Overfør Spark-jobdefinition fra Azure Synapse til Fabric
Hvis du vil flytte Spark-jobdefinitioner (SJD) fra Azure Synapse til Fabric, har du to forskellige muligheder:
- Mulighed 1: Opret definitionen af Spark-job manuelt i Fabric.
- Mulighed 2: Du kan bruge et script til at eksportere Spark-jobdefinitioner fra Azure Synapse og importere dem i Fabric ved hjælp af API'en.
Du kan finde flere oplysninger om definition af Spark-job i forskelle mellem Azure Synapse Spark og Fabric.
Forudsætninger
Hvis du ikke allerede har et, kan du oprette et Fabric-arbejdsområde i din lejer.
Mulighed 1: Opret definitionen af Spark-job manuelt
Sådan eksporterer du en Spark-jobdefinition fra Azure Synapse:
- Åbn Synapse Studio: Log på Azure. Gå til dit Azure Synapse-arbejdsområde, og åbn Synapse Studio.
- Find Python/Scala/R Spark-jobbet: Find og identificer den Python/Scala/R Spark-jobdefinition, du vil overføre.
-
Eksportér jobdefinitionskonfigurationen:
- Åbn Spark Job Definition i Synapse Studio.
- Eksportér eller notér konfigurationsindstillingerne, herunder placeringen af scriptfilen, afhængigheder, parametre og andre relevante oplysninger.
Sådan opretter du en ny Spark-jobdefinition (SJD) baseret på de eksporterede SJD-oplysninger i Fabric:
- Access Fabric-arbejdsområde: Log på Fabric , og få adgang til dit arbejdsområde.
-
Opret en ny Spark-jobdefinition i Fabric:
- I Fabric skal du gå til startsiden for Dataudvikler.
- Vælg Spark-jobdefinition.
- Konfigurer jobbet ved hjælp af de oplysninger, du eksporterede fra Synapse, herunder scriptplacering, afhængigheder, parametre og klyngeindstillinger.
- Tilpas og test: Foretag den nødvendige tilpasning til scriptet eller konfigurationen, så den passer til Fabric-miljøet. Test jobbet i Fabric for at sikre, at det kører korrekt.
Når definitionen af Spark-job er oprettet, skal du validere afhængigheder:
- Sørg for at bruge den samme Spark-version.
- Valider, at hoveddefinitionsfilen findes.
- Valider eksistensen af de filer, afhængigheder og ressourcer, der refereres til.
- Sammenkædede tjenester, datakildeforbindelser og tilslutningspunkter.
Få mere at vide om, hvordan du opretter en Apache Spark-jobdefinition i Fabric.
Mulighed 2: Brug Fabric-API'en
Følg disse vigtige trin for migrering:
- Forudsætninger.
- Trin 1: Eksportér Spark-jobdefinition fra Azure Synapse til OneLake (.json).
- Trin 2: Importér automatisk Spark-jobdefinitionen til Fabric ved hjælp af Fabric-API'en.
Forudsætninger
Forudsætningerne omfatter handlinger, du skal overveje, før du starter migreringen af Spark-jobdefinitionen til Fabric.
- Et Fabric-arbejdsområde.
- Hvis du ikke allerede har et, kan du oprette et Fabric lakehouse i dit arbejdsområde.
Trin 1: Eksportér Spark-jobdefinition fra Azure Synapse-arbejdsområdet
I trin 1 fokuseres der på eksport af Spark-jobdefinition fra Azure Synapse-arbejdsområdet til OneLake i json-format. Denne proces er som følger:
- 1.1) Importér SJD-migreringsnotesbog til Fabric-arbejdsområdet . Denne notesbog eksporterer alle Spark-jobdefinitioner fra et givet Azure Synapse-arbejdsområde til en mellemliggende mappe i OneLake. Synapse API bruges til at eksportere SJD.
- 1.2) Konfigurer parametrene i den første kommando for at eksportere Definitionen af Spark-job til et mellemliggende lager (OneLake). Dette eksporterer kun json-metadatafilen. Følgende kodestykke bruges til at konfigurere kilde- og destinationsparametrene. Sørg for at erstatte dem med dine egne værdier.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
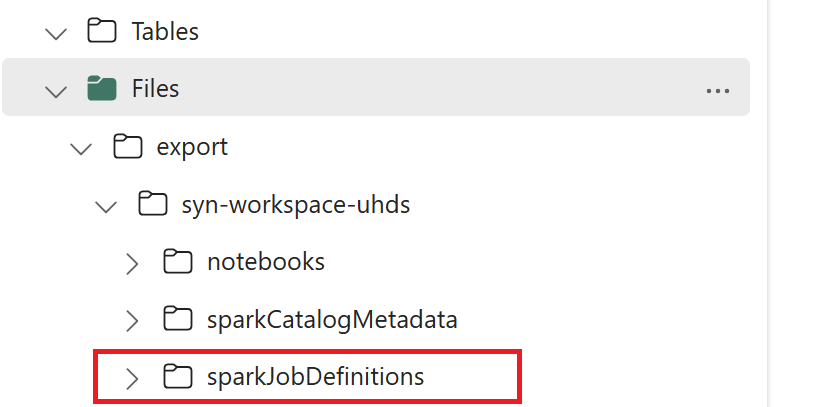
- 1.3) Kør de første to celler i eksport-/importnotesbogen for at eksportere metadata for Spark-jobdefinitionen til OneLake. Når cellerne er fuldført, oprettes denne mappestruktur under den mellemliggende outputmappe.
Trin 2: Importér Spark-jobdefinition til Fabric
Trin 2 er, når Spark-jobdefinitioner importeres fra mellemlageret til Fabric-arbejdsområdet. Denne proces er som følger:
- 2.1) Valider konfigurationerne i 1.2 for at sikre, at det rigtige arbejdsområde og præfiks er angivet til at importere Spark-jobdefinitionerne.
- 2.2) Kør den tredje celle i eksport-/importnotesbogen for at importere alle Spark-jobdefinitioner fra den mellemliggende placering.
Bemærk
Eksportindstillingen opretter en json-metadatafil. Sørg for, at eksekverbare filer, referencefiler og argumenter i Spark-jobdefinitionen er tilgængelige fra Fabric.