Overfør Hive Metastore-metadata fra Azure Synapse Analytics til Fabric
Det første trin i migreringen af Hive Metastore (HMS) omfatter bestemmelse af de databaser, tabeller og partitioner, du vil overføre. Det er ikke nødvendigt at overføre alt. du kan vælge bestemte databaser. Når du identificerer databaser til migrering, skal du kontrollere, om der er administrerede eller eksterne Spark-tabeller.
Du kan finde HMS-overvejelser i forskellene mellem Azure Synapse Spark og Fabric.
Bemærk
Hvis ADLS Gen2 indeholder Delta-tabeller, kan du også oprette en OneLake-genvej til en Delta-tabel i ADLS Gen2.
Forudsætninger
- Hvis du ikke allerede har et, kan du oprette et Fabric-arbejdsområde i din lejer.
- Hvis du ikke allerede har et, kan du oprette et Fabric lakehouse i dit arbejdsområde.
Mulighed 1: Eksportér og importér HMS til lakehouse-metalager
Følg disse vigtige trin for migrering:
- Trin 1: Eksportér metadata fra kilde-HMS
- Trin 2: Importér metadata til Fabric lakehouse
- Trin efter migrering: Valider indhold
Bemærk
Scripts kopierer kun Spark-katalogobjekter til Fabric lakehouse. Antagelsen er, at dataene allerede er kopieret (f.eks. fra lagerplacering til ADLS Gen2) eller tilgængelige for administrerede og eksterne tabeller (f.eks. via genveje – foretrækkes) til Fabric lakehouse.
Trin 1: Eksportér metadata fra kilde-HMS
I trin 1 fokuseres der på at eksportere metadataene fra kilde HMS til afsnittet Filer i fabric lakehouse. Denne proces er som følger:
1.1) Importér notesbogen til eksport af HMS-metadata til dit Azure Synapse-arbejdsområde. Denne notesbog forespørger og eksporterer HMS-metadata for databaser, tabeller og partitioner til en mellemliggende mappe i OneLake (funktioner er endnu ikke inkluderet). Spark intern katalog-API bruges i dette script til at læse katalogobjekter.
1.2) Konfigurer parametrene i den første kommando for at eksportere metadataoplysninger til et mellemliggende lager (OneLake). Følgende kodestykke bruges til at konfigurere kilde- og destinationsparametrene. Sørg for at erstatte dem med dine egne værdier.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Kør alle notesbøger for at eksportere katalogobjekter til OneLake. Når cellerne er fuldført, oprettes denne mappestruktur under den mellemliggende outputmappe.
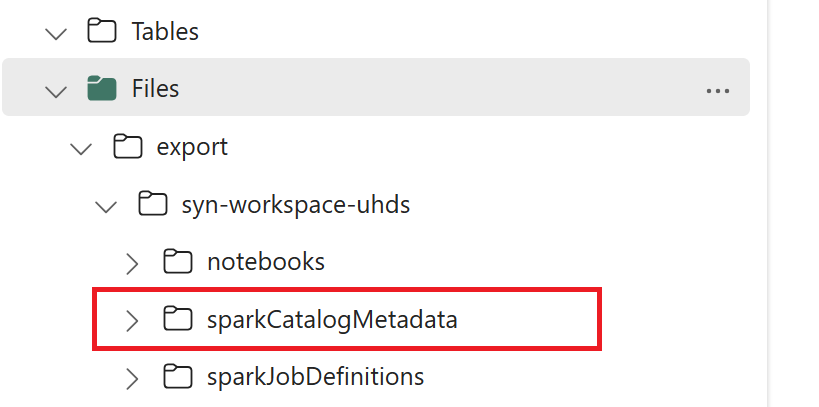
Trin 2: Importér metadata til Fabric lakehouse
Trin 2 er, når de faktiske metadata importeres fra mellemlageret til Fabric lakehouse. Outputtet af dette trin er, at alle HMS-metadata (databaser, tabeller og partitioner) skal migreres. Denne proces er som følger:
2.1) Opret en genvej i afsnittet "Filer" i lakehouse. Denne genvej skal pege på kildens Spark-lagermappe og bruges senere til at erstatte Spark-administrerede tabeller. Se genvejseksempler, der peger på Spark Warehouse-mappe:
- Genvejssti til Azure Synapse Spark-lagermappe:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Genvejssti til Azure Databricks Warehouse-mappe:
dbfs:/mnt/<warehouse_dir> - Genvejssti til HDInsight Spark-lagermappen:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Genvejssti til Azure Synapse Spark-lagermappe:
2.2) Importér notesbogen til import af HMS-metadata til dit Fabric-arbejdsområde. Importér denne notesbog for at importere database-, tabel- og partitionsobjekter fra mellemliggende lager. Spark intern katalog-API bruges i dette script til at oprette katalogobjekter i Fabric.
2.3) Konfigurer parametrene i den første kommando. Når du opretter en administreret tabel i Apache Spark, gemmes dataene for den pågældende tabel på en placering, der administreres af Spark selv, typisk i Sparks lagermappe. Den nøjagtige placering bestemmes af Spark. Dette står i kontrast til eksterne tabeller, hvor du angiver placeringen og administrerer de underliggende data. Når du overfører metadataene for en administreret tabel (uden at flytte de faktiske data), indeholder metadataene stadig de oprindelige placeringsoplysninger, der peger på den gamle Spark Warehouse-mappe. For administrerede tabeller bruges erstatningen derfor ved hjælp af den genvej,
WarehouseMappingsder blev oprettet i trin 2.1. Alle kildeadministrerede tabeller konverteres som eksterne tabeller ved hjælp af dette script.LakehouseIdhenviser til det lakehouse, der blev oprettet i trin 2.1, og som indeholder genveje.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Kør alle notesbøger for at importere katalogobjekter fra mellemliggende sti.
Bemærk
Når du importerer flere databaser, kan du (i) oprette én lakehouse pr. database (den fremgangsmåde, der bruges her) eller (ii) flytte alle tabeller fra forskellige databaser til et enkelt lakehouse. For sidstnævnte kan alle migrerede tabeller være <lakehouse>.<db_name>_<table_name>, og du skal justere importnotesbogen tilsvarende.
Trin 3: Valider indhold
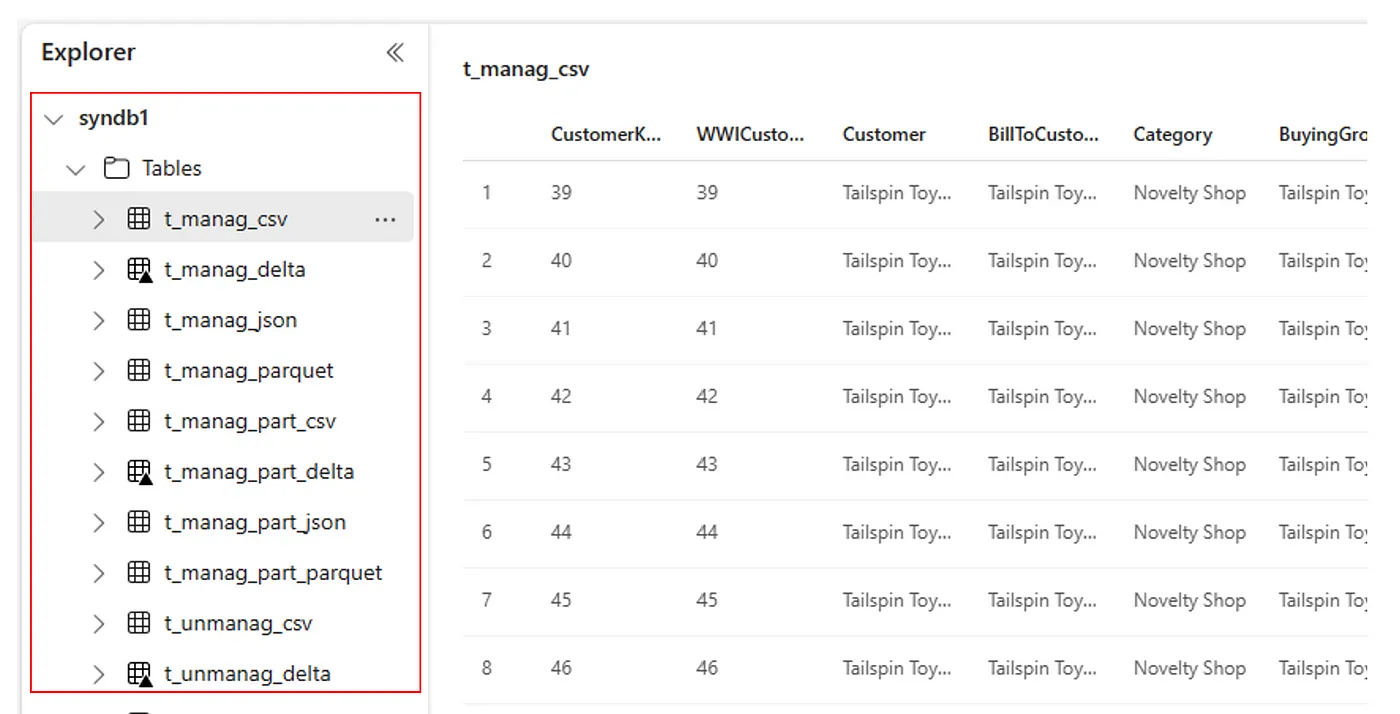
Trin 3 er det sted, hvor du validerer, at metadata er blevet overført korrekt. Se forskellige eksempler.
Du kan se de databaser, der er importeret, ved at køre:
%%sql
SHOW DATABASES
Du kan kontrollere alle tabeller i et lakehouse (database) ved at køre:
%%sql
SHOW TABLES IN <lakehouse_name>
Du kan se detaljerne for en bestemt tabel ved at køre:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
Alternativt kan du se alle importerede tabeller i afsnittet Tabeller for brugergrænsefladen i Lakehouse Explorer for hvert lakehouse.
Andre overvejelser
- Skalerbarhed: Løsningen her bruger intern Spark-katalog-API til import/eksport, men den opretter ikke direkte forbindelse til HMS for at hente katalogobjekter, så løsningen kunne ikke skaleres godt, hvis kataloget er stort. Du skal ændre eksportlogikken ved hjælp af HMS DB.
- Datanøjagtighed: Der er ingen isolationsgaranti, hvilket betyder, at hvis Spark-beregningsprogrammet foretager samtidige ændringer af metalageret, mens migreringsnotesbogen kører, kan der introduceres inkonsekvente data i Fabric lakehouse.
Relateret indhold
- Fabric vs. Azure Synapse Spark
- Få mere at vide om overførselsindstillinger for Spark-puljer, konfigurationer, biblioteker, notesbøger og Spark-jobdefinition