Kurz: Ověření dat pomocí semPy a velkých očekávání (GX)
V tomto kurzu se naučíte používat SemPy společně s Great Expectations (GX) k provádění ověřování dat v sémantických modelech Power BI.
V tomto kurzu se dozvíte, jak:
- Ověřte omezení v datové sadě ve vašem Fabric pracovním prostoru pomocí zdroje dat Fabric od Great Expectation (postaveného na sémantickém propojení).
- Nakonfigurujte kontext dat GX, datové prostředky a očekávání.
- Zobrazte výsledky ověření pomocí kontrolního bodu GX.
- Pomocí sémantického odkazu můžete analyzovat nezpracovaná data.
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače prostředí vlevo dole na své domovské stránce přepněte na Fabric.

- V levém navigačním podokně vyberte Pracovní prostory a vyhledejte a vyberte pracovní prostor. Tento pracovní prostor se stane vaším aktuálním pracovním prostorem.
- Stáhněte si soubor Retail Analysis Sample PBIX.pbix.
- V pracovním prostoru vyberte Importovat>sestavu nebo stránkovanou sestavu>Z tohoto počítače pro nahrání souboru Ukázka analýzy maloobchodního prodeje PBIX.pbix do vašeho pracovního prostoru.
Sledujte v poznámkovém bloku
great_expectations_tutorial.ipynb je poznámkový blok, který doprovází tento kurz.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v tématu Příprava systému na kurzy datových věd a naimportujte poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Nastavení poznámkového bloku
V této části nastavíte prostředí poznámkového bloku s potřebnými moduly a daty.
- Nainstalujte
SemPya příslušné knihovnyGreat Expectationsz PyPI pomocí%pipmožnosti instalace v rámci poznámkového bloku.
# install libraries
%pip install semantic-link 'great-expectations<1.0' great_expectations_experimental great_expectations_zipcode_expectations
# load %%dax cell magic
%load_ext sempy
- Proveďte nezbytné importy modulů, které budete potřebovat později:
import great_expectations as gx
from great_expectations.expectations.expectation import ExpectationConfiguration
from great_expectations_zipcode_expectations.expectations import expect_column_values_to_be_valid_zip5
Nastavení kontextu dat GX a zdroje dat
Abyste mohli začít pracovat s Great Expectations, musíte nejprve nastavit GX Data Context. Kontext slouží jako vstupní bod pro operace GX a obsahuje všechny relevantní konfigurace.
context = gx.get_context()
Teď můžete datovou sadu Fabric přidat do tohoto kontextu jako zdroj dat, abyste mohli začít s daty pracovat. Tento kurz používá standardní sémantický model Power BI na ukázkovém souboru analýzy maloobchodního prodeje Retail Analysis Sample .pbix.
ds = context.sources.add_fabric_powerbi("Retail Analysis Data Source", dataset="Retail Analysis Sample PBIX")
Určete datové prostředky
Definujte datové prostředky, abyste určili podmnožinu dat, se kterými chcete pracovat. Prostředek může být buď jednoduchý, jako jsou úplné tabulky, nebo složitý, jako je vlastní dotaz DAX (Data Analysis Expressions).
Tady přidáte více aktiv:
- Tabulka Power BI
- Míra Power BI
- Vlastní dotaz DAX
- Dotaz zobrazení dynamické správy (DMV)
Tabulka Power BI
Přidejte tabulku Power BI jako datový prostředek.
ds.add_powerbi_table_asset("Store Asset", table="Store")
Ukazatel Power BI
Pokud vaše datová sada obsahuje předkonfigurované míry, přidáte míry jako objekty podle podobného rozhraní API jako SemPy evaluate_measure.
ds.add_powerbi_measure_asset(
"Total Units Asset",
measure="TotalUnits",
groupby_columns=["Time[FiscalYear]", "Time[FiscalMonth]"]
)
DAX
Pokud chcete definovat vlastní míry nebo mít větší kontrolu nad konkrétními řádky, můžete přidat DAX objekt s vlastním DAX dotazem. V této části definujeme Total Units Ratio míru rozdělením dvou existujících měr.
ds.add_powerbi_dax_asset(
"Total Units YoY Asset",
dax_string=
"""
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
"""
)
Dotaz na DMV
V některých případech může být užitečné použít výpočty dynamického zobrazení správy (DMV) v rámci procesu ověření dat. Můžete například sledovat počet porušení referenční integrity v datové sadě. Další informace najdete v tématu Vyčištění dat = rychlejší sestavy.
ds.add_powerbi_dax_asset(
"Referential Integrity Violation",
dax_string=
"""
SELECT
[Database_name],
[Dimension_Name],
[RIVIOLATION_COUNT]
FROM $SYSTEM.DISCOVER_STORAGE_TABLES
"""
)
Očekávání
Pokud chcete do prostředků přidat konkrétní omezení, musíte nejprve nakonfigurovat Expectation Suites. Po přidání jednotlivých očekávání do každé sady pak můžete aktualizovat kontext dat nastavený na začátku novou sadou. Úplný seznam dostupných očekávání najdete v galerii očekávání GX.
Začněte přidáním sady maloobchodních obchodů se dvěma očekáváními:
- platné PSČ
- tabulka s počtem řádků mezi 80 a 200
suite_store = context.add_expectation_suite("Retail Store Suite")
suite_store.add_expectation(ExpectationConfiguration("expect_column_values_to_be_valid_zip5", { "column": "PostalCode" }))
suite_store.add_expectation(ExpectationConfiguration("expect_table_row_count_to_be_between", { "min_value": 80, "max_value": 200 }))
context.add_or_update_expectation_suite(expectation_suite=suite_store)
TotalUnits míra
Přidejte "sadu maloobchodních měřítek" s jedním očekáváním:
- Hodnoty sloupců by měly být větší než 50 000.
suite_measure = context.add_expectation_suite("Retail Measure Suite")
suite_measure.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "TotalUnits",
"min_value": 50000
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_measure)
Total Units Ratio DAX
Přidejte "Retail DAX Suite" s jedním očekáváním:
- Hodnoty sloupců pro celkový poměr jednotek by měly být mezi 0,8 a 1,5
suite_dax = context.add_expectation_suite("Retail DAX Suite")
suite_dax.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "[Total Units Ratio]",
"min_value": 0.8,
"max_value": 1.5
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dax)
Porušení referenční integrity (DMV)
Přidejte "Retail DMV Suite" s jednou podmínkou:
- hodnota RIVIOLATION_COUNT by měla být 0
suite_dmv = context.add_expectation_suite("Retail DMV Suite")
# There should be no RI violations
suite_dmv.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_in_set",
{
"column": "RIVIOLATION_COUNT",
"value_set": [0]
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dmv)
Validace
Pokud chcete skutečně spustit zadaná očekávání vůči datům, nejprve vytvořte Kontrolní bod a přidejte je do kontextu. Další informace o konfiguraci kontrolního bodu naleznete v tématu pracovní postup ověření dat.
checkpoint_config = {
"name": f"Retail Analysis Checkpoint",
"validations": [
{
"expectation_suite_name": "Retail Store Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Store Asset",
},
},
{
"expectation_suite_name": "Retail Measure Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units Asset",
},
},
{
"expectation_suite_name": "Retail DAX Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units YoY Asset",
},
},
{
"expectation_suite_name": "Retail DMV Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Referential Integrity Violation",
},
},
],
}
checkpoint = context.add_checkpoint(
**checkpoint_config
)
Teď spusťte kontrolní bod a extrahujte výsledky jako datový rámec pandas pro jednoduché formátování.
result = checkpoint.run()
Zpracujte a vytiskněte výsledky.
import pandas as pd
data = []
for run_result in result.run_results:
for validation_result in result.run_results[run_result]["validation_result"]["results"]:
row = {
"Batch ID": run_result.batch_identifier,
"type": validation_result.expectation_config.expectation_type,
"success": validation_result.success
}
row.update(dict(validation_result.result))
data.append(row)
result_df = pd.DataFrame.from_records(data)
result_df[["Batch ID", "type", "success", "element_count", "unexpected_count", "partial_unexpected_list"]]

Z těchto výsledků vidíte, že všechna vaše očekávání prošla ověřením, s výjimkou "Total Units YoY Asset", který jste definovali pomocí vlastního dotazu DAX.
Diagnostika
Pomocí sémantického propojení můžete načíst zdrojová data, abyste pochopili, které přesné roky jsou mimo rozsah. Sémantický odkaz poskytuje vložené kouzlo pro spouštění dotazů DAX. Pomocí sémantického odkazu spusťte stejný dotaz, který jste předali do datového prostředku GX, a vizualizujte výsledné hodnoty.
%%dax "Retail Analysis Sample PBIX"
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
Uložte tyto výsledky do datového rámce.
df = _
Vykreslujte výsledky.
import matplotlib.pyplot as plt
df["Total Units % Change YoY"] = (df["[Total Units Ratio]"] - 1)
df.set_index(["Time[FiscalYear]", "Time[FiscalMonth]"]).plot.bar(y="Total Units % Change YoY")
plt.axhline(0)
plt.axhline(-0.2, color="red", linestyle="dotted")
plt.axhline( 0.5, color="red", linestyle="dotted")
None
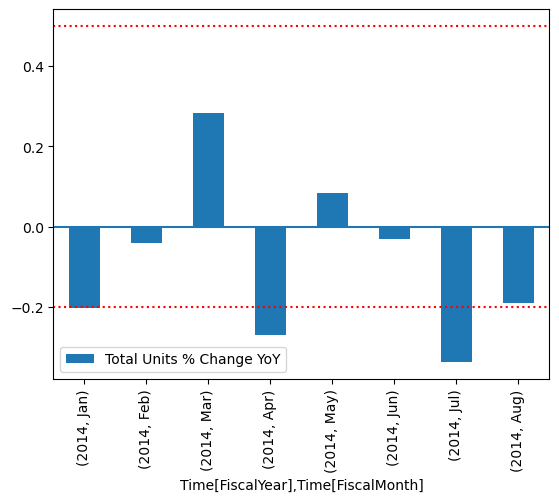
Z grafu vidíte, že duben a červenec byly mírně mimo rozsah a pak můžete provést další kroky k prozkoumání.
Ukládání konfigurace GX
S tím, jak se data v datové sadě mění v průběhu času, můžete chtít znovu spustit ověřování GX, která jste právě provedli. Kontext dat (obsahující připojené datové prostředky, očekávané sady a kontrolní bod) je v současné době dočasný, ale pro budoucí použití se dá převést na kontext souboru. Případně můžete vytvořit instanci kontextu souboru (viz vytvoření instance kontextu dat).
context = context.convert_to_file_context()
Teď, když jste uložili kontext, zkopírujte složku gx do svého lakehouse.
Důležitý
V této buňce se předpokládá, že do poznámkového bloku přidáte lakehouse. Pokud není k němu připojeno žádné jezero, nezobrazí se žádná chyba, ale později nebudete moct získat kontext. Pokud teď přidáte lakehouse, jádro se restartuje, takže budete muset znovu spustit celý poznámkový blok, abyste se k tomuto bodu vrátili.
# copy GX directory to attached lakehouse
!cp -r gx/ /lakehouse/default/Files/gx
Teď je možné pomocí context = gx.get_context(project_root_dir="<your path here>") vytvořit budoucí kontexty, které budou používat všechny konfigurace z tohoto kurzu.
Například v novém poznámkovém bloku připojte stejné jezero a použijte context = gx.get_context(project_root_dir="/lakehouse/default/Files/gx") k načtení kontextu.
Související obsah
Podívejte se na další kurzy pro sémantický odkaz / SemPy:
- kurz : Vyčištění dat pomocí funkčních závislostí
- kurz : Analýza funkčních závislostí v ukázkovém sémantickém modelu
- Kurz : Extrahování a výpočet měr Power BI z poznámkového bloku Jupyter
- kurz : Zjišťování relací v sémantickém modelu pomocí sémantického odkazu
- kurz : Zjišťování relací v datové sadě Synthea pomocí sémantických odkazů