Indexování dat ze souborů a zkratek OneLake
V tomto článku se dozvíte, jak nakonfigurovat indexer souborů OneLake pro extrakci prohledávatelných dat a metadat z jezera nad OneLake.
Ke konfiguraci a spuštění indexeru můžete použít:
- 2024-05-01-preview rozhraní REST API nebo novější rozhraní REST API verze Preview.
- Beta balíček sady Azure SDK, který tuto funkci poskytuje.
- Průvodce importem dat na webu Azure Portal
- Průvodce importem a vektorizací dat na webu Azure Portal
Tento článek používá rozhraní REST API k ilustraci jednotlivých kroků.
Požadavky
Pracovní prostor Infrastruktury. Podle tohoto kurzu vytvořte pracovní prostor Fabric.
Jezero v pracovním prostoru Fabric. Postupujte podle tohoto kurzu a vytvořte jezero.
Textová data. Pokud máte binární data, můžete k extrakci textu nebo generování popisů obrázků použít analýzu rozšíření AI. Obsah souboru nemůže překročit limity indexeru pro vaši úroveň vyhledávací služby.
Obsah v umístění Soubory vašeho jezera. Data můžete přidat pomocí:
- Přímé nahrání do jezera
- Použití datových kanálů z Microsoft Fabric
- Přidejte zástupce z externích zdrojů dat, jako je Amazon S3 nebo Google Cloud Storage.
Search AI nakonfigurované pro spravovanou identitu systému nebo spravovanou identitu přiřazenou uživatelem. Search AI se musí nacházet ve stejném tenantovi jako pracovní prostor Microsoft Fabric.
Přiřazení role Přispěvatel v pracovním prostoru Microsoft Fabric, kde se nachází lakehouse. Kroky jsou popsané v části Udělení oprávnění v tomto článku.
Klient REST, který formuluje volání REST podobně jako volání uvedená v tomto článku.
Podporované úkoly
Tento indexer můžete použít pro následující úlohy:
- Indexování dat a přírůstkové indexování: Indexer může indexovat soubory a přidružená metadata z datových cest v rámci jezera. Zjišťuje nové a aktualizované soubory a metadata prostřednictvím integrované detekce změn. Aktualizaci dat můžete nakonfigurovat podle plánu nebo na vyžádání.
- Detekce odstranění: Indexer dokáže detekovat odstranění prostřednictvím vlastních metadat pro většinu souborů a zástupců. To vyžaduje přidání metadat do souborů, které značí, že byly "obnovitelné odstranění", což umožňuje jejich odebrání z indexu vyhledávání. V současné době není možné detekovat odstranění v souborech zástupců Google Cloud Storage nebo Amazon S3, protože pro tyto zdroje dat nejsou podporovaná vlastní metadata.
- Použitá AI prostřednictvím sad dovedností: Indexer souborů OneLake plně podporuje sady dovedností . To zahrnuje klíčové funkce, jako je integrovaná vektorizace , která přidává bloky dat a kroky vkládání.
- Režimy analýzy: Indexer podporuje režimy analýzy JSON, pokud chcete parsovat pole JSON nebo řádky do jednotlivých vyhledávacích dokumentů. Podporuje také režim analýzy Markdownu.
- Kompatibilita s jinými funkcemi: Indexer OneLake je navržený tak, aby bezproblémově fungoval s dalšími funkcemi indexeru, jako jsou ladicí relace, mezipaměť indexeru pro přírůstkové rozšiřování a úložiště znalostí.
Podporované formáty dokumentů
Indexer souborů OneLake může extrahovat text z následujících formátů dokumentu:
- CSV (viz indexování objektů blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (viz indexování objektů blob JSON)
- KML (XML pro geografické reprezentace)
- formáty systém Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPTM, MSG (e-maily Outlooku), XML (2003 i 2006 WORD XML)
- Formáty otevřených dokumentů: ODT, ODS, ODP
- Soubory ve formátu prostého textu (viz také indexování prostého textu)
- RTF
- XML
- ZIP
Podporované klávesové zkratky
Indexer souborů OneLake podporuje následující klávesové zkratky OneLake:
Zástupce OneLake (zástupce jiné instance OneLake)
Omezení v této verzi Preview
Typy souborů Parquet (včetně delta parquet) se v současné době nepodporují.
Odstranění souboru není podporováno pro zástupce Amazon S3 a Google Cloud Storage.
Tento indexer nepodporuje obsah umístění tabulky pracovního prostoru OneLake.
Tento indexer nepodporuje dotazy SQL, ale dotaz použitý v konfiguraci zdroje dat je výhradně k přidání volitelné složky nebo zástupce pro přístup.
Ve OneLake se nepodporuje ingestování souborů z pracovního prostoru Můj pracovní prostor , protože se jedná o osobní úložiště pro jednotlivé uživatele.
Příprava dat pro indexování
Než nastavíte indexování, zkontrolujte zdrojová data a zjistěte, jestli se mají předem provést nějaké změny. Indexer může indexovat obsah z jednoho kontejneru najednou. Ve výchozím nastavení se zpracovávají všechny soubory v kontejneru. Pro selektivní zpracování máte několik možností:
Umístěte soubory do virtuální složky. Definice zdroje dat indexeru obsahuje parametr dotazu, který může být buď podsložkou lakehouse, nebo zástupcem. Pokud je tato hodnota zadaná, indexují se pouze soubory v podsložce nebo zástupce v rámci jezera.
Zahrnout nebo vyloučit soubory podle typu souboru. Seznam podporovaných formátů dokumentů vám může pomoct určit, které soubory se mají vyloučit. Můžete například chtít vyloučit obrázky nebo zvukové soubory, které neposkytují prohledávatelný text. Tato funkce se řídí nastavením konfigurace v indexeru.
Zahrnout nebo vyloučit libovolné soubory. Pokud chcete určitý soubor z jakéhokoli důvodu přeskočit, můžete do souborů ve svém OneLake Lakehouse přidat vlastnosti metadat a hodnoty. Když indexer narazí na tuto vlastnost, přeskočí soubor nebo jeho obsah při spuštění indexování.
Zahrnutí a vyloučení souborů je popsáno v kroku konfigurace indexeru. Pokud kritéria nenastavíte, indexer hlásí opravňující soubor jako chybu a přesune se dál. Pokud dojde k dostatečným chybám, zpracování se může zastavit. V nastavení konfigurace indexeru můžete zadat odolnost proti chybám.
Indexer obvykle vytvoří jeden prohledávací dokument na soubor, kde se textový obsah a metadata zachytí jako prohledávatelná pole v indexu. Pokud jsou soubory celé, můžete je potenciálně analyzovat do více vyhledávacích dokumentů. Můžete například analyzovat řádky v souboru CSV a vytvořit jeden hledaný dokument na řádek. Pokud potřebujete vytvořit blok jednoho dokumentu do menších pasáží pro vektorizaci dat, zvažte použití integrované vektorizace.
Indexování metadat souboru
Metadata souborů je také možné indexovat a to je užitečné, pokud si myslíte, že některé ze standardních nebo vlastních vlastností metadat jsou užitečné ve filtrech a dotazech.
Vlastnosti metadat zadaných uživatelem se extrahují doslovně. Chcete-li získat hodnoty, musíte definovat pole v indexu vyhledávání typu Edm.String, se stejným názvem jako klíč metadat objektu blob. Pokud má například objekt blob klíč Priority metadat s hodnotou High, měli byste definovat pole pojmenované Priority v indexu vyhledávání a naplní se hodnotou High.
Standardní vlastnosti metadat souborů je možné extrahovat do podobně pojmenovaných a typových polí, jak je uvedeno níže. Indexer souborů OneLake automaticky vytvoří mapování interních polí pro tyto vlastnosti metadat a převede původní název dělení slov ("metadata-storage-name") na podtržítka ekvivalentního názvu ("metadata_storage_name").
Stále musíte do definice indexu přidat podtržítka, ale mapování polí indexeru můžete vynechat, protože indexer přidružení automaticky provede.
metadata_storage_name (
Edm.String) – název souboru. Pokud máte například soubor /mydatalake/my-folder/podsložka/resume.pdf, hodnota tohoto pole jeresume.pdf.metadata_storage_path (
Edm.String) – úplný identifikátor URI objektu blob, včetně účtu úložiště. Napříkladhttps://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) – typ obsahu zadaný kódem, který jste použili k nahrání objektu blob. Napříkladapplication/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset) – časové razítko poslední změny objektu blob. Azure AI Search používá toto časové razítko k identifikaci změněných objektů blob, aby se zabránilo přeindexování všeho po počátečním indexování.metadata_storage_size (
Edm.Int64) – velikost objektu blob v bajtech.metadata_storage_content_md5 (
Edm.String) – hodnota hash MD5 obsahu objektu blob, pokud je k dispozici.
Nakonec můžou být všechny vlastnosti metadat specifické pro formát dokumentu souborů, které indexujete, reprezentovány také ve schématu indexu. Další informace o metadatech specifických pro obsah naleznete v tématu Vlastnosti metadat obsahu.
Je důležité zdůraznit, že nemusíte definovat pole pro všechny výše uvedené vlastnosti v indexu vyhledávání – stačí zachytávat vlastnosti, které potřebujete pro vaši aplikaci.
Udělit oprávnění
Indexer OneLake používá pro připojení k OneLake ověřování tokenů a přístup založený na rolích. Oprávnění se přiřazují ve OneLake. Neexistují žádné požadavky na oprávnění pro fyzická úložiště dat, která zástupce zálohují. Pokud například indexujete z AWS, nemusíte v AWS udělovat oprávnění vyhledávací služby.
Minimální přiřazení role pro vaši identitu vyhledávací služby je Přispěvatel.
Nakonfigurujte systémovou nebo uživatelem spravovanou identitu pro Search umělé inteligence.
Následující snímek obrazovky ukazuje systémovou spravovanou identitu vyhledávací služby s názvem "onelake-demo".

Tento snímek obrazovky ukazuje identitu spravovanou uživatelem pro stejnou vyhledávací službu.

Udělte oprávnění pro přístup vyhledávací služby k pracovnímu prostoru Fabric. Vyhledávací služba vytvoří připojení jménem indexeru.
Pokud používáte spravovanou identitu přiřazenou systémem, vyhledejte název Search AI. U spravované identity přiřazené uživatelem vyhledejte název prostředku identity.
Následující snímek obrazovky ukazuje přiřazení role Přispěvatel pomocí spravované identity systému.
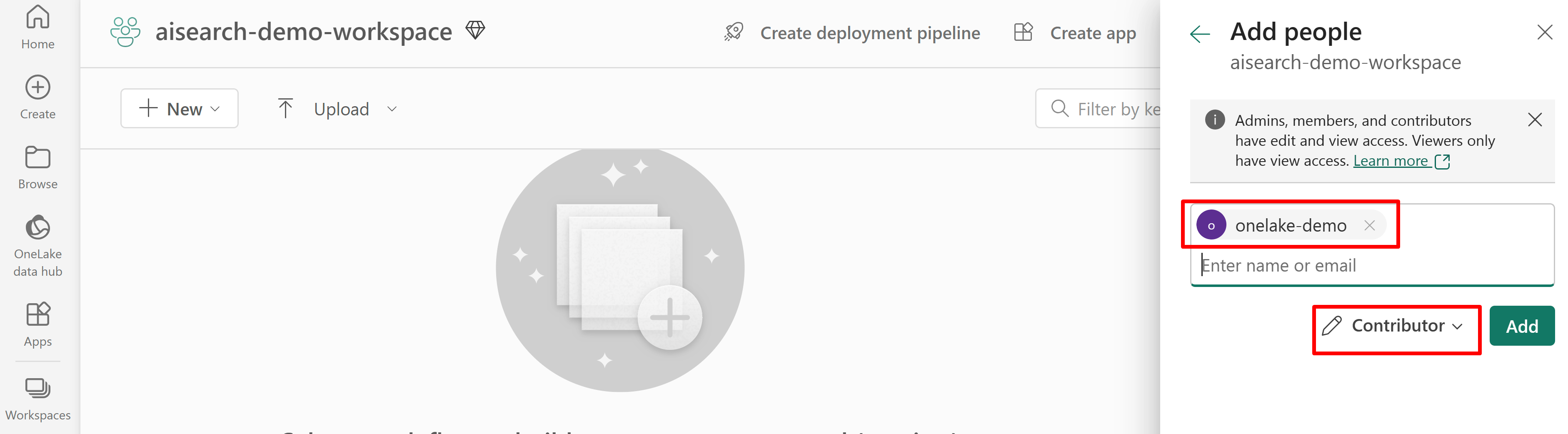
Tento snímek obrazovky ukazuje přiřazení role Přispěvatel pomocí spravované identity systému:





Definování zdroje dat
Zdroj dat je definován jako nezávislý prostředek, aby ho mohl používat více indexerů. K vytvoření zdroje dat musíte použít rozhraní REST API verze 2024-05-05-preview.
K nastavení definice použijte rozhraní REST API pro vytvoření nebo aktualizaci zdroje dat. Jedná se o nejvýznamnější kroky definice.
Nastaveno
"type"na"onelake"(povinné).Získejte identifikátor GUID pracovního prostoru Microsoft Fabric a identifikátor GUID lakehouse:
Přejděte do jezera, ze které chcete importovat data z adresy URL. Měl by vypadat podobně jako v tomto příkladu: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Zkopírujte následující hodnoty, které se používají v definici zdroje dat:
Zkopírujte identifikátor GUID pracovního prostoru, který zavoláme
{FabricWorkspaceGuid}, který se zobrazí hned za "skupinami" v adrese URL. V tomto příkladu by to bylo 00000000-0000-0000-0000-00000000000000.
Zkopírujte identifikátor GUID jezera, který budeme volat
{lakehouseGuid}, který je uveden přímo za "lakehouses" v adrese URL. V tomto příkladu by to bylo 1111111-1111-1111-1111-1111-111111111.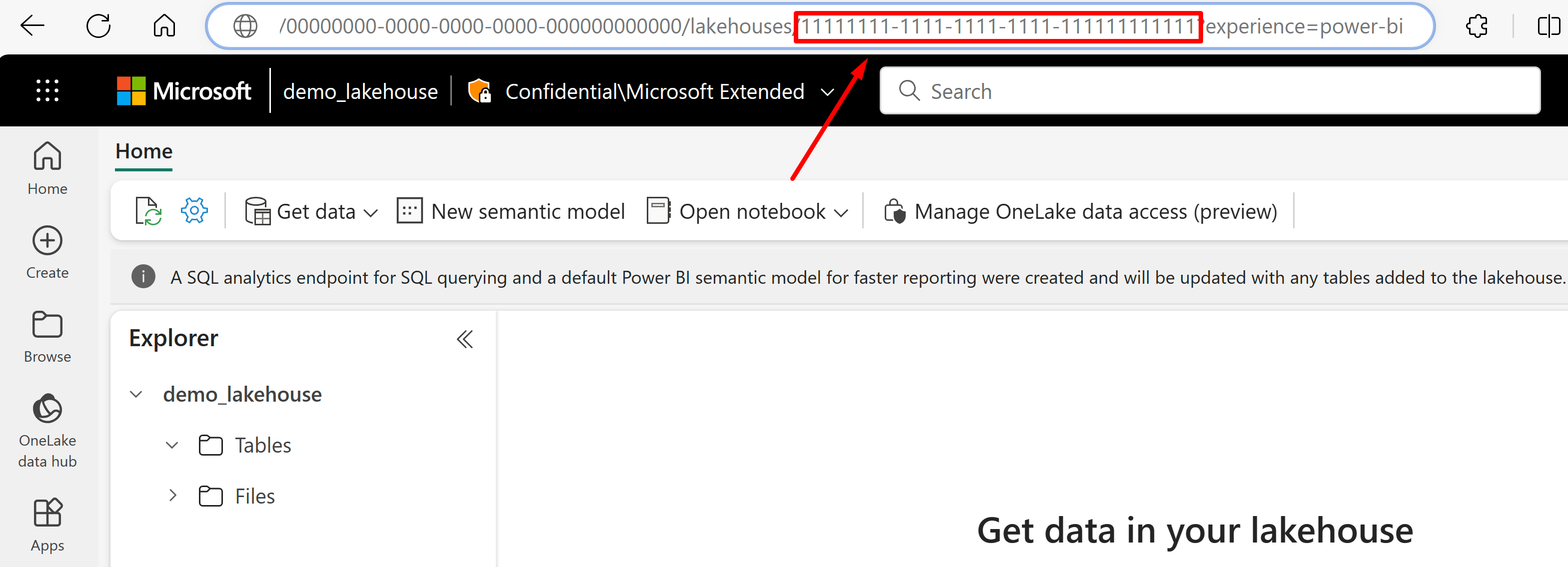
Nastavte
"credentials"identifikátor GUID pracovního prostoru Microsoft Fabric nahrazením{FabricWorkspaceGuid}hodnoty, kterou jste zkopírovali v předchozím kroku. Toto je OneLake pro přístup ke spravované identitě, kterou nastavíte později v této příručce."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Nastavte
"container.name"na identifikátor GUID lakehouse a nahraďte{lakehouseGuid}hodnotou, kterou jste zkopírovali v předchozím kroku. Slouží"query"k volitelnému určení podsložky nebo zástupce jezera."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Nastavte metodu ověřování pomocí spravované identity přiřazené uživatelem nebo přejděte k dalšímu kroku pro identitu spravovanou systémem.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Hodnotu
userAssignedIdentitylze najít přístupem k{userAssignedManagedIdentity}prostředku v části Vlastnosti a je volánaId.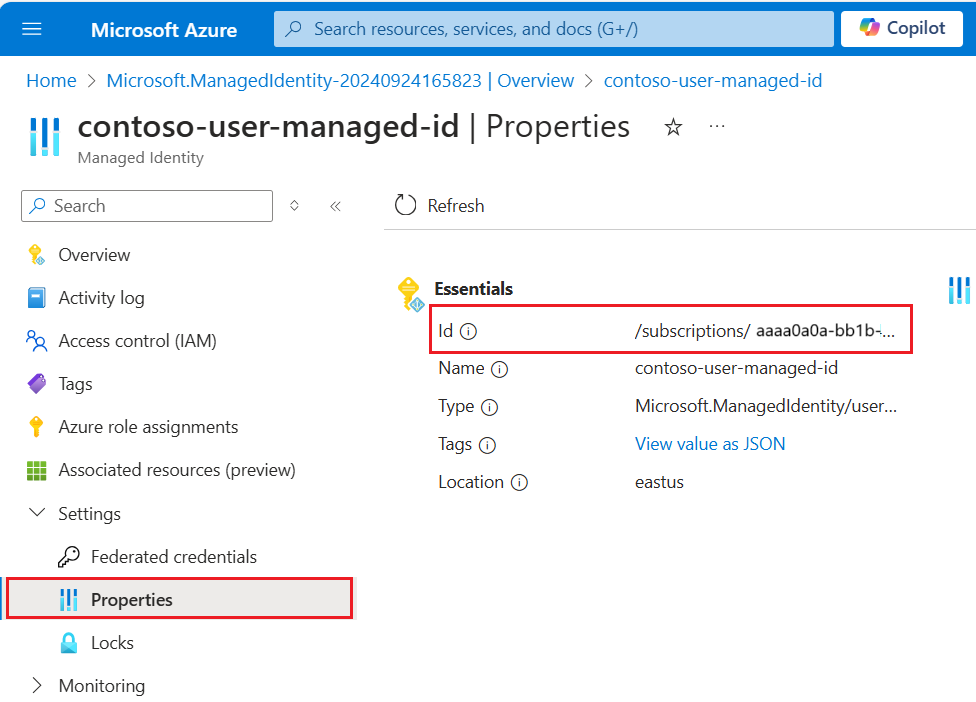
Příklad:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }Volitelně můžete místo toho použít spravovanou identitu přiřazenou systémem. Identita se z definice odebere, pokud používáte spravovanou identitu přiřazenou systémem.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Příklad:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Detekce odstranění prostřednictvím vlastních metadat
Definice zdroje dat indexeru OneLake může obsahovat zásadu obnovitelného odstranění, pokud chcete, aby indexer odstranil vyhledávací dokument, když je zdrojový dokument označen příznakem pro odstranění.
Pokud chcete povolit automatické odstraňování souborů, použijte vlastní metadata k označení, zda má být vyhledávací dokument odebrán z indexu.
Pracovní postup vyžaduje tři samostatné akce:
- "Obnovitelné odstranění" souboru ve OneLake
- Indexer odstraní hledaný dokument v indexu.
- "Pevné odstranění" souboru ve OneLake
"Obnovitelné odstranění" říká indexeru, co má udělat (odstranění vyhledávacího dokumentu). Pokud nejprve odstraníte fyzický soubor ve OneLake, indexer nemůže číst a odpovídající vyhledávací dokument v indexu je osamocený.
Ve Službě OneLake a Azure AI Search je potřeba postupovat podle kroků, ale neexistují žádné další závislosti funkcí.
V souboru lakehouse přidejte do souboru vlastní dvojici klíč-hodnota metadat, která indikuje, že se soubor označí příznakem pro odstranění. Můžete například pojmenovat vlastnost IsDeleted, která je nastavená na hodnotu false. Pokud chcete soubor odstranit, změňte ho na true.
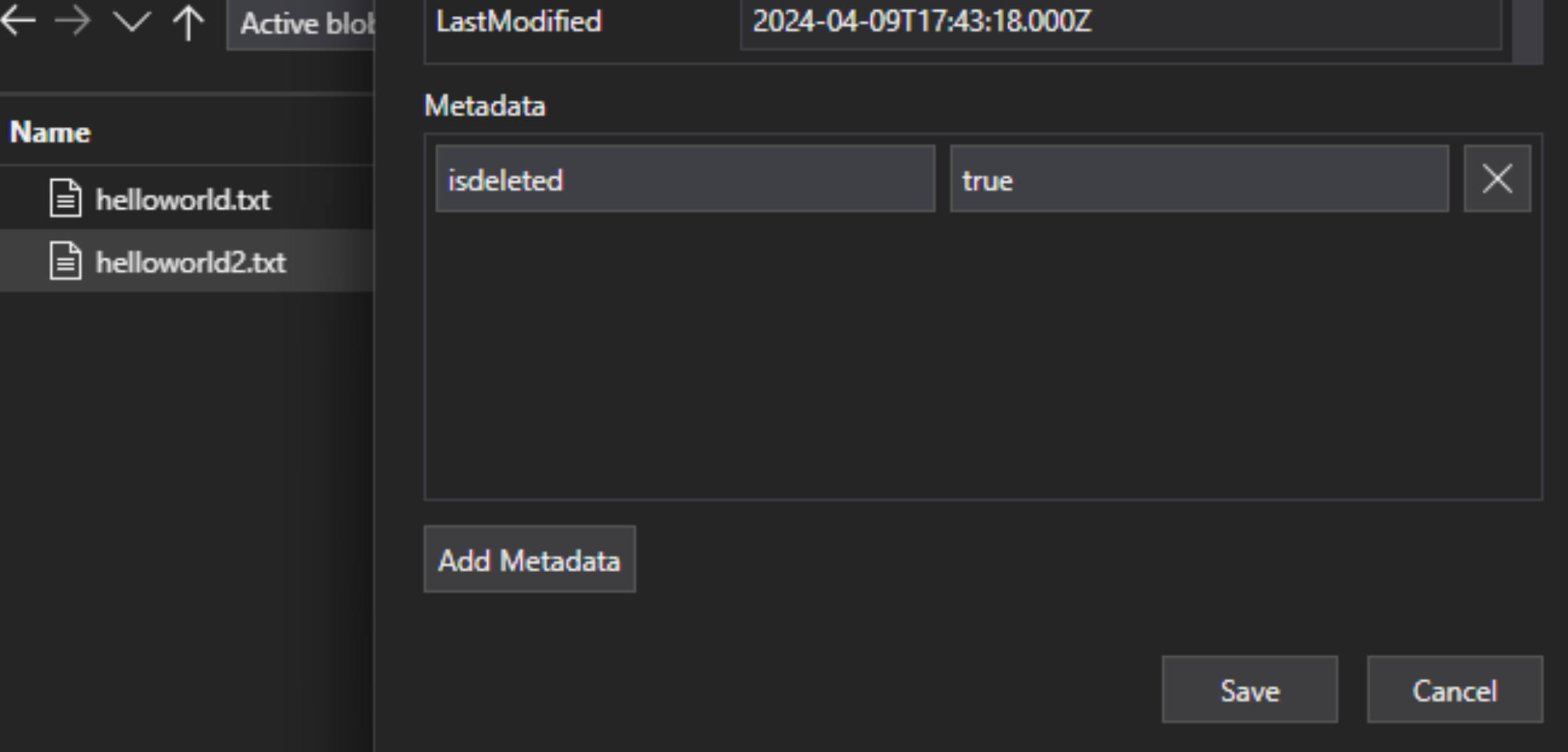
Ve službě Azure AI Search upravte definici zdroje dat tak, aby zahrnovala vlastnost dataDeletionDetectionPolicy. Například následující zásada považuje soubor, který se má odstranit, pokud má vlastnost metadat IsDeleted s hodnotou true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Po spuštění indexeru a odstranění dokumentu z indexu vyhledávání můžete odstranit fyzický soubor v datovém jezeře.
Mezi klíčové body patří:
Plánování spuštění indexeru pomáhá tento proces automatizovat. Doporučujeme naplánovat všechny scénáře přírůstkového indexování.
Pokud se zásada detekce odstranění nenastavila při prvním spuštění indexeru, musíte indexer resetovat, aby načetla aktualizovanou konfiguraci.
Vzpomeňte si, že detekce odstranění není podporovaná pro zástupce Amazon S3 a Google Cloud Storage kvůli závislosti na vlastních metadatech.
Přidání vyhledávacích polí do indexu
Do indexu vyhledávání přidejte pole pro příjem obsahu a metadat souborů OneLake Data Lake.
Vytvořte nebo aktualizujte index a definujte vyhledávací pole, která ukládají obsah souboru a metadata:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Vytvoření pole klíče dokumentu ("key": true) Nejlepšími kandidáty pro obsah souboru jsou vlastnosti metadat.
metadata_storage_path(výchozí) úplná cesta k objektu nebo souboru. Pole klíče (ID v tomto příkladu) se naplní hodnotami z metadata_storage_path, protože se jedná o výchozí hodnotu.metadata_storage_name, použitelné pouze v případě, že názvy jsou jedinečné. Pokud chcete toto pole použít jako klíč, přejděte"key": truena tuto definici pole.Vlastní vlastnost metadat, kterou přidáte do souborů. Tato možnost vyžaduje, aby proces nahrání souboru přidal tuto vlastnost metadat do všech objektů blob. Vzhledem k tomu, že klíč je povinná vlastnost, všechny soubory, u které chybí hodnota, se nedají indexovat. Pokud jako klíč použijete vlastní vlastnost metadat, vyhněte se změnám této vlastnosti. Indexery při změně vlastnosti klíče přidají duplicitní dokumenty pro stejný soubor.
Vlastnosti metadat často obsahují znaky, například
/a-, které jsou neplatné pro klíče dokumentu. Protože indexer má vlastnost base64EncodeKeys (true ve výchozím nastavení), automaticky kóduje vlastnost metadat bez nutnosti konfigurace nebo mapování polí.Přidejte pole "content" pro uložení extrahovaného textu z každého souboru prostřednictvím vlastnosti "content" souboru. Tento název nemusíte používat, ale můžete tak využít implicitní mapování polí.
Přidejte pole pro standardní vlastnosti metadat. Indexer může číst vlastní vlastnosti metadat, standardní vlastnosti metadat a vlastnosti metadat specifických pro obsah.
Konfigurace a spuštění indexeru souborů OneLake
Po vytvoření indexu a zdroje dat můžete indexer vytvořit. Konfigurace indexeru určuje vstupy, parametry a vlastnosti, které řídí chování doby běhu. Můžete také určit, které části objektu blob se mají indexovat.
Vytvořte nebo aktualizujte indexer tak, že ho pojmenujte a odkazujete na zdroj dat a cílový index:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Nastavte "batchSize", pokud je výchozí (10 dokumentů) buď pod využitím nebo zahlcením dostupných prostředků. Výchozí velikosti dávek jsou specifické pro zdroj dat. Indexování souborů nastavuje velikost dávky na 10 dokumentů při rozpoznávání větší průměrné velikosti dokumentu.
V části "konfigurace" určete, které soubory se indexují na základě typu souboru, nebo ponechte nezadané, aby se načetly všechny soubory.
Zadejte
"indexedFileNameExtensions"čárkami oddělený seznam přípon souborů (s úvodní tečkou)."excludedFileNameExtensions"Stejným způsobem označte, která rozšíření by se měla přeskočit. Pokud je stejné rozšíření v obou seznamech, je vyloučené z indexování.V části "konfigurace" nastavte "dataToExtract", abyste mohli určit, které části souborů se indexují:
Výchozí hodnota je contentAndMetadata. Určuje, že se indexují všechna metadata a textový obsah extrahovaný ze souboru.
Parametr storageMetadata určuje, že se indexují pouze standardní vlastnosti souboru a metadata zadaná uživatelem. I když jsou vlastnosti zdokumentované pro objekty blob Azure, vlastnosti souboru jsou stejné pro OneLkae s výjimkou metadat souvisejících se SAS.
AllMetadata určuje, že standardní vlastnosti souboru a všechna metadata nalezených typů obsahu se extrahují z obsahu souboru a indexují se.
V části "konfigurace" nastavte "parsingMode", pokud by se soubory měly mapovat na více vyhledávacích dokumentů nebo pokud se skládají z prostého textu, dokumentů JSON nebo souborů CSV.
Určete mapování polí, pokud existují rozdíly v názvu nebo typu pole nebo pokud potřebujete v indexu vyhledávání více verzí zdrojového pole.
Při indexování souborů můžete často vynechat mapování polí, protože indexer má integrovanou podporu mapování vlastností "obsahu" a metadat na podobně pojmenovaná a zapisovaná pole v indexu. U vlastností metadat indexer automaticky nahradí pomlčky
-podtržítky v indexu vyhledávání.
Další informace o dalších vlastnostech potřebujete vytvořit indexer. Úplný seznam popisů parametrů najdete v tématu Vytvoření indexeru (REST) v rozhraní REST API. Parametry jsou stejné pro OneLake.
Ve výchozím nastavení se indexer spustí automaticky při jeho vytvoření. Toto chování můžete změnit nastavením "zakázáno" na hodnotu true. Pokud chcete řídit provádění indexeru, spusťte indexer na vyžádání nebo ho umístěte do plánu.
Kontrola stavu indexeru
Tady se dozvíte více přístupů k monitorování stavu indexeru a historie spuštění.
Zpracování chyb
Mezi chyby, ke kterým běžně dochází při indexování, patří nepodporované typy obsahu, chybějící obsah nebo nadměrné soubory. Indexer souborů OneLake se ve výchozím nastavení zastaví, jakmile narazí na soubor s nepodporovaným typem obsahu. Můžete ale chtít, aby indexování pokračovalo i v případě, že dojde k chybám, a později ladit jednotlivé dokumenty.
Přechodné chyby jsou běžné pro řešení zahrnující více platforem a produktů. Pokud ale indexer udržujete podle plánu (například každých 5 minut), měl by být indexer schopen tyto chyby obnovit v následujícím spuštění.
Existuje pět vlastností indexeru, které řídí odpověď indexeru při výskytu chyb.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parametr | Platné hodnoty | Popis |
|---|---|---|
| MaxFailedItems | -1, null nebo 0, kladné celé číslo | Pokračujte v indexování, pokud k chybám dochází v jakémkoli okamžiku zpracování, a to buď při analýze objektů blob, nebo při přidávání dokumentů do indexu. Nastavte tyto vlastnosti na počet přijatelných selhání. Hodnota -1 umožňuje zpracování bez ohledu na počet výskytů chyb. V opačném případě je hodnota kladné celé číslo. |
| "maxFailedItemsPerBatch" | -1, null nebo 0, kladné celé číslo | Stejné jako výše, ale používá se k dávkovému indexování. |
| "failOnUnsupportedContentType" | true nebo false | Pokud indexer nemůže určit typ obsahu, určete, jestli se má úloha pokračovat nebo selhat. |
| "failOnUnprocessableDocument" | true nebo false | Pokud indexer nemůže zpracovat dokument jiného podporovaného typu obsahu, určete, zda chcete pokračovat nebo selhat úlohu. |
| "indexStorageMetadataOnlyForOversizedDocuments" | true nebo false | Nadlimitní objekty blob se ve výchozím nastavení považují za chyby. Pokud tento parametr nastavíte na hodnotu true, indexer se pokusí indexovat jeho metadata, i když obsah nelze indexovat. Omezení velikosti objektu blob najdete v tématu Omezení služby. |
Další kroky
Přečtěte si, jak průvodce importem a vektorizací dat funguje, a vyzkoušejte si ho pro tento indexer. Pomocí integrované vektorizace můžete vytvořit bloky a vytvářet vkládání pro vektorové nebo hybridní vyhledávání pomocí výchozího schématu.