokabulare zurück, die in der UMLS-Metathesaurus-Vokabulardokumentation aufgeführt sind. Weitere Informationen zu diesen Vokabularen finden Sie unter Daten aus UMLS importieren.
Für die Vorschauversion verwenden wir SNOMED-CT (Systematized Nomenclature of Medicine – Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes) und RxNorm, die im OMOP-Beispieldataset enthalten sind und auf den Leitlinien von Beobachtungsbezogene Gesundheitsdatenwissenschaften und -informatik (OHDSI) basieren.
OMOP-Transformation
Datenlösungen für das Gesundheitswesen in Microsoft Fabric bieten eine weitere Möglichkeit für Transformationen von Observational Medical Outcomes Partnership (OMOP). Wenn Sie diese Funktion ausführen, transformiert die zugrunde liegende Transformation vom Silver Lakehouse zum OMOP Gold Lakehouse auch die strukturierte und vereinfachte Ausgabe der Analyse der unstrukturierten klinischen Notizen. Die Transformation liest aus der Tabelle nlpentity im Silver Lakehouse und ordnet die Ausgabe der Tabelle NOTE_NLP im OMOP Gold Lakehouse zu.
Weitere Informationen finden Sie unter Überblick über OMOP-Transformationen.
Hier ist das Schema für die strukturierten NLP-Ausgaben mit der Zuordnung der entsprechenden NOTE_NLP-Spalte zum allgemeinen OMOP-Datenmodell:
| Dokumentreferenz zur Vereinfachung | Eigenschaft | Note_NLP-Zuordnung | Stichprobendaten |
|---|---|---|---|
| id | Eindeutiger Bezeichner für die Entität Zusammengesetzter Schlüssel von parent_id, offset und length |
note_nlp_id |
1380 |
| parent_id | Ein Fremdschlüssel für den vereinfachten Text documentreferencecontent, aus dem der Begriff extrahiert wird | note_id |
625 |
| text | Entitätstext, der im Dokument angezeigt wird | lexical_variant |
Keine bekannten Allergien |
| Offset | Zeichenoffset des extrahierten Begriffs im Eingabetext documentreferencecontent | offset |
294 |
| data_source_entity_id | ID der Entität im angegebenen Quellkatalog | note_nlp_concept_id und note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | Das Datum der Textanalyseverarbeitung documentreferencecontent | nlp_date_time und nlp_date |
2023-05-17T00:00:00.0000000 |
| Modell | Name und Version des NLP-Systems (Name des Text Analytics for Health NLP-Systems und der Version) | nlp_system |
MSFT TA4H |

Dienstlimits für Text Analytics for Health
- Die maximale Anzahl von Zeichen pro Dokument ist auf 125.000 begrenzt.
- Die maximale Größe der in der gesamten Anforderung enthaltenen Dokumente ist auf 1 MB begrenzt.
- Die maximale Anzahl von Dokumenten pro Anforderung ist begrenzt auf:
- 25 für die webbasierte API
- 1000 für den Container
Protokolle aktivieren
Führen Sie die folgenden Schritte aus, um die Anforderungs- und Antwortprotokollierung für die Text Analytics for Health-API zu aktivieren:
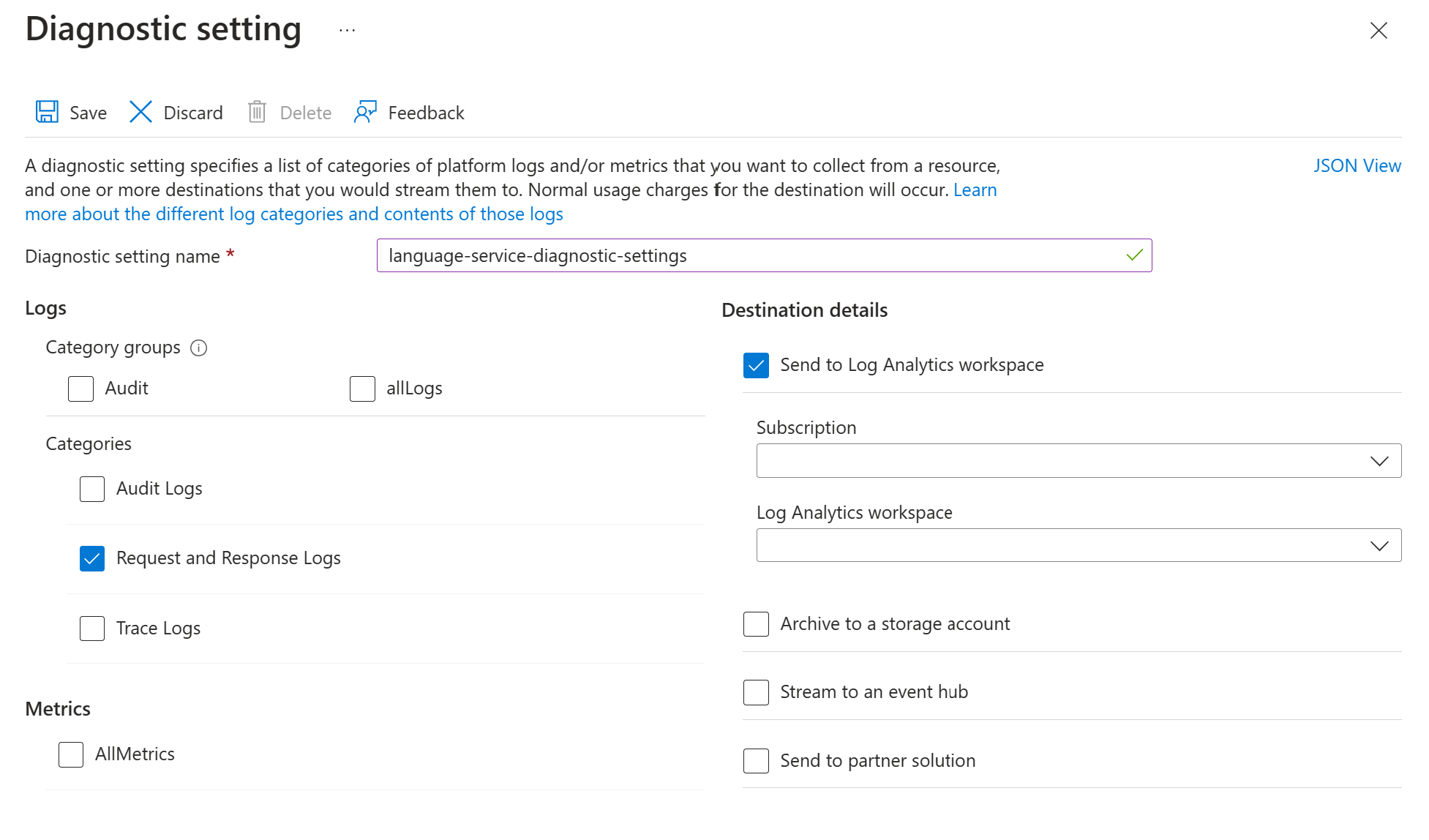
Aktivieren Sie die Diagnoseeinstellungen für Ihre Azure Language Service-Ressource, indem Sie den Anweisungen unter Diagnoseprotokollierung für Azure KI Services aktivieren befolgen. Bei dieser Ressource handelt es sich um denselben Sprachdienst, den Sie im Bereitstellungsschritt Azure Language Service einrichten erstellt haben.
- Geben Sie einen Namen für die Diagnoseeinstellung ein.
- Legen Sie die Kategorie auf Anforderungs- und Antwortprotokolle fest.
- Um Details zum Ziel zu erhalten, wählen Sie An Log Analytics-Arbeitsbereich senden und dann den erforderlichen Log Analytics-Arbeitsbereich aus. Wenn Sie noch keinen Arbeitsbereich haben, befolgen Sie die Anweisungen, um einen zu erstellen.
- Speichern Sie die Einstellungen.
Wechseln Sie zum AbschnittNLP-Konfiguration im Notebook NLP-Erfassungsdienst. Aktualisieren Sie den Wert des Konfigurationsparameters
enable_text_analytics_logsaufTrue. Weitere Informationen zu diesem Notebook finden Sie unter Notebook-Konfiguration überprüfen.

Anzeigen von Protokollen in Azure Log Analytics
So untersuchen Sie die Protokollanalysedaten:
- Navigieren Sie zu Ihrem Log Analytics-Arbeitsbereich.
- Suchen Sie nach Protokolle und wählen Sie sie aus. Auf dieser Seite können Sie Abfragen für Ihre Protokolle ausführen.
Beispielabfrage
Im Folgenden finden Sie eine einfache Kusto-Abfrage, mit der Sie Ihre Protokolldaten untersuchen können. Diese Beispielabfrage ruft alle fehlgeschlagenen Anforderungen vom Azure Cognitive Services-Ressourcenanbieter des letzten Tags ab, gruppiert nach Fehlertyp:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature