Kurz: Zjišťování relací v sémantickém modelu pomocí sémantického odkazu
Tento kurz ukazuje, jak pracovat s Power BI z poznámkového bloku Jupyter a zjišťovat relace mezi tabulkami pomocí knihovny SemPy.
V tomto kurzu se naučíte:
- Objevte relace v sémantickém modelu (datová sada Power BI) pomocí sémantické knihovny Pythonu (SemPy).
- Používejte komponenty SemPy, které podporují integraci s Power BI a pomáhají automatizovat analýzu kvality dat. Mezi tyto komponenty patří:
- FabricDataFrame – struktura podobná pandas, rozšířená o další sémantické informace.
- Funkce pro načítání sémantických modelů z pracovního prostoru Fabric do poznámkového bloku
- Funkce, které automatizují vyhodnocení hypotéz o funkčních závislostech a identifikují porušení vztahů v sémantických modelech.
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače v levém dolním rohu domovské stránky přepněte na Fabric.

V levém navigačním podokně vyberte Pracovní prostory a vyhledejte a vyberte pracovní prostor. Tento pracovní prostor se stane vaším aktuálním pracovním prostorem.
Stáhněte si sémantické modely Customer Profitability Sample.pbix a Customer Profitability Sample (auto).pbix z úložiště fabric-samples na GitHubu a nahrajte je do svého pracovního prostoru.
Sledujte postup v poznámkovém bloku
Tento kurz doprovází poznámkový blok powerbi_relationships_tutorial.ipynb.
Pokud chcete otevřít doprovodný poznámkový blok k tomuto kurzu, postupujte podle pokynů v části Příprava systému na kurzy datové vědy a importujte poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Nastavení poznámkového bloku
V této části nastavíte prostředí poznámkového bloku s potřebnými moduly a daty.
Nainstalujte
SemPyz PyPI pomocí funkce%pipin-line instalace v poznámkovém bloku:%pip install semantic-linkProveďte nezbytné importy modulů SemPy, které budete potřebovat později:
import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsNaimportujte knihovnu pandas pro uplatnění konfigurační volby, která pomáhá s formátováním výstupu:
import pandas as pd pd.set_option('display.max_colwidth', None)
Prozkoumání sémantických modelů
Tento kurz používá standardní ukázkový sémantický model Customer Profitability Sample.pbix. Popis sémantického modelu najdete v ukázce ziskovosti zákazníků pro power BI.
Pomocí funkce
list_datasetsSemPy můžete prozkoumat sémantické modely v aktuálním pracovním prostoru:fabric.list_datasets()
Pro zbytek tohoto poznámkového bloku použijete dvě verze sémantického modelu Customer Profitability Sample:
- Ukázka ziskovosti zákazníků: sémantický model pocházející z ukázek Power BI s předdefinovanými relacemi mezi tabulkami
- Vzorek ziskovosti zákazníků (auto): stejná data, ale relace jsou omezené na ty, které by Power BI automaticky detekoval.
Extrahování ukázkového sémantického modelu s předdefinovaným sémantickým modelem
Načíst relace, které jsou předdefinovány a uloženy v sémantickém modelu Customer Profitability Sample, pomocí funkce
list_relationshipsSemPy. Tato funkce obsahuje seznam z tabulkového objektového modelu:dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVizualizujte datový rámec
relationshipsjako graf pomocíplot_relationship_metadatafunkce SemPy:plot_relationship_metadata(relationships)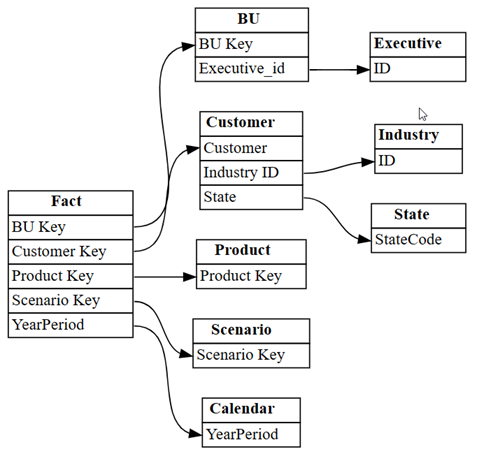

Tento graf ukazuje "základní pravdu" pro relace mezi tabulkami v tomto sémantickém modelu, protože odráží, jak byly definovány v Power BI odborníkem na danou problematiku.
Objevování doplňkových vztahů
Pokud jste začali s relacemi, které Power BI automaticky detekovaly, měla byste menší sadu.
Vizualizujte relace, které Power BI automaticky rozdetekoval v sémantickém modelu:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)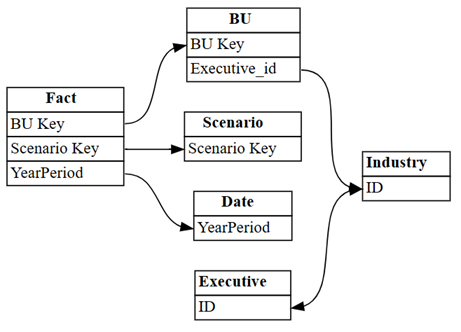
Automatické rozpoznávání Power BI zmeškalo mnoho relací. Kromě toho jsou dvě automaticky rozdetekované relace sémanticky nesprávné:
-
Executive[ID]–>Industry[ID] -
BU[Executive_id]–>Industry[ID]
-
Vytiskněte relace jako tabulku:
autodetectedV řádcích s indexem 3 a 4 se zobrazí nesprávné relace s tabulkou
Industry. Pomocí těchto informací odeberte tyto řádky.Zahoďte nesprávně identifikované relace.
autodetected.drop(index=[3,4], inplace=True) autodetectedTeď máte správné, ale neúplné vztahy.
Vizualizujte tyto neúplné relace pomocí
plot_relationship_metadata:plot_relationship_metadata(autodetected)
Načtěte všechny tabulky ze sémantického modelu pomocí funkcí
list_tablesaread_tablez nástroje SemPy.tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Najděte relace mezi tabulkami pomocí
find_relationshipsa prohlédněte si výstup protokolu, abyste získali přehled o tom, jak tato funkce funguje:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Vizualizace nově zjištěných relací:
plot_relationship_metadata(suggested_relationships_all)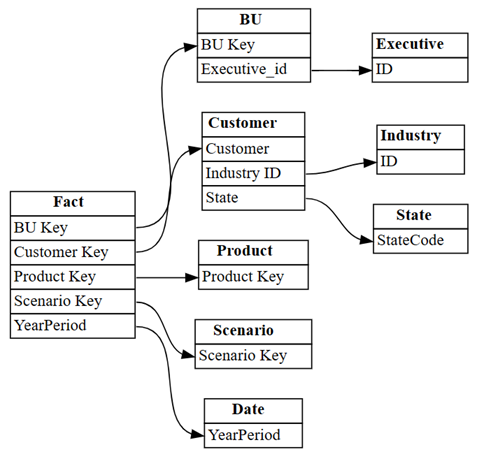
SemPy dokázal rozpoznat všechny relace.
Pomocí parametru
excludeomezte vyhledávání na další relace, které nebyly dříve identifikovány:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Ověření relací
Nejprve načtěte data ze sémantického modelu Ukázka ziskovosti zákazníků.
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Pomocí funkce
list_relationship_violationszkontrolujte, jestli se hodnoty primárního a cizího klíče překrývají. Zadejte výstup funkcelist_relationshipsjako vstup dolist_relationship_violations:list_relationship_violations(tables, fabric.list_relationships(dataset))Porušení vztahů poskytují zajímavé přehledy. Například jedna ze sedmi hodnot v
Fact[Product Key]není vProduct[Product Key]přítomna a tento chybějící klíč je50.
Průzkumná analýza dat je vzrušující proces, a také je čištění dat. Vždy existuje něco, co data skrývají, v závislosti na tom, jak se na ně díváte, na co se chcete zeptat a podobně. Sémantický odkaz poskytuje nové nástroje, které můžete použít k dosažení větších výsledků s vašimi daty.
Související obsah
Podívejte se na další kurzy pro sémantický odkaz / SemPy:
- kurz : Vyčištění dat pomocí funkčních závislostí
- kurz : Analýza funkčních závislostí v ukázkovém sémantickém modelu
- Kurz : Extrahování a výpočet měr Power BI z poznámkového bloku Jupyter
- kurz : Zjišťování relací v datové sadě Synthea pomocí sémantických odkazů
- Tutoriál: Ověřování dat pomocí SemPy a Great Expectations (GX)