Kurz: Zjišťování relací v datové sadě Synthea pomocí sémantického odkazu
Tento kurz ukazuje, jak pomocí sémantického odkazu rozpoznat relace ve veřejné datové sadě Synthea.
Když pracujete s novými daty nebo pracujete bez existujícího datového modelu, může být užitečné automaticky zjišťovat relace. Toto zjišťování relací vám může pomoct:
- porozumět modelu na vysoké úrovni,
- získání dalších přehledů při průzkumné analýze dat,
- ověření aktualizovaných dat nebo nových, příchozích dat a
- čištění dat
I když jsou relace známé předem, může vyhledávání relací pomoct lépe porozumět datovému modelu nebo identifikaci problémů s kvalitou dat.
V tomto kurzu začnete jednoduchým příkladem směrného plánu, ve kterém experimentujete pouze se třemi tabulkami, aby bylo snadné sledovat propojení mezi nimi. Pak zobrazíte složitější příklad s větší sadou tabulek.
V tomto kurzu se naučíte:
- Používejte komponenty sémantické knihovny Pythonu (SemPy), které podporují integraci s Power BI a pomáhají automatizovat analýzu dat. Mezi tyto komponenty patří:
- FabricDataFrame – struktura podobná knihovně pandas vylepšená o dodatečné sémantické informace.
- Funkce pro načítání sémantických modelů z pracovního prostoru Fabric do poznámkového bloku
- Funkce, které automatizují zjišťování a vizualizaci relací v sémantických modelech
- Řešení potíží s procesem zjišťování relací pro sémantické modely s více tabulkami a vzájemnými závislostmi
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabric.
Přihlaste se k Microsoft Fabric.
Použijte přepínač prostředí v levém dolním rohu domovské stránky k přepnutí na Fabric.

- V levém navigačním podokně vyberte Pracovní prostory a vyhledejte a vyberte pracovní prostor. Tento pracovní prostor se stane vaším aktuálním pracovním prostorem.
Sledujte v poznámkovém bloku
Tento kurz doprovází poznámkový blok relationships_detection_tutorial.ipynb.
Pokud chcete otevřít doprovodný poznámkový blok pro tento kurz, postupujte podle pokynů v tématu příprava systému na kurzy datových věd, abyste mohli importovat poznámkový blok do svého pracovního prostoru.
Pokud chcete raději zkopírovat a vložit kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Nastavení poznámkového bloku
V této části nastavíte prostředí poznámkového bloku s potřebnými moduly a daty.
Nainstalujte
SemPyz PyPI pomocí funkce in-line instalace%pipv notebooku:%pip install semantic-linkProveďte nezbytné importy modulů SemPy, které budete potřebovat později:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Import knihovny pandas pro vynucování možnosti konfigurace, která pomáhá s formátováním výstupu:
import pandas as pd pd.set_option('display.max_colwidth', None)Stáhněte si ukázková data. Pro účely tohoto kurzu použijete datovou sadu Synthea syntetických lékařských záznamů (pro jednoduchost malá verze):
download_synthea(which='small')
Detekovat relace v malé podmnožině tabulek Synthea
Vyberte tři tabulky z větší sady:
-
patientsurčuje informace o pacientech. -
encountersurčuje pacienty, kteří měli zdravotní setkání (například lékařské vyšetření, postup). -
providersurčuje, kteří poskytovatelé zdravotní péče věnovali pacientům péči
Tabulka
encountersřeší relaci M:N mezipatientsaprovidersa lze ji popsat jako asociativní entitu:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
Pomocí
find_relationshipsfunkce SemPy můžete najít relace mezi tabulkami:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsVizualizujte datový rámec relací jako graf pomocí
plot_relationship_metadatafunkce SemPy.plot_relationship_metadata(suggested_relationships)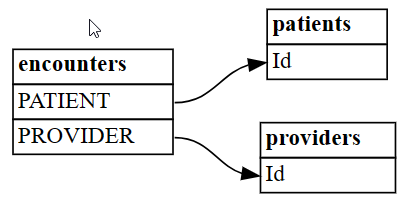
Funkce stanoví hierarchii relací z levé strany na pravou stranu, která odpovídá tabulkám "from" a "to" ve výstupu. Jinými slovy, tabulky "od", které jsou nezávislé a umístěné na levé straně, používají své cizí klíče k nasměrování na jejich závislé tabulky "na" nacházející se na pravé straně. Každý rámeček entity zobrazuje sloupce, které se podílí na straně "from" nebo "to" vztahu.
Ve výchozím nastavení se relace generují jako "m:1" (ne jako "1:m") nebo "1:1". Relace 1:1 lze vygenerovat jedním nebo oběma způsoby v závislosti na tom, jestli poměr mapovaných hodnot ke všem hodnotám překračuje
coverage_thresholdpouze jedním nebo oběma směry. Později v tomto kurzu se budeme zabývat méně častými případy relací m:m.

Řešení potíží s detekcí relací
Příklad směrného plánu ukazuje úspěšnou detekci relací při čistém Synthea dat. V praxi jsou data zřídka čistá, což brání úspěšné detekci. Existuje několik technik, které můžou být užitečné, když data nejsou čistá.
Tato část tohoto kurzu se zabývá detekcí vztahů, když sémantický model obsahuje špinavá data.
Začněte tím, že manipulací s původními datovými rámci získáte "špinavá" data a vytisknete velikost zašpiněných dat.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Pro porovnání tisk velikostí původních tabulek:
print(len(patients)) print(len(providers))Pomocí
find_relationshipsfunkce SemPy můžete najít relace mezi tabulkami:find_relationships([patients_dirty, providers_dirty, encounters])Výstup kódu ukazuje, že se nezjistily žádné relace kvůli chybám, které jste zavedli dříve, abyste vytvořili sémantický model "dirty".
Použijte ověřování
Ověření je nejlepší nástroj pro řešení potíží se selháními detekce vztahů, protože:
- Hlásí jasně, proč konkrétní vztah nedodržuje pravidla cizího klíče, a proto nemůže být zjištěn.
- Běží rychle u velkých sémantických modelů, protože se zaměřuje pouze na deklarované relace a neprovádí vyhledávání.
Ověření může použít libovolný datový rámec se sloupci podobnými datovému rámci vygenerovanému find_relationships. V následujícím kódu datový rámec suggested_relationships odkazuje na patients místo patients_dirty, ale datové rámce můžete aliasovat pomocí slovníku:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Zmírnit kritéria hledání
Ve složitějších scénářích můžete zkusit uvolnit kritéria hledání. Tato metoda zvyšuje možnost falešně pozitivních výsledků.
Nastavte
include_many_to_many=Truea vyhodnoťte, jestli vám to pomůže:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Výsledky ukazují, že byla zjištěna relace z
encountersdopatients, ale existují dva problémy:- Relace označuje směr od
patientskencounters, což je inverzní k očekávané relaci. Důvodem je to, že všechnypatientsbyly pokrytyencounters(Coverage Fromje 1,0), zatímcoencountersjsou pouze částečně pokrytypatients(Coverage To= 0,85), protože v řádcích pacientů chybí údaje. - U sloupce s nízkou kardinalitou
GENDERexistuje náhodná shoda, která odpovídá názvu a hodnotě v obou tabulkách, ale nejedná se o relaci "m:1" zájmu. Nízká kardinalita je označena sloupciUnique Count FromaUnique Count To.
- Relace označuje směr od
Spusťte znovu
find_relationshipsa hledejte pouze relace m:1, ale s nižší hodnotoucoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Výsledek ukazuje správný směr relací z
encountersnaproviders. Relace zencountersnapatientsse ale nezjistí, protožepatientsnení jedinečná, takže nemůže být na straně 1 relace m:1.Uvolněte
include_many_to_many=Trueicoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Teď jsou obě relace zájmu viditelné, ale existuje mnohem více šumu:
- Na
GENDERexistuje shoda s nízkou kardinalitou. - Objevila se vyšší kardinalita "m:m" na
ORGANIZATION, což jasně naznačuje, žeORGANIZATIONje pravděpodobně sloupec denormalizovaný do obou tabulek.
- Na
Odpovídat názvům sloupců
SemPy ve výchozím nastavení považuje za odpovídající pouze atributy, které zobrazují podobnost s názvem, a využívá tak skutečnost, že návrháři databáze obvykle označují související sloupce stejným způsobem. Toto chování pomáhá vyhnout se nechutným relacím, ke kterým dochází nejčastěji u celočíselného klíče s nízkou kardinalitou. Pokud jsou například 1,2,3,...,10 kategorie produktů a stavový kód objednávky 1,2,3,...,10, budou se vzájemně zaměňovat, když se podíváte pouze na mapování hodnot bez zohlednění názvů sloupců. Falešné relace by neměly představovat problém s klíči podobnými GUID.
SemPy se podívá na podobnost mezi názvy sloupců a názvy tabulek. Porovnávání je přibližné a nerozlišuje malá a velká písmena. Ignoruje nejčastěji zjištěných podřetězi "dekorátor", jako je "id", "code", "name", "key", "pk", "fk". V důsledku toho jsou nejběžnější případy shody:
- atribut s názvem 'column' v entitě 'foo' odpovídá atributu s názvem 'column' (také 'COLUMN' nebo 'Column') v entitě 'bar'.
- atribut s názvem 'column' v entitě 'foo' odpovídá atributu s názvem 'column_id' v entitě 'bar'.
- atribut nazvaný "bar" v entitě "foo" odpovídá atributu nazvanému "code" v "bar".
Při párování názvů sloupců se detekce spustí rychleji.
Porovná názvy sloupců:
- Pokud chcete zjistit, které sloupce jsou vybrány k dalšímu vyhodnocení, použijte možnost
verbose=2(verbose=1uvádí pouze zpracovávané entity). - Parametr
name_similarity_thresholdurčuje, jak se sloupce porovnávají. Prahová hodnota 1 značí, že se zajímáte pouze o 100% shody.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);Při použití hodnoty 100% podobnosti nezohledňuje malé rozdíly mezi názvy. V příkladu mají tabulky tvar množného čísla s příponou "s", což vede k žádné přesné shodě. To je zpracováno dobře s výchozími
name_similarity_threshold=0.8.- Pokud chcete zjistit, které sloupce jsou vybrány k dalšímu vyhodnocení, použijte možnost
Spusťte znovu s výchozím nastavením
name_similarity_threshold=0.8:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Všimněte si, že ID pro množný tvar
patientsje nyní porovnána s jednotným tvarempatient, aniž by se přidalo příliš mnoho dalších zbytečných porovnání k době provádění.Spusťte znovu výchozí
name_similarity_threshold=0:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Změna
name_similarity_thresholdna 0 je druhá extrémní hodnota a znamená to, že chcete porovnat všechny sloupce. To je zřídka nutné a vede ke zvýšení doby provádění a nechtěných shod, které je potřeba zkontrolovat. Podívejte se na počet porovnání v podrobném výstupu.
Shrnutí tipů pro řešení potíží
- Začněte od přesné shody pro relace "m:1" (to znamená výchozí
include_many_to_many=Falseacoverage_threshold=1.0). To je obvykle to, co chcete. - Použijte úzký fokus na menší podmnožinu tabulek.
- K detekci problémů s kvalitou dat použijte ověřování.
- Pokud chcete pochopit, které sloupce jsou zvažovány pro vztah, použijte
verbose=2. Výsledkem může být velký objem výstupu. - Mějte na paměti kompromisy u parametrů vyhledávání.
include_many_to_many=Trueacoverage_threshold<1.0můžou vést k nechutným relacím, které mohou být obtížně analyzovat a budou muset být filtrované.
Zjištění vztahů na úplné datové sadě Synthea
Jednoduchý základní příklad sloužil jako užitečný nástroj pro výuku a řešení potíží. V praxi můžete začít od sémantického modelu, jako je úplná datová sada Synthea, která obsahuje mnohem více tabulek. Prozkoumejte úplnou datovou sadu synthea následujícím způsobem.
Přečtěte všechny soubory z adresáře synthea/csv.
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Pomocí
find_relationshipsfunkce SemPy najděte relace mezi tabulkami:suggested_relationships = find_relationships(all_tables) suggested_relationshipsVizualizace relací:
plot_relationship_metadata(suggested_relationships)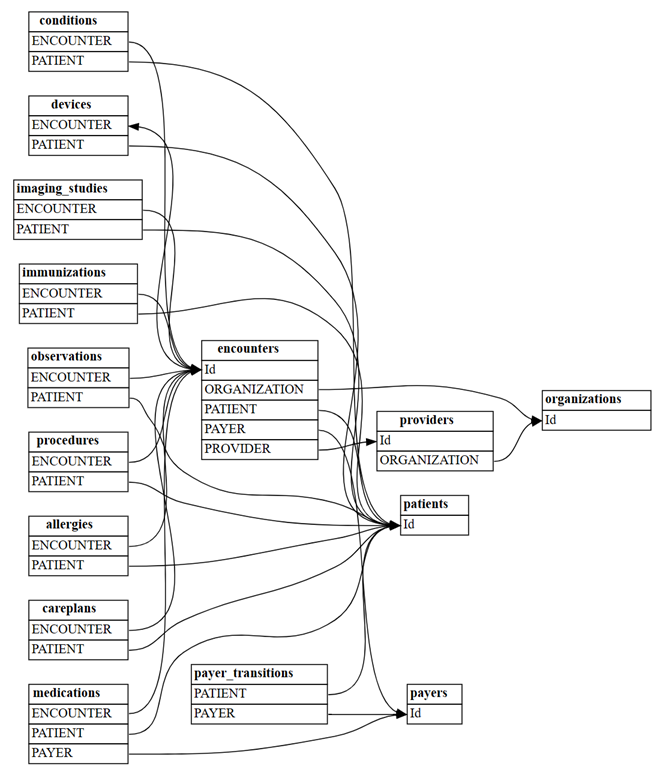
Spočítejte, kolik nových relací m:m se zjistí pomocí
include_many_to_many=True. Tyto relace jsou navíc k dříve zobrazeným relacím m:1; proto musíte filtrovat podlemultiplicity:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Data relací můžete řadit podle různých sloupců, abyste získali hlubší přehled o jejich povaze. Můžete se například rozhodnout uspořádat výstup podle
Row Count FromaRow Count To, které pomáhají identifikovat největší tabulky.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)V jiném sémantickém modelu by možná bylo důležité zaměřit se na počet hodnot null
Null Count FromneboCoverage To.Tato analýza vám pomůže pochopit, jestli některá z relací není platná, a pokud je potřebujete odebrat ze seznamu kandidátů.

Související obsah
Podívejte se na další kurzy pro sémantický odkaz / SemPy: