OMOP-Transformationen in Datenlösungen für das Gesundheitswesen bereitstellen und konfigurieren
Anmerkung
Dieser Inhalt wird derzeit aktualisiert.
Die OMOP Transformationen bereitet Daten für standardisierte Analysen durch offene Community-Standards der Observational Medical Outcomes Partnership (OMOP) vor. Sie können diese Funktion nach der Bereitstellung von Datenlösungen für Gesundheitsdaten in Ihrem Fabric-Arbeitsbereich und der Funktion „Datengrundlagen für das Gesundheitswesen“ einrichten.
OMOP-Transformationen ist eine optionale Funktion in den Datenlösungen für das Gesundheitswesen in Microsoft Fabric. Sie haben die Flexibilität zu entscheiden, ob Sie es verwenden möchten oder nicht, abhängig von Ihren spezifischen Anforderungen oder Szenarien.
Anforderungen
- Datenlösungen für das Gesundheitswesen in Microsoft Fabric bereitstellen
- Installieren Sie die grundlegenden Notebooks und Pipelines unter Datengrundlagen für das Gesundheitswesen bereitstellen.
OMOP-Transformationen bereitstellen
Sie können die Funktion mithilfe des Setup-Moduls bereitstellen, das unter Datenlösungen für das Gesundheitswesen: Datengrundlagen für das Gesundheitswesen bereitstellen erläutert wird. Der Schritt zur Auswahl der Beispieldaten in diesem Modul stellt jedoch keine Beispieldaten für diese Funktion bereit. Die Beispieldaten der OMOP-Transformationen werden ausschließlich in Ihrer Datenlösungsumgebung für das Gesundheitswesen installiert, nachdem Sie die Bereitstellung der Funktion abgeschlossen haben.
Wenn Sie das Setup-Modul nicht zum Bereitstellen der Funktionalität verwendet haben und stattdessen die Kachel der Funktionalität verwenden möchten, gehen Sie folgendermaßen vor:
Rufen Sie die Homepage für Datenlösungen für das Gesundheitswesen in Fabric auf.
Wählen Sie die Kachel OMOP-Transformationen aus.

Auf der Funktionsseite wählen Sie im Arbeitsbereich bereitstellen aus.
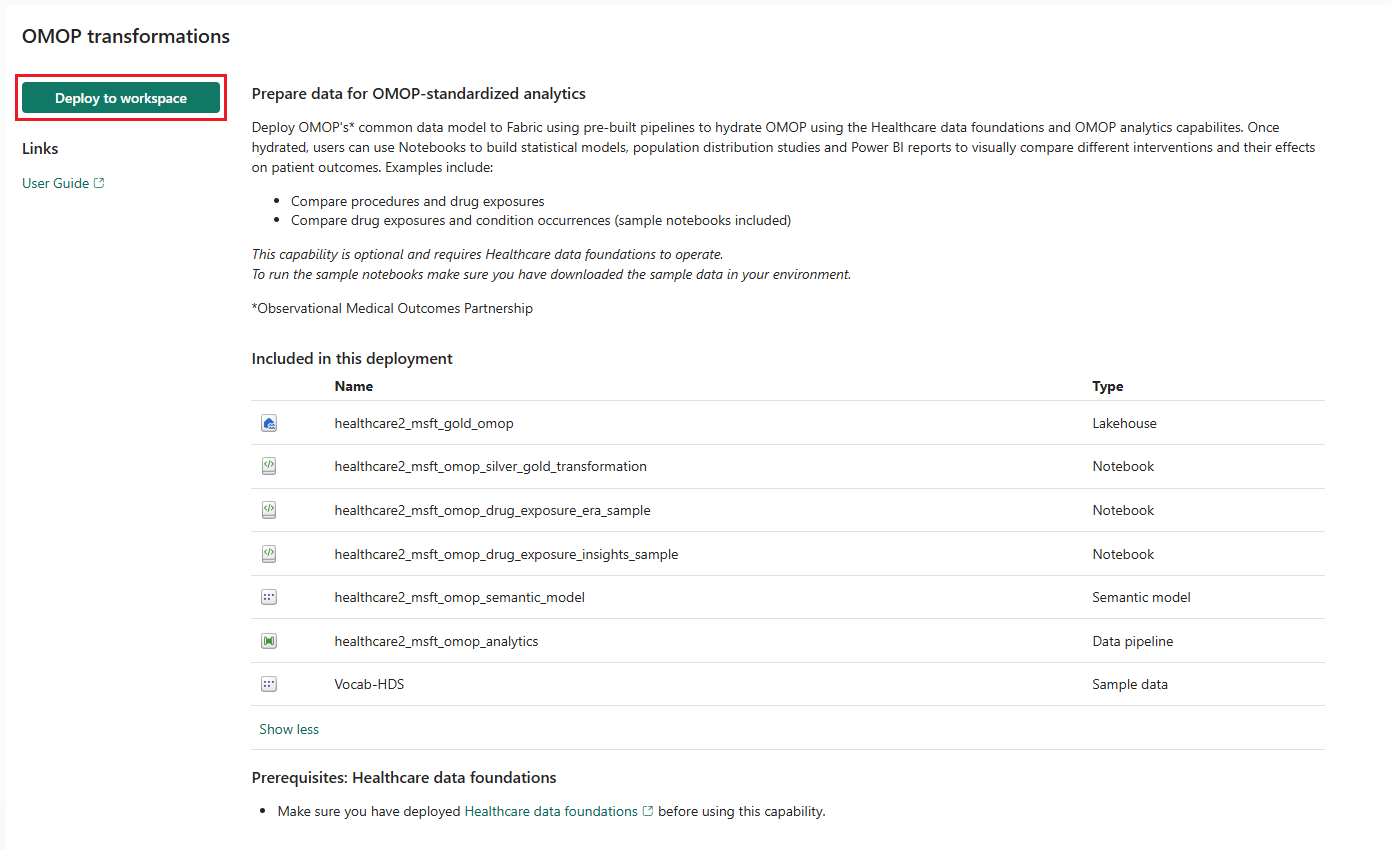
Die Bereitstellung kann einige Minuten dauern. Schließen Sie die Registerkarte oder den Browser nicht, während die Bereitstellung ausgeführt wird. Während Sie warten, können Sie in einer anderen Registerkarte arbeiten.
Nach Abschluss der Bereitstellung wird eine Benachrichtigung in der Meldungsleiste angezeigt.
Wählen Sie in der Meldungsleiste die Option Funktion verwalten aus , um zur Seite Funktionsverwaltung zu gelangen.
Hier können Sie die mit der Funktion bereitgestellten Artefakte anzeigen, konfigurieren und verwalten.


Artefakte
Die Funktion installiert die folgenden Artefakte und eine Datenpipeline in Ihrer Datenlösungsumgebung für das Gesundheitswesen:
| Artefakt | typ |
|---|---|
| healthcare#_msft_gold_omop | Lakehouse |
| healthcare#_msft_omop_silver_gold_transformation | Notizbuch |
| healthcare#_msft_omop_drug_exposure_era_sample | Notizbuch |
| healthcare#_msft_omop_drug_exposure_insights_sample | Notizbuch |
| healthcare#_msft_omop_analytics | Datenpipeline |
| healthcare#_msft_omop_semantic_model | Semantikmodell |
| Vocab-HDS | Stichprobendaten |
Überprüfen Sie das OMOP-Silber-Notebook.
Das Notebook healthcare#_msft_omop_silver_gold_transformation verwendet die OMOP-APIs, die im Lieferumfang der Bibliothek für Datenlösungen für das Gesundheitswesen für die Datentransformation enthalten sind. Das Notebook transformiert Ressourcen im healthcare#_msft_silver Lakehouse in ein OMOP-Commond Data Model. Die transformierten Daten werden dann in das OMOP Lakehouse eingefügt.
Das Notebook wird mit vorkonfigurierten Werten bereitgestellt, die zum Ausführen der zugehörigen OMOP-Transformationen-Datenpipeline erforderlich sind. Einige Konfigurationsparameter erben von der globalen Konfiguration und können auf Notebook-Ebene überschrieben werden. Standardmäßig wird von Ihnen nicht erwartet, dass Sie Änderungen an den Notebook-Konfigurationsdateien vornehmen. Bei Bedarf können Sie die Konfiguration überprüfen oder ändern, indem Sie die entsprechenden Notebooks und Konfigurationsdateien in Ihrer Umgebung auswählen.
Weitere Informationen zur Ausführung von Notebooks finden Sie unter Verwenden von OMOP-Transformationen.
Überprüfen und speichern Sie das semantische OMOP-Modell.
Das semantische OMOP-Modell, healthcare#_msft_omop_semantic_model, ist ein benutzerdefiniertes semantisches Modell, das auf dem OMOP Gold Lakehouse basiert. Sie enthält einige wichtige OMOP CDM Version 5.4 Beziehungen zwischen den folgenden OMOP Tabellen:
- Ort
- Person
- Beobachtung
- Procedure_Occurrence
- Condition_Occurrence
- Anmerkung
- Drug_Exposure
- Visit_Ocurrence
- Image_Occurrence
- Messung
Diese Beziehungen stammen aus dem minimalen Satz, der zum Generieren von Power BI Berichten in der Funktion Kohorten ermitteln und erstellen (Vorschauversion) in Datenlösungen für das Gesundheitswesen erforderlich ist. Sie können dieses semantische Modell als Grundlage verwenden, indem Sie weitere OMOP Tabellen und Beziehungen aus dem OMOP Lakehouse hinzufügen, um benutzerdefinierte Power BI Berichte aus Ihren OMOP Standard-Lakehouse-Daten zu erstellen.
Das Beispielnotizbuch für die Ära der Drogenexposition konfigurieren
Das Beispiel-Notebook healthcare#_msft_omop_drug_exposure_era_sample zeigt, wie die drug_era Tabellendatensätze in OMOP unter Verwendung der Sprache PySpark (Python) in einem Azure Synapse Analytics Notebook generiert werden, hauptsächlich zu explorativen Zwecken. Die Generierung von drug_era-Tabellendatensätzen folgt dem Beispielskript für die OHDSI-Arzneimittelära, das für die Arbeit mit PySpark in Azure Synapse Analytics angepasst ist. Der Code für den Drug Era-Generator ist in der benutzerdefinierten Python-Bibliothek enthalten, die als Wheel-Datei (WHL) verpackt und für einen einfachen Zugriff in einen Apache Spark Pool hochgeladen wird.
Beachten Sie vor der Ausführung des Notebooks die folgenden Voraussetzungen:
Stellen Sie sicher, dass die OMOP Datenbank über gültige Daten in den folgenden Tabellen verfügt:
- drug_exposure
- Konzept
- concept_ancestor
Sie können diese Daten mithilfe der Beispieldaten oder Ihrer eigenen Daten generieren, indem Sie die FHIR-zu-Daten-Pipeline OMOP ausführen.
Stellen Sie sicher, dass das benutzerdefinierte Bibliotheksradpaket an den Spark-Pool angefügt ist, den Sie zum Ausführen dieses Notebooks verwenden.
Der wichtigste Konfigurationsparameter für dieses Notebook ist der omop_database_name. Dieser Parameter gibt den Namen der Datenbank an, die OMOP die Daten zum Generieren der drug_era Tabelle enthält. Aktualisieren Sie diesen Wert nur, wenn Ihre OMOP Datenbank vom Standardwert in der globalen Konfigurationsdatei abweicht.
Wenn die OMOP drug_exposure Tabelle mit gültigen Daten gefüllt wird, ruft dieses Notebook das DrugEraGenerator-Modul auf, das Zeiträume aneinanderreiht, in denen eine Person einem Wirkstoff ausgesetzt ist, wobei ein Abstand von 30 Tagen berücksichtigt wird. Das DrugEraGenerator-Modul löscht alle vorhandenen drug_era Datensätze und generiert neue Datensätze, basierend auf den neuesten OMOP Daten.
Weitere Informationen zur Ausführung von Notebooks finden Sie unter Verwenden von Beispiel-Notebooks für OMOP-Transformationen.
Das Beispielnotizbuch für die Erkenntnisse der Drogenexposition konfigurieren
Das Beispiel-Notebook healthcare#_msft_omop_drug_exposure_insights_sample demonstriert eine explorative Analyse der drug_era-Tabelle mithilfe von PySpark in einem Azure Synapse Analytics-Notebook. Die Analyse erzeugt ein Histogramm, das die sekundäre Arzneimittelexposition der Patienten gegenüber Wirkstoffen anzeigt, stratifiziert nach Geschlecht und Alter für ein bestimmtes Jahr. Die drug_era Tabelle wird mithilfe einer benutzerdefinierten Bibliothek DrugEraGenerator generiert, die vom vorherigen Notebook healthcare#_msft_omop_drug_exposure_era_sample aufgerufen wird. Diese Analyse erweitert die Abfrage DEX03: Verteilung des Alters, stratifiziert nach Drogen durch Einbeziehung der Stratifizierung auf der Grundlage von Geschlecht und Alter.
Beachten Sie vor der Ausführung des Notebooks die folgenden Voraussetzungen:
- Wenn Sie die Notizbuchkonfiguration bearbeiten möchten, stellen Sie sicher, dass Sie eine Kopie dieses Notizbuchs erstellen. Aktualisieren Sie das Notizbuch nicht direkt.
- Stellen Sie sicher, dass die drug_era-Tabelle Daten enthält, indem Sie das Notebook Drug Exposure Era ausführen. Beim Ausführen dieses Notebooks werden alle vorhandenen drug_era Datensätze basierend auf den neuesten OMOP Daten durch neue Datensätze ersetzt.
- Verwenden Sie dieses Notizbuch unverändert für explorative Analysen, und erstellen Sie eine Kopie, um benutzerdefinierte Analysen durchzuführen.
Im Anschluss sind die wichtigsten Konfigurationsparameter dieses Notebooks aufgeführt. Sie können diese Parameter für alternative explorative Analysen zur Arzneimittelexposition von Patienten ändern:
primary_drug_concept_id: Die primäre Wirkstoffexposition für Patienten.secondary_drug_concept_id: Die sekundäre Wirkstoffexposition für Patienten.year: Das Zieljahr, in dem die Patienten sowohl dem primären als auch dem sekundären Medikament aktiv ausgesetzt waren.
Weitere Informationen zur Ausführung von Notebooks finden Sie unter Verwenden von Beispiel-Notebooks für OMOP-Transformationen.