Overfør Spark-puljer fra Azure Synapse Analytics til Fabric
Mens Azure Synapse leverer Spark-puljer, tilbyder Fabric Starter-puljer og brugerdefinerede puljer. Startpuljen kan være et godt valg, hvis du har en enkelt pulje uden brugerdefinerede konfigurationer eller biblioteker i Azure Synapse, og hvis den mellemste nodestørrelse opfylder dine krav. Men hvis du søger mere fleksibilitet med dine Spark-puljekonfigurationer, anbefaler vi, at du bruger brugerdefinerede puljer. Der er to muligheder her:
- Mulighed 1: Flyt din Spark-pulje til et arbejdsområdes standardgruppe.
- Mulighed 2: Flyt din Spark-pool til et brugerdefineret miljø i Fabric.
Hvis du har mere end én Spark-pulje, og du planlægger at flytte dem til det samme Fabric-arbejdsområde, anbefaler vi, at du bruger Mulighed 2 og opretter flere brugerdefinerede miljøer og puljer.
Se forskellene mellem Azure Synapse Spark og Fabric for at få oplysninger om Spark-puljen.
Forudsætninger
Hvis du ikke allerede har et, kan du oprette et Fabric-arbejdsområde i din lejer.
Mulighed 1: Fra Spark-pulje til arbejdsområdets standardpulje
Du kan oprette en brugerdefineret Spark-pulje fra dit Fabric-arbejdsområde og bruge den som standardgruppe i arbejdsområdet. Standardgruppen bruges af alle notesbøger og Spark-jobdefinitioner i det samme arbejdsområde.
Sådan flytter du fra en eksisterende Spark-pulje fra Azure Synapse til en standardgruppe for arbejdsområdet:
- Få adgang til Azure Synapse-arbejdsområdet: Log på Azure. Gå til dit Azure Synapse-arbejdsområde, gå til Analysepuljer , og vælg Apache Spark-puljer.
- Find Spark-puljen: Fra Apache Spark-bassinerne skal du finde den Spark-pool, du vil flytte til Fabric, og kontrollere egenskaberne for puljen.
- Hent egenskaber: Hent egenskaber for Spark-puljen, f.eks. Apache Spark-version, nodestørrelsesfamilie, nodestørrelse eller automatisk skalering. Se Overvejelser i Spark-puljen for at se eventuelle forskelle.
-
Opret en brugerdefineret Spark-pool i Fabric:
- Gå til dit Fabric-arbejdsområde , og vælg Indstillinger for arbejdsområde.
- Gå til Dataudvikler ing/Videnskab, og vælg Spark-indstillinger.
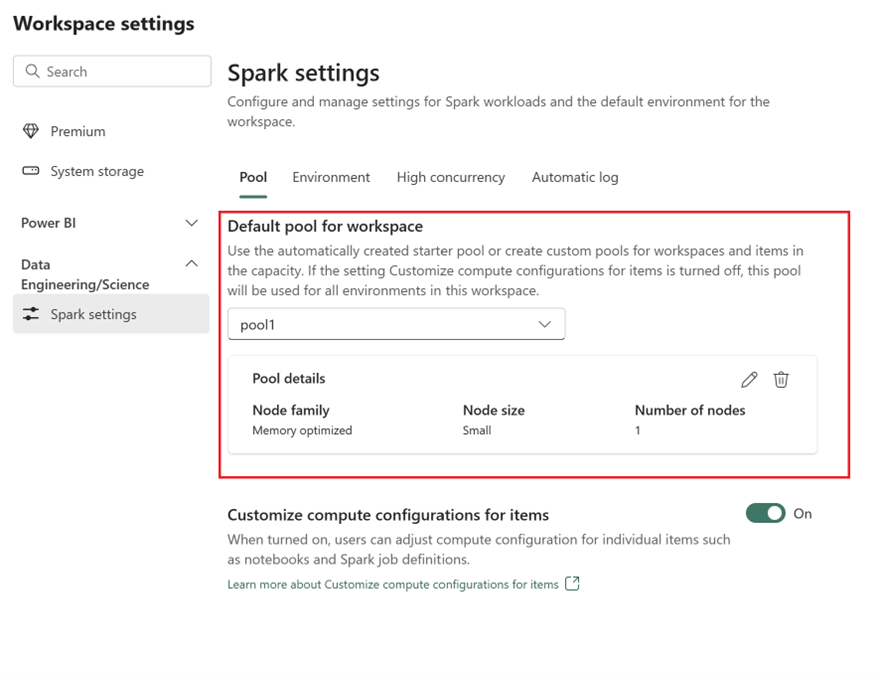
- Under fanen Pulje og i afsnittet Standardgruppe for arbejdsområde skal du udvide rullemenuen og vælge Opret ny pulje.
- Opret din brugerdefinerede pulje med de tilsvarende målværdier. Udfyld navnet, nodefamilien, nodestørrelsen, automatisk skalering og dynamiske indstillinger for allokering af eksekvering.
-
Vælg en kørselsversion:
- Gå til fanen Miljø , og vælg den påkrævede kørselsversion. Se tilgængelige runtimes her.
- Deaktiver indstillingen Angiv standardmiljø .
Bemærk
I denne indstilling understøttes biblioteker eller konfigurationer på gruppeniveau ikke. Du kan dog justere beregningskonfigurationen for individuelle elementer, f.eks. notesbøger og Spark-jobdefinitioner, og tilføje indbyggede biblioteker. Hvis du har brug for at føje brugerdefinerede biblioteker og konfigurationer til et miljø, skal du overveje et brugerdefineret miljø.
Mulighed 2: Fra Spark-pulje til brugerdefineret miljø
Med brugerdefinerede miljøer kan du konfigurere brugerdefinerede Spark-egenskaber og -biblioteker. Sådan opretter du et brugerdefineret miljø:
- Få adgang til Azure Synapse-arbejdsområdet: Log på Azure. Gå til dit Azure Synapse-arbejdsområde, gå til Analysepuljer , og vælg Apache Spark-puljer.
- Find Spark-puljen: Fra Apache Spark-bassinerne skal du finde den Spark-pool, du vil flytte til Fabric, og kontrollere egenskaberne for puljen.
- Hent egenskaber: Hent egenskaber for Spark-puljen, f.eks. Apache Spark-version, nodestørrelsesfamilie, nodestørrelse eller automatisk skalering. Se Overvejelser i Spark-puljen for at se eventuelle forskelle.
-
Opret en brugerdefineret Spark-pulje:
- Gå til dit Fabric-arbejdsområde , og vælg Indstillinger for arbejdsområde.
- Gå til Dataudvikler ing/Videnskab, og vælg Spark-indstillinger.
- Under fanen Pulje og i afsnittet Standardgruppe for arbejdsområde skal du udvide rullemenuen og vælge Opret ny pulje.
- Opret din brugerdefinerede pulje med de tilsvarende målværdier. Udfyld navnet, nodefamilien, nodestørrelsen, automatisk skalering og dynamiske indstillinger for allokering af eksekvering.
- Opret et miljøelement , hvis du ikke har et.
-
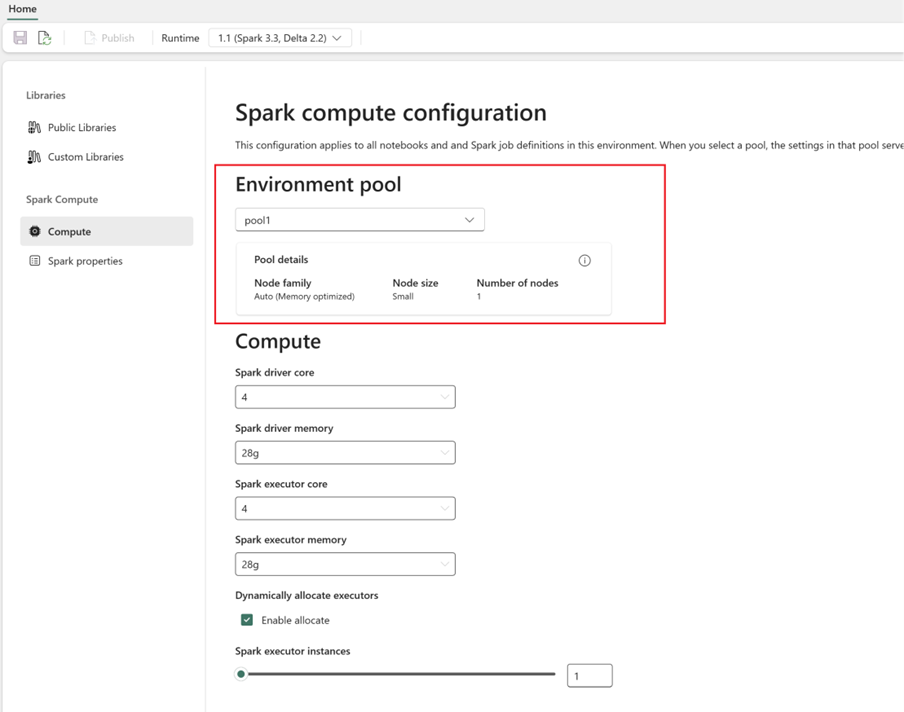
Konfigurer Spark-beregning:
- I miljøet skal du gå til Spark Compute>.
- Vælg den nyoprettede pulje for det nye miljø.
- Du kan konfigurere driver- og eksekveringskerner og hukommelse.
- Vælg en kørselsversion for miljøet. Se tilgængelige runtimes her.
- Klik på Gem og udgiv ændringer.
Få mere at vide om oprettelse og brug af et miljø.