Kurz: Analýza funkčních závislostí v sémantickém modelu
V tomto kurzu vycházíte z předchozí práce provedené analytikem Power BI a uložíte je ve formě sémantických modelů (datových sad Power BI). Pomocí SemPy (Preview) v prostředí Pro datové vědy Synapse v Rámci Microsoft Fabric analyzujete funkční závislosti, které existují ve sloupcích datového rámce. Tato analýza pomáhá zjišťovat netriviální problémy s kvalitou dat, aby bylo možné získat přesnější přehledy.
V tomto kurzu se naučíte:
- Využijte znalosti domény k formulaci hypotéz o funkčních závislostech v sémantickém modelu.
- Seznamte se s komponentami sémantické knihovny Pythonu (SemPy), které podporují integraci s Power BI a pomáhají automatizovat analýzu kvality dat. Mezi tyto komponenty patří:
- FabricDataFrame – struktura podobná pandas obohacená o další sémantické informace.
- Užitečné funkce pro načítání sémantických modelů z pracovního prostoru Fabric do poznámkového bloku.
- Užitečné funkce, které automatizují vyhodnocení hypotéz o funkčních závislostech a identifikují porušení vztahů v sémantických modelech.
Požadavky
Získejte předplatné Microsoft Fabric . Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače prostředí v levém dolním rohu domovské stránky přepněte na Fabric.

V levém navigačním podokně vyberte Pracovní prostory a vyhledejte a vyberte pracovní prostor. Tento pracovní prostor se stane vaším aktuálním pracovním prostorem.
Stáhněte si Customer Profitability Sample.pbix sémantický model z úložiště fabric-samples na GitHubu.
V pracovním prostoru vyberte Importovat sestavu>nebo stránkovanou sestavu>Z tohoto počítače nahrát soubor Customer Profitability Sample.pbix do pracovního prostoru.
Sledujte v poznámkovém bloku
Tento kurz doprovází powerbi_dependencies_tutorial.ipynb poznámkový blok.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v části Příprava systému na kurzy datových věd a importujte poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Nastavení poznámkového bloku
V této části nastavíte prostředí poznámkového bloku s potřebnými moduly a daty.
Nainstalujte
SemPyz PyPI pomocí funkce%pipin-line instalace v poznámkovém bloku:%pip install semantic-linkProveďte nezbytné importy modulů, které budete potřebovat později:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Načtení a předběžné zpracování dat
Tento kurz používá standardní ukázkový sémantický model Customer Profitability Sample.pbix. Popis sémantického modelu najdete v ukázce ziskovosti zákazníků pro power BI.
Načtěte data Power BI do FabricDataFrames pomocí funkce
read_tableze SemPy.dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Načtěte tabulku
Statedo prvku FabricDataFrame:state = fabric.read_table(dataset, "State") state.head()Zatímco výstup tohoto kódu vypadá jako datový rámec pandas, ve skutečnosti jste inicializovali datovou strukturu označovanou jako
FabricDataFrame, která podporuje některé užitečné operace nad knihovnou pandas.Zkontrolujte datový typ
customer:type(customer)Výstup potvrzuje, že
customerje typusempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.Připojte datové rámce
customerastate:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identifikace funkčních závislostí
Funkční závislost se projevuje jako relace 1:N mezi hodnotami ve dvou (nebo více) sloupcích v rámci datového rámce. Tyto relace je možné použít k automatickému zjišťování problémů s kvalitou dat.
Spuštěním
find_dependenciesfunkce SemPy ve sloučeném datovém rámci identifikujte všechny existující funkční závislosti mezi hodnotami ve sloupcích:dependencies = customer_state_df.find_dependencies() dependenciesVizualizujte identifikované závislosti pomocí funkce
plot_dependency_metadataSemPy:plot_dependency_metadata(dependencies)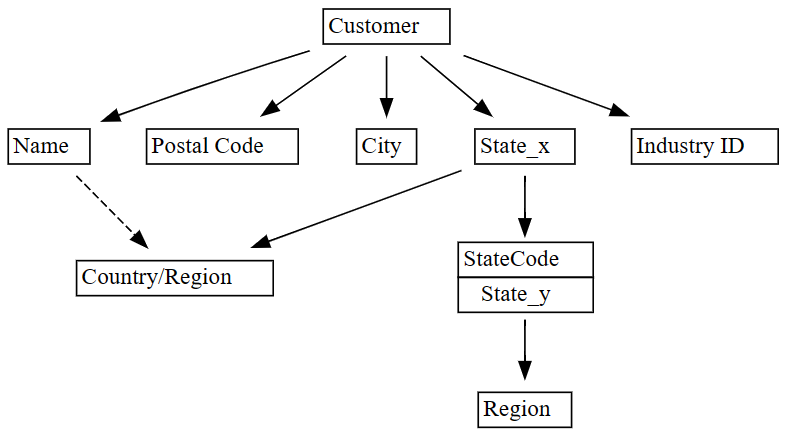
Podle očekávání graf funkčních závislostí ukazuje, že sloupec
Customerurčuje některé sloupce, jako jsouCity,Postal CodeaName.Graf překvapivě nezobrazuje funkční závislost mezi
CityaPostal Code, pravděpodobně proto, že mezi sloupci existuje mnoho porušení. Pomocí funkceplot_dependency_violationsSemPy můžete vizualizovat porušení závislostí mezi konkrétními sloupci.

Prozkoumejte data kvůli problémům s kvalitou
Nakreslete graf pomocí
plot_dependency_violationsvizualizační funkce SemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Graf porušení závislostí zobrazuje hodnoty pro
Postal Codena levé straně a hodnoty proCityna pravé straně. Hrana spojujePostal Codena levé straně sCityna pravé straně, pokud je řádek obsahující tyto dvě hodnoty. Hrany jsou opatřeny poznámkami s počtem takových řádků. Například existují dva řádky s PSČ 20004, jeden s městem "North Tower" a druhý s městem "Washington".Kromě toho graf zobrazuje několik porušení a mnoho prázdných hodnot.
Potvrďte počet prázdných hodnot pro
Postal Code:customer_state_df['Postal Code'].isna().sum()50 řádků má nevyplněné poštovní směrovací číslo.
Odstraňte řádky s prázdnými hodnotami. Potom pomocí funkce
find_dependenciesvyhledejte závislosti. Všimněte si dodatečného parametruverbose=1, který nabízí přehled o vnitřních činnostech SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Podmíněná entropie pro
Postal CodeaCityje 0,049. Tato hodnota označuje, že došlo k narušení funkčních závislostí. Než tato porušení opravíte, zvyšte prahovou hodnotu podmíněné entropie z výchozí hodnoty0.01na0.05, jen abyste viděli závislosti. Nižší prahové hodnoty vedou k menšímu počtu závislostí (nebo vyšší selektivitě).Zvýšení prahové hodnoty podmíněné entropie z výchozí hodnoty
0.01na0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))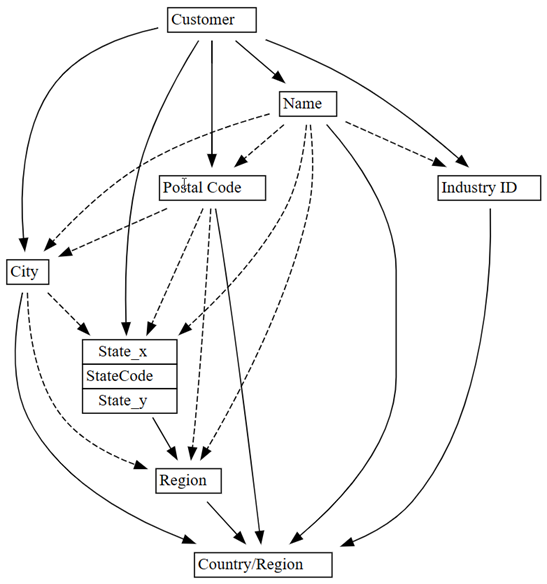
Pokud použijete znalosti domény o tom, která entita určuje hodnoty jiných entit, zdá se, že graf závislostí je přesný.
Prozkoumejte další zjištěné problémy s kvalitou dat. Například přerušovaná šipka spojuje
CityaRegion, což značí, že závislost je pouze přibližná. Tento přibližný vztah by mohl znamenat, že existuje částečná funkční závislost.customer_state_df.list_dependency_violations('City', 'Region')Podívejte se podrobněji na každý z případů, kdy neprázdná
Regionhodnota způsobuje narušení.customer_state_df[customer_state_df.City=='Downers Grove']Výsledek ukazuje město Downers Grove, které se vyskytuje v Illinois a Nebraska. Downer's Grove je však město v Illinois, nikoli Nebraska.
Podívejte se na město Fremont:
customer_state_df[customer_state_df.City=='Fremont']V Kaliforniije město označované jako
Fremont. Pro Texas však vyhledávač vrátí Premont, ne Fremont. Je také podezřelé vidět porušení závislosti mezi
NameaCountry/Region, jak je označeno tečkovanou čárou v původním grafu porušení závislostí (před vyřazením řádků s prázdnými hodnotami).customer_state_df.list_dependency_violations('Name', 'Country/Region')Zdá se, že jeden zákazník, SDI Design je přítomen ve dvou oblastech – Usa a Kanada. Tento výskyt nemusí být sémantické porušení, ale může to být jen neobvyklý případ. Přesto stojí za to se podívat zblízka:
Podívejte se blíže na zákazníka SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Další kontrola ukazuje, že se jedná o dva různé zákazníky (z různých odvětví) se stejným názvem.

Průzkumná analýza dat je vzrušující proces a také čištění dat. Vždy záleží na tom, jak se na data díváte, co chcete zjistit a podobně – vždy něco skrývají. Sémantický odkaz poskytuje nové nástroje, které můžete použít k dosažení větších výsledků s vašimi daty.
Související obsah
Podívejte se na další kurzy pro sémantický odkaz / SemPy:
- kurz : Vyčištění dat pomocí funkčních závislostí
- Kurz : Extrahování a výpočet měr Power BI z poznámkového bloku Jupyter
- kurz : Zjišťování relací v sémantickém modelu pomocí sémantického odkazu
- kurz : Zjišťování relací v datové sadě Synthea pomocí sémantických odkazů
- Výukový program: Ověřování dat pomocí SemPy a Great Expectations (GX)