Identifizieren vertraulicher und sicherheitsrelevanter Informationen für die Einhaltung von PSPF durch die australische Regierung
Dieser Artikel enthält Anleitungen für australische Regierungsorganisationen zur Verwendung von Microsoft Purview zum Identifizieren vertraulicher und sicherheitsrelevanter Informationen. Der Zweck ist es, diesen Organisationen zu helfen, ihren Ansatz zur Datensicherheit und ihre Fähigkeit zu stärken, anforderungen zu erfüllen, die im Schutzsicherheitsrichtlinien-Framework (PSPF) und im Handbuch zur Informationssicherheit (ISM) beschrieben sind.
Der Schlüssel zum Schutz von Informationen und zum Schutz vor Datenverlust besteht darin, zunächst zu verstehen, was Informationen sind. In diesem Artikel werden Methoden zum Identifizieren von Informationen in einer Microsoft 365-Umgebung in Organisationen untersucht. Diese Ansätze werden häufig als Die Kennen Ihrer Datenaspekte von Microsoft Purview bezeichnet. Nach der Identifizierung können die Informationen sowohl durch automatische Vertraulichkeitsbezeichnungen als auch durch Verhinderung von Datenverlust (Data Loss Prevention, DLP) geschützt werden.
Typen vertraulicher Informationen
Typen vertraulicher Informationen (SITs) sind musterbasierte Klassifizierer. Sie erkennen vertrauliche Informationen über reguläre Ausdrücke (RegEx) oder Schlüsselwörter.
Es gibt viele verschiedene Arten von SITs, die für australische Regierungsorganisationen relevant sind:
- Vordefinierte SITS , die von Microsoft erstellt wurden, von denen einige mit gängigen australischen Datentypen übereinstimmen.
- Benutzerdefinierte SITs werden basierend auf den Anforderungen der Organisation erstellt.
- Benannte Entitäts-SITs enthalten komplexe wörterbuchbasierte Bezeichner, z. B . australische physische Adressen.
- EDM-SITs (Exact Data Match) werden basierend auf tatsächlichen vertraulichen Daten generiert.
- Fingerabdruck-SITs von Dokumenten basieren auf dem Format von Dokumenten und nicht auf ihrem Inhalt.
- SITs, die für die Netzwerk- oder Informationssicherheit relevant sind, obwohl technisch vorgefertigte SITs, haben sie besondere Relevanz für Cyber-Teams, die für organisationen der australischen Regierung arbeiten, und sind daher ihrer eigenen Kategorie würdig.
Vordefinierte Typen vertraulicher Informationen
Vordefinierte Typen vertraulicher Informationen basieren auf allgemeinen Arten von Informationen, die Kunden in der Regel als vertraulich betrachten. Diese können generisch und global relevant sein (z. B. Guthaben Karte Nummern) oder lokal relevant sein (z. B. australische Bankkontonummern).
Die vollständige Liste der vordefinierten SITs von Microsoft finden Sie unter Entitätsdefinitionen des Typs vertraulicher Informationen.
Zu den australischen spezifischen SITs gehören:
- Australische Bankkontonummer
- Australische Führerscheinnummer
- Australische Reisepassnummer
- Australische physische Adressen
- Australische Steuerdateinummer
- Australische Geschäftsnummer
- Australische Firmennummer
- Australische Medizinische Kontonummer
Diese SITs finden Sie im Microsoft Purview-Datenklassifizierungsportal unter Klassifizierer>Vertrauliche Informationstypen.
Vordefinierte SITs sind nützlich für Organisationen, die ihre Information Protection oder Governance Journey starten, da sie einen Vorsprung in Richtung der Aktivierung von Funktionen wie DLP und automatischer Bezeichnung bieten. Die beiden einfachsten Möglichkeiten, diese SITs zu nutzen, sind:
Verwendung vordefinierter SITs über DLP-Richtlinienvorlagen
Einige vordefinierte SITs sind in von Microsoft erstellten DLP-Richtlinienvorlagen enthalten, die den australischen Vorschriften entsprechen. Die folgenden DLP-Richtlinienvorlagen, die den australischen Anforderungen entsprechen, stehen zur Verwendung zur Verfügung:
- Australien Privacy Act erweitert
- Finanzdaten – Australien
- PCI Data Security Standard (PCI DSS)
- Personenbezogene Informationen (PII-Daten) – Australien
Die Aktivierung von DLP-Richtlinien, die auf diesen Vorlagen basieren, ermöglicht die erste Überwachung von Datenverlustereignissen, die einen hervorragenden Ausgangspunkt für Organisationen darstellen, die Microsoft 365 DLP einführen. Nach der Bereitstellung bieten diese Richtlinien Einen Einblick in das Ausmaß eines Problems mit Datenverlust in Organisationen und können helfen, Entscheidungen über die nächsten Schritte zu treffen.
Die Verwendung dieser Richtlinienvorlagen wird weiter untersucht, um die Verteilung vertraulicher Informationen einzuschränken.
Verwendung vordefinierter SITs bei der automatischen Vertraulichkeitsbezeichnung
Wenn festgestellt wird, dass ein Artikel eine australische Medizinische Kontonummer, einen oder mehrere medizinische Begriffe und einen vollständigen Namen enthält, kann davon ausgegangen werden, dass der Artikel persönlich identifizierbare medizinische Informationen enthält und eine Gesundheitsakte darstellen könnte. Basierend auf dieser Annahme können wir einem Benutzer vorschlagen, dass der Artikel als "OFFICIAL: Sensitive Personal Privacy" bezeichnet wird oder welche Bezeichnung in Ihrem organization für die Identifizierung und den Schutz von Gesundheitsdaten am besten geeignet ist.
Weitere Informationen, in denen dieses Feature Regierungsorganisationen bei der Einhaltung der PSPF-Compliance unterstützen kann, finden Sie unter Automatische Anwendung von Vertraulichkeitsbezeichnungen und clientbasierte Szenarien für die automatische Bezeichnung für australische Regierung.
Benutzerdefinierte Typen vertraulicher Informationen
Zusätzlich zu vordefinierten SITs können Organisationen SITs basierend auf ihren eigenen Definitionen vertraulicher Informationen erstellen. Beispiele für Informationen, die für Organisationen der australischen Regierung relevant sind und über benutzerdefinierte SIT identifiziert werden können, sind:
- Schutzkennzeichnungen
- Clearance ID oder Clearance-Anwendungs-ID
- Klassifizierungen aus anderen Staaten oder Gebieten
- Klassifizierungen, die auf der Plattform nicht angezeigt werden sollten (z. B. TOP SECRET)
- Besprechungen oder Korrespondenz der Minister
- FoI-Anforderungsnummer (Freedom of Information, Informationsfreiheit)
- Informationen zur Wahrscheinlichkeit
- Begriffe im Zusammenhang mit sensiblen Systemen, Projekten oder Anwendungen
- Absatzmarkierungen
- Kürzen oder Zieldatensatzzahlen
Benutzerdefinierte SITs bestehen aus einem primären Bezeichner, der entweder auf einem regulären Ausdruck oder Schlüsselwörtern, einem Konfidenzniveau und optionalen unterstützenden Elementen basieren kann.
Eine ausführlichere Erläuterung von SITs und deren Komponenten finden Sie unter Informationen zu typen vertraulicher Informationen.
Reguläre Ausdrücke (RegEx)
Reguläre Ausdrücke sind codebasierte Bezeichner, die zum Identifizieren von Informationsmustern verwendet werden können. Wenn beispielsweise eine FOI-Nummer (Freedom of Information) aus den Buchstaben FOI besteht, gefolgt von einem vierstelligen Jahr, einem Bindestrich und weiteren drei Ziffern (z. B FOI2023-123. ), könnte sie in einem regulären Ausdruck dargestellt werden:
[Ff][Oo][Ii]20[01234]\d{1}-\d{3}
So erklären Sie diesen Ausdruck:
-
[Ff][Oo][Ii]entspricht den Groß- oder Kleinbuchstaben F, O und I. -
20entspricht der Zahl 20 als erste Hälfte des vierstelligen Jahres. -
[0123]entspricht 0, 1, 2 oder 3 in der dritten Ziffer unseres vierstelligen Jahreswerts, sodass wir FOI-Zahlen aus dem Jahr 2000 bis 2039 abgleichen können. -
-entspricht einem Bindestrich. -
\d{3}entspricht allen drei Ziffern.
Tipp
Copilot ist sehr geschickt beim Generieren regulärer Ausdrücke (RegEx). Sie können natürliche Sprache verwenden, um Copilot zu bitten, RegEx für Sie zu generieren.
Liste der Schlüsselwörter oder eines Schlüsselwort (keyword) Wörterbuchs
Schlüsselwortlisten und Wörterbücher bestehen aus Wörtern, Begriffen oder Ausdrücken, die wahrscheinlich in den Elementen enthalten sind, die Sie identifizieren möchten. Kabinettsbesprechung oder Ausschreibung sind Begriffe, die als Schlüsselwörter nützlich sein könnten.
Bei Schlüsselwörtern kann die Groß-/Kleinschreibung beachtet oder nicht beachtet werden. Die Groß-/Kleinschreibung kann bei der Beseitigung falsch positiver Ergebnisse nützlich sein. Beispielsweise wird in allgemeinen Konversationen eher Kleinbuchstaben official verwendet, aber Großbuchstaben OFFICIAL haben eine höhere Wahrscheinlichkeit, Teil einer schützenden Markierung zu sein.
Schlüsselwortwörterbücher, die große Datasets enthalten, können auch im CSV- oder TXT-Format hochgeladen werden. Weitere Informationen zum Hochladen eines Schlüsselwort (keyword) Wörterbuchs finden Sie unter Erstellen eines Schlüsselwort (keyword) Wörterbuchs.
Zuverlässigkeitsstufe
Einige Schlüsselwörter oder reguläre Ausdrücke können einen genauen Abgleich ermöglichen, ohne dass eine Einschränkung erforderlich ist. Der ausdruck freedom of information (FOI), der im vorherigen Beispiel eines Werts enthalten ist, ist unwahrscheinlich, dass er in einer allgemeinen Konversation auftritt und wenn er in der Korrespondenz erscheint, wahrscheinlich mit relevanten Informationen übereinstimmt. Wenn wir jedoch versuchen, eine Mitarbeiternummer des australischen öffentlichen Diensts abzugleichen, die als acht numerische Ziffern dargestellt wird, führt unser Abgleich wahrscheinlich zu zahlreichen falsch positiven Ergebnissen. Die Zuverlässigkeitsstufe ermöglicht es uns, die Wahrscheinlichkeit zuzuweisen, dass das Vorhandensein des Schlüsselwort (keyword) oder Musters in einem Element wie einer E-Mail oder einem Dokument tatsächlich das ist, wonach wir suchen. Weitere Informationen zu Konfidenzniveaus finden Sie unter Verwalten von Konfidenzstufen.
Primäre und unterstützende Elemente
Benutzerdefinierte SITs haben auch ein Konzept von primären und unterstützenden Elementen. Das primäre Element ist das Schlüsselmuster, das wir im Inhalt erkennen möchten. Unterstützende Elemente können einem primären Element hinzugefügt werden, um einen Fall für das Vorkommen eines Werts zu erstellen, der eine genaue Übereinstimmung ist. Wenn Sie z. B. versuchen, eine Übereinstimmung basierend auf einer achtstelligen Numerischen Mitarbeiternummer durchzuführen, können Sie Schlüsselwörter wie "Mitarbeiternummer" oder "Australian Government Number AGS" oder "Australian Public Service Employee Database APSED " als unterstützendes Element verwenden, um die Zuverlässigkeit zu erhöhen, dass die Übereinstimmung relevant ist. Weitere Informationen zum Erstellen von primären und unterstützenden Elementen finden Sie unter Grundlegendes zu Elementen.
Zeichennähe
Der letzte Wert, den wir in einer SIT im Allgemeinen konfigurieren würden, ist die Zeichennähe. Dies ist der Abstand zwischen primären und unterstützenden Elementen. Wenn wir erwarten, dass der Schlüsselwort (keyword) AGS in der Nähe unseres achtstelligen numerischen Werts liegt, konfigurieren wir eine Nähe von 10 Zeichen. Wenn primäre und unterstützende Elemente wahrscheinlich nicht nebeneinander angezeigt werden, legen wir den Näherungswert auf eine größere Anzahl von Zeichen fest. Weitere Informationen zum Erstellen von Zeichennähe finden Sie unter Grundlegendes zur Näherung.
SITs zum Identifizieren von Schutzmarkierungen
Eine wertvolle Möglichkeit für australische Regierungsorganisationen, benutzerdefinierte SITs zu verwenden, ist die Identifizierung von Schutzmarkierungen. In einem Greenfield-organization wird auf alle Elemente in einer Umgebung eine Vertraulichkeitsbezeichnung angewendet. Die meisten Regierungsorganisationen verfügen jedoch über Legacybezeichnungen, die eine Modernisierung in Microsoft Purview erfordern. SITs werden verwendet, um Markierungen zu identifizieren und auf Folgendes anzuwenden:
- Markierte Legacydateien
- Markierte Dateien, die von externen Entitäten generiert werden
- Email von Extern initiierten und markierten Unterhaltungen
- E-Mails, die ihre Bezeichnungsinformationen verloren haben (X-Header)
- E-Mails, deren Bezeichnungen fälschlicherweise herabgestuft wurden
Wenn ein solcher Marker identifiziert wird, wird der Benutzer über die Erkennung informiert und ihm eine Bezeichnungsempfehlung zur Verfügung gestellt. Wenn sie die Empfehlung akzeptieren, gelten bezeichnungsbasierte Schutzmaßnahmen für das Element. Diese Konzepte werden unter Szenarien für clientbasierte automatische Bezeichnungen für australische Regierung weiter erläutert.
Klassifizierungsbasierte SITs sind auch in DLP nützlich. Dazu gehören:
- Ein Benutzer erhält Informationen und identifiziert sie über seine Markierung als vertraulich, möchte sie aber nicht neu klassifizieren, da sie nicht in eine PSPF-Klassifizierung übersetzt werden (z. B. "OFFICIAL Sensitive NSW Government"). Das Erstellen einer DLP-Richtlinie zum Schutz der eingeschlossenen Informationen basierend auf der Markierung und nicht auf der angewendeten Bezeichnung bedeutet, dass wir ein Maß an Datensicherheit darauf anwenden können.
- Ein Benutzer kopiert Text aus einer E-Mail-Unterhaltung, die eine Schutzkennzeichnung enthält. Sie fügen die Informationen in einen Teams-Chat mit einem externen Teilnehmer ein, der keinen Zugriff auf die Informationen haben soll. Über eine DLP-Richtlinie, die auf den Teams-Dienst angewendet wird, kann die Markierung erkannt und die Offenlegung verhindert werden.
- Ein Benutzer herabstuft eine Vertraulichkeitsbezeichnung in einer E-Mail-Unterhaltung fälschlicherweise herab (entweder böswillig oder durch Benutzerfehler). Da die zuvor auf die E-Mail angewendeten Schutzmarkierungen im Textkörper der E-Mail sichtbar sind, erkennt Microsoft Purview, dass die aktuellen und vorherigen Markierungen falsch ausgerichtet sind. Je nach Konfiguration protokolliert die Aktion das Ereignis, warnt den Benutzer oder blockiert die E-Mail.
- Eine markierte E-Mail wird an einen externen Empfänger gesendet, der eine E-Mail-Plattform oder einen Nicht-Unternehmens-E-Mail-Client nutzt. Die Plattform oder der Client entfernt die Metadaten der E-Mail (X-Header), wodurch auf die Antwort-E-Mail des externen Empfängers keine Vertraulichkeitsbezeichnung angewendet wird, wenn sie im Benutzerpostfach des organization eingeht. Die Erkennung der vorherigen Markierung über eine SIT ermöglicht die transparente Erneutes Anwenden der Bezeichnung oder die Empfehlung, dass der Benutzer die Bezeichnung bei der nächsten Antwort erneut anwendet.
In jedem dieser Szenarien könnten klassifizierungsbasierte SITs verwendet werden, um angewendete Schutzmarkierungen zu erkennen und die potenzielle Datenverletzung zu minimieren.
SIT-Beispielsyntax zum Erkennen von Schutzmarkierungen
Die folgenden regulären Ausdrücke können in benutzerdefinierten SITs verwendet werden, um Schutzmarkierungen zu identifizieren.
Wichtig
Die Erstellung von SITs zur Identifizierung von Schutzmarkierungen unterstützt die PSPF-Konformität. Klassifizierungsbasierte SITs werden auch in DLP- und Auto-Labeling-Szenarien verwendet.
| SIT-Name | Regulärer Ausdruck |
|---|---|
| INOFFIZIELLE Regex1 | UNOFFICIAL |
| OFFICIAL Regex1,2 | (?<!UN)OFFICIAL |
| OFFICIAL Sensitive Regex1,3,4,5 | OFFICIAL[:- ]\s?Sensitive(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET) |
| OFFICIAL Sensitive Personal Privacy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| OFFICIAL Sensitive Legal Privilege Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| OFFICIAL Sensitive Legislative Secrecy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| OFFICIAL Sensitive NATIONAL CABINET Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED Regex1,3,5 | PROTECTED(?!,\sACCESS=)(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET)(?!(?:\s\|\/\/\|\s\/\/\s)CABINET) |
| PROTECTED Privacy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| PROTECTED Legal Privilege Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| PROTECTED Legislative Secrecy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| PROTECTED NATIONAL CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)CABINET |
Beachten Sie beim Auswerten der vorherigen SIT-Beispiele die folgende Ausdruckslogik:
- 1 Diese Ausdrücke stimmen mit Markierungen überein, die auf beide Dokumente (z. B . OFFICIAL: Sensitive NATIONAL CABINET) und E-Mail (z. B. '[SEC=OFFICIAL:Sensitive, CAVEAT=NATIONAL-CABINET]') angewendet werden.
-
2 Der negative Lookbehind in OFFICIAL Regex (
(?<!UN)) verhindert, dass NICHT OFFIZIELLE Elemente abgeglichen werden. -
3OFFICIAL Sensitive Regex und PROTECTED Regex verwenden negative Lookaheads (
(?!)), um sicherzustellen, dass information management markers (IMM) oder Einschränkungen nach der Sicherheitsklassifizierung nicht angewendet werden. Auf diese Weise wird verhindert, dass Elemente mit IMMs oder Einschränkungen als nicht-IMM- oder Vorbehaltsversion der Klassifizierung identifiziert werden. -
4 Die Verwendung von
[:\- ]in OFFICIAL: Sensitive soll flexibilität im Format dieser Markierung ermöglichen und ist aufgrund der Verwendung von Doppelpunkten in x-Headern wichtig. -
5
(?:\s\|\/\/\|\s\/\/\s)wird verwendet, um den Abstand zwischen markierungskomponenten zu identifizieren und ermöglicht entweder ein einzelnes Leerzeichen, ein doppeltes Leerzeichen, einen doppelten Schrägstrich oder einen doppelten Schrägstrich mit Leerzeichen. Dies soll die unterschiedlichen Interpretationen des PSPF-Kennzeichnungsformats ermöglichen, das zwischen australischen Regierungsorganisationen vorhanden ist.
Typen vertraulicher Informationen zu benannten Entitäten
Benannte Entitäts-SITs sind komplexe Wörterbuch- und musterbasierte Bezeichner, die von Microsoft erstellt wurden und zum Erkennen von Informationen wie den folgenden verwendet werden können:
- namen von Personen
- Physische Adressen
- Medizinische Geschäftsbedingungen
Benannte Entitäts-SITs können isoliert verwendet werden, können aber auch als unterstützende Elemente nützlich sein. Beispielsweise kann ein medizinischer Begriff, der in einer E-Mail vorhanden ist, nicht als Hinweis darauf dienen, dass das Element vertrauliche Informationen enthält. Ein medizinischer Begriff, wenn er mit einem Wert gekoppelt ist, der eine Kunden- oder Patientennummer und einen Vor- und Familiennamen angeben kann, würde jedoch ein starkes Indiz dafür liefern, dass der Artikel empfindlich ist.
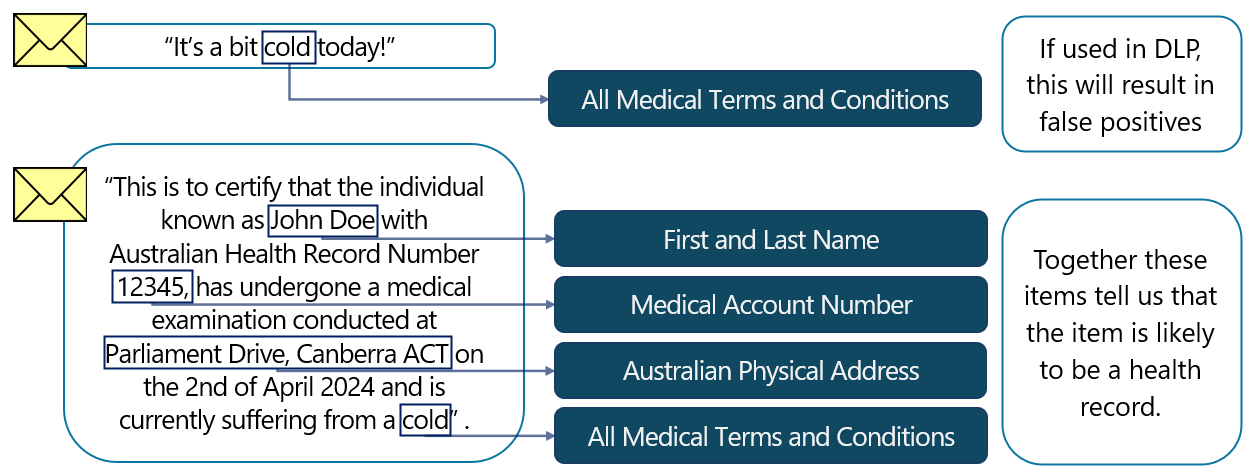
Benannte Entitäts-SITs können mit benutzerdefinierten SITs gekoppelt, als unterstützende Elemente verwendet oder sogar in anderen SITs in DLP-Richtlinien enthalten sein.
Weitere Informationen zu benannten Entitäts-SITs finden Sie unter Informationen zu benannten Entitäten.
Genaue Daten stimmen mit vertraulichen Informationstypen überein
EDM-SITs (Exact Data Match) werden basierend auf tatsächlichen Daten generiert. Numerische Werte, z. B. numerische Kunden-IDs, sind aufgrund von Konflikten mit anderen numerischen Werten wie Telefonnummern schwer über Standard-SITs abzugleichen. Unterstützende Elemente verbessern den Abgleich, um falsch positive Ergebnisse zu reduzieren.
Exact Data Match hilft australischen Regierungsorganisationen, die über Systeme verfügen, die Daten zu Mitarbeitern, Kunden oder Bürgern enthalten, um diese Informationen genau zu identifizieren.
Weitere Informationen zum Implementieren von EDM-SITs finden Sie unter Informationen zu genauen Datenübereinstimmungen basierenden Typen vertraulicher Informationen.
Dokumentfingerabdrücke
Das Dokumentfingerabdruck ist eine Informationsidentifikationsmethode, bei der statt nach Werten zu suchen, die in einem Element enthalten sind, sondern das Format und die Struktur des Elements untersucht. Im Wesentlichen ermöglicht dies die Konvertierung eines Standardformulars in einen vertraulichen Informationstyp, der zum Identifizieren von Informationen verwendet werden kann.
Regierungsorganisationen können die Dokumentfingerabdrücke zur Identifizierung von Inhalten verwenden, um Elemente zu identifizieren, die über einen Workflow oder Formulare generiert wurden, die von anderen Organisationen oder Mitgliedern der Öffentlichkeit übermittelt wurden.
Informationen zum Implementieren des Dokumentfingerabdrucks finden Sie unter Dokumentfingerabdrücke.
Netzwerk- oder sicherheitsbezogene Typen vertraulicher Informationen
Es gibt zahlreiche Verwendungsmöglichkeiten für SITs, die über die Identifizierung von sicherheitsrelevanten oder anderweitig vertraulichen Informationen hinausgehen. Eine solche Verwendung ist die Erkennung von Anmeldeinformationen. Vordefinierte SITs werden für die folgenden Anmeldeinformationstypen bereitgestellt:
- Anmeldeinformationen für Benutzer
- Microsoft Entra ID Clientzugriffstoken
- Azure Batch gemeinsam genutzter Zugriffsschlüssel
- Shared Access Signatures für das Azure Storage-Konto
- Geheimer Clientschlüssel/API-Schlüssel
Diese vordefinierten SITs werden unabhängig voneinander verwendet und auch in einer SIT namens Alle Anmeldeinformationengebündelt. Die SIT für alle Anmeldeinformationen ist nützlich für Cyber-Teams, die sie in:
- DLP-Richtlinien zum Identifizieren und Verhindern von Lateral Movements durch böswillige Benutzer oder externe Angreifer.
- Richtlinien für automatische Bezeichnungen, um Verschlüsselung auf Elemente anzuwenden, die keine Anmeldeinformationen enthalten dürfen, Sperren von Benutzern aus Dateien und zulassen, dass Korrekturaktionen gestartet werden können.
- DLP-Richtlinien, um zu verhindern, dass Benutzer ihre Anmeldeinformationen für andere Benutzer für organization-Richtlinien freigeben.
- Hervorheben von Elementen, die an SharePoint- oder Exchange-Speicherorten gespeichert sind und die Informationen zu Anmeldeinformationen nicht ordnungsgemäß aufbewahren.
Vordefinierte SITs sind auch für Netzwerkadressen (sowohl IPv4 als auch IPv6) vorhanden und sind nützlich, um Elemente zu schützen, die Netzwerkinformationen enthalten, oder um zu verhindern, dass Benutzer IP-Adressen per E-Mail, Teams-Chat oder Kanalnachrichten freigeben können.
Trainierbare Klassifizierer
Trainierbare Klassifizierer sind Machine Learning-Modelle, die trainiert werden können, um vertrauliche Informationen zu erkennen. Wie siTs stellt Microsoft vortrainierte Klassifizierer bereit. In der folgenden Tabelle ist ein Auszug der vortrainierten Klassifizierer aufgeführt, die für australische Regierungsorganisationen relevant sind:
| Klassifiziererkategorie | Beispiel für trainierbare Klassifizierer |
|---|---|
| Finanzen | Kontoauszüge, Budget, Finanzprüfungsberichte, Finanzausweise, Steuern, Rechnungsführung, Budgetschätzungen (BE), Geschäftsaktivitätsrechnung (BAS). |
| Business | Betriebsverfahren, Geheimhaltungsvereinbarungen, Beschaffung, Projektcodewörter, Senatsschätzungen (SE), Fragen zur Mitteilung (QoNs). |
| Personalwesen | Lebensläufe, Mitarbeiter disziplinarische Aktionsdateien, Arbeitsvertrag, Genehmigungen der australian Government Security Vetting Agency (AGSVA), Hochschulkreditprogramm (HELP), Militär-ID, Foreign Work Authorization (FWA). |
| Medizinisch | Gesundheitswesen, medizinische Formulare, MyHealth Record. |
| Rechtliche Hinweise | Rechtliche Angelegenheiten, Vereinbarungen, Lizenzverträge. |
| Technisch | Softwareentwicklungsdateien, Projektdokumente, Netzwerkentwurfsdateien. |
| Verhalten | Anstößige Sprache, Obszönitäten, Bedrohung, gezielte Belästigung, Diskriminierung, regulatorische Absprachen, Kundenbeschwerde. |
Einige Beispiele dafür, wie Regierungsorganisationen diese vordefinierten Klassifizierer verwenden können, sind:
- Geschäftsregeln können vorschreiben, dass einige Elemente in der Personalkategorie, z. B. Lebensläufe, als "OFFICIAL: Sensitive Personal Privacy" gekennzeichnet werden sollen, da sie vertrauliche personenbezogene Informationen enthalten. Für diese Elemente kann eine Bezeichnungsempfehlung über clientbasierte automatische Bezeichnungen konfiguriert werden.
- Netzwerkentwurfsdateien, insbesondere für sichere Netzwerke, sollten sorgfältig behandelt werden, um Gefährdungen zu vermeiden. Diese könnten entweder einer PROTECTED-Bezeichnung oder zumindest DLP-Richtlinien würdig sein, die eine unbefugte Offenlegung an nicht autorisierte Benutzer verhindern.
- Verhaltensklassifizierer sind interessant, und obwohl sie möglicherweise keine direkte Korrelation mit Schutzmarkierungen oder DLP-Anforderungen haben, können sie dennoch einen hohen Geschäftlichen Nutzen haben. Beispielsweise könnten Hr-Teams über Belästigungen benachrichtigt werden und/oder die Möglichkeit erhalten, gekennzeichnete Korrespondenz über Kommunikationscompliance zu überprüfen.
Organisationen können auch ihre eigenen Klassifizierer trainieren. Klassifizierer können trainiert werden, indem sie mit positiven und negativen Stichproben versehen werden. Der Klassifizierer verarbeitet die Beispiele und erstellt ein Vorhersagemodell. Nach Abschluss des Trainings können Klassifizierer für die Anwendung von Vertraulichkeitsbezeichnungen, Kommunikationskonformitätsrichtlinien und Aufbewahrungsbezeichnungsrichtlinien verwendet werden. Die Verwendung von Klassifizierern in DLP-Richtlinien ist in der Vorschau verfügbar.
Weitere Informationen zu trainierbaren Klassifizierern finden Sie unter Informationen zu trainierbaren Klassifizierern.
Verwenden identifizierter vertraulicher Informationen
Sobald Informationen entweder über SIT oder Klassifizierer (über die Datenaspekte von Microsoft Purview kennen) identifiziert wurden, können wir dieses Wissen nutzen, um uns bei der Erfüllung der drei anderen Säulen von Microsoft 365 Information Management zu helfen, nämlich:
- Schützen Sie Ihre Daten,
- Verhindern von Datenverlusten und
- Verwalten Sie Ihre Daten.
Die folgende Tabelle enthält Vorteile und Beispiele dafür, wie das Wissen über ein Element, das vertrauliche Informationen enthält, bei der Verwaltung der Informationen auf der microsoft 365-Plattform helfen kann:
| Funktion | Beispiel für die Verwendung |
|---|---|
| Verhinderung von Datenverlust | Unterstützt die Verwaltung, indem das Risiko von Datenlecks reduziert wird. |
| Vertraulichkeitsbezeichnung | Empfiehlt die Anwendung einer geeigneten Vertraulichkeitsbezeichnung. Nach der Bezeichnung gelten bezeichnungsbezogene Schutzmechanismen für die Informationen. |
| Aufbewahrungsbezeichnung | Wendet automatisch eine Aufbewahrungsbezeichnung an, sodass die Archiv- oder Datensatzverwaltungsanforderungen erfüllt werden können. |
| inhaltsbezogene Explorer | Anzeigen, wo sich Elemente mit vertraulichen Informationen in Microsoft 365-Diensten befinden, einschließlich SharePoint, Teams, OneDrive und Exchange. |
| Insider-Risikomanagement | Überwachen Sie die Benutzeraktivität in Bezug auf vertrauliche Informationen, richten Sie eine Benutzerrisikostufe basierend auf dem Verhalten ein, und eskalieren Sie verdächtiges Verhalten an relevante Teams. |
| Kommunikationscompliance | Sie können die Korrespondenz mit hohem Risiko anzeigen, einschließlich aller Chats oder E-Mails, die vertrauliche oder verdächtige Inhalte enthalten. Die Kommunikationskonformität kann dabei helfen, sicherzustellen, dass die australische Regierung die Verpflichtungen zur Wahrscheinlichkeit erfüllt. |
| Microsoft Priva | Erkennen Sie die Speicherung vertraulicher Informationen, einschließlich personenbezogener Daten an Speicherorten wie OneDrive, und führen Sie Benutzer bei der korrekten Speicherung von Informationen. |
| eDiscovery | Stellen Sie vertrauliche Informationen als Teil von HR- oder FOI-Prozessen bereit, und wenden Sie Haltebereiche auf Informationen an, die Teil einer aktiven Anforderung oder Untersuchung sein könnten. |
inhaltsbezogene Explorer
Microsoft 365 Content Explorer ermöglicht Es Ihren Compliance-, Sicherheits- und Datenschutzbeauftragten, einen schnellen, aber umfassenden Einblick in den Speicherort vertraulicher Informationen in einer Microsoft 365-Umgebung zu erhalten. Dieses Tool ermöglicht autorisierten Benutzern das Durchsuchen von Speicherorten und Elementen nach Informationstyp. Der Dienst indiziert elemente, die sich in Exchange, OneDrive und SharePoint befinden. Elemente, die sich innerhalb von Teams zugrunde liegenden SharePoint-Teamwebsites befinden, sind ebenfalls sichtbar.
Mit diesem Tool können wir einen Vertraulichen Informationstyp oder eine Vertraulichkeitsbezeichnung auswählen und die Anzahl der Elemente anzeigen, die in den einzelnen Microsoft 365-Diensten daran ausgerichtet sind:
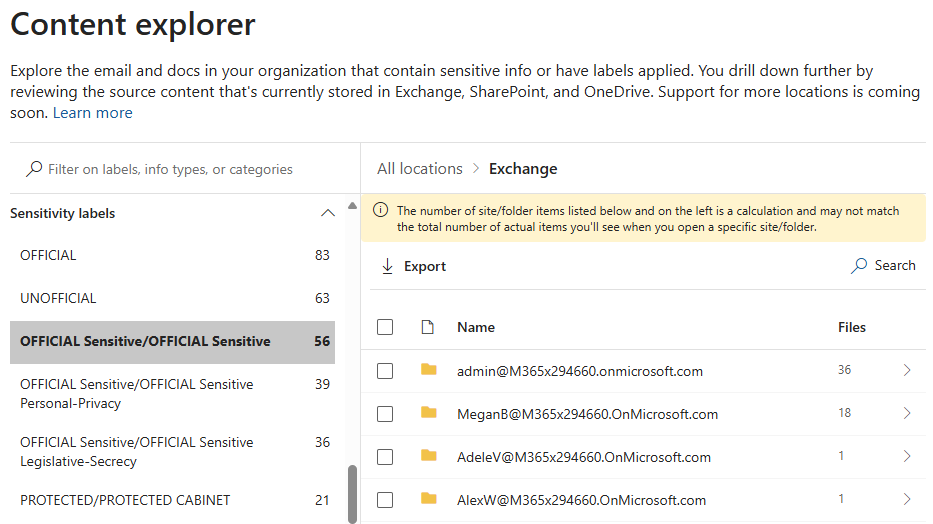
Der Inhalts-Explorer kann wertvolle Einblicke in die Speicherorte liefern, an denen sich sicherheitsrelevante oder anderweitig vertrauliche Elemente in einer Umgebung befinden. Eine solche konsolidierte Sicht auf den Ort der Informationen ist wahrscheinlich nicht über lokale Systeme möglich.
Für Organisationen, die Bezeichnungen einschließen, die im Konto des organization nicht zulässig sind (z. B. SECRET oder TOP SECRET), zusammen mit zugehörigen Richtlinien für die automatische Bezeichnung, um die Bezeichnungen anzuwenden, kann der Inhalts-Explorer Informationen finden, die nicht auf der Plattform gespeichert werden sollten. Da der Inhalts-Explorer auch SITs anzeigen kann, könnte ein ähnlicher Ansatz über SITs zur Identifizierung von Schutzmarkierungen erreicht werden.
Weitere Informationen zu Content Explorer finden Sie unter Erste Schritte mit dem Inhalts-Explorer.