Rychlý start: Vektorizace textu a obrázků pomocí webu Azure Portal
Tento rychlý start vám pomůže začít s integrovanou vektorizací pomocí Průvodce importem a vektorizací dat na webu Azure Portal. Průvodce zablokuje váš obsah a volá model vkládání, který vektorizuje obsah během indexování a pro dotazy.
Požadavky
Předplatné Azure. Vytvořte si ho zdarma.
Azure AI Search ve stejné oblasti jako Azure AI. Doporučujeme úroveň Basic nebo vyšší.
Podporovaný zdroj dat s ukázkovými dokumenty PDF plánu stavu
Podporovaný model vkládání.
Znalost průvodce Podrobnosti najdete v průvodcích importem dat na webu Azure Portal.
Podporované zdroje dat
Průvodce importem a vektorizací dat podporuje širokou škálu zdrojů dat Azure, ale tento rychlý start poskytuje kroky pouze pro ty zdroje dat, které pracují s celými soubory:
Azure Blob Storage pro objekty blob a tabulky Azure Storage musí být účet standardního výkonu (pro obecné účely verze 2). Úrovně přístupu můžou být horké, studené a studené.
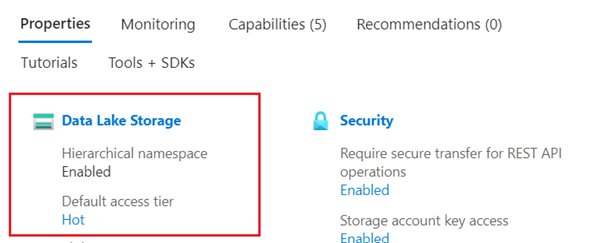
Azure Data Lake Storage (ADLS) Gen2 (účet Azure Storage s povoleným hierarchickým oborem názvů). To, že máte Data Lake Storage, můžete ověřit tak, že na stránce Přehled zkontrolujete kartu Vlastnosti.
Podporované modely vkládání
Použijte model vkládání na platformu Azure AI ve stejné oblasti jako Azure AI Search. Pokyny k nasazení najdete v tomto článku.
| Poskytovatel | Podporované modely |
|---|---|
| Azure OpenAI Service | text-embedding-ada-002 text-embedding-3-large text-embedding-3-small |
| Katalog modelů Azure AI Foundry | Text: Cohere-embed-v3-english Cohere-embed-v3-multilingual Obrázky: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
| Účet služeb Azure AI s více službami | Multimodální funkce Azure AI Vision pro vektorizaci obrázků a textu, které jsou k dispozici ve vybraných oblastech. V závislosti na tom, jak připojíte prostředek s více službami, může být účet s více službami ve stejné oblasti jako Azure AI Search. |
Pokud používáte službu Azure OpenAI, koncový bod musí mít přidruženou vlastní subdoménu. Vlastní subdoména je koncový bod, který obsahuje jedinečný název (například https://hereismyuniquename.cognitiveservices.azure.com). Pokud byla služba vytvořená prostřednictvím webu Azure Portal, tato subdoména se automaticky vygeneruje jako součást nastavení služby. Před použitím s integrací služby Azure AI Search se ujistěte, že vaše služba obsahuje vlastní subdoménu.
Prostředky služby Azure OpenAI (s přístupem k modelům vkládání) vytvořené na portálu Azure AI Foundry se nepodporují. S integrací dovedností Azure OpenAI Embedding jsou kompatibilní pouze prostředky služby Azure OpenAI vytvořené na webu Azure Portal.
Požadavky na veřejný koncový bod
Pro účely tohoto rychlého startu musí mít všechny předchozí prostředky povolený veřejný přístup, aby k nim uzly webu Azure Portal měly přístup. Jinak průvodce selže. Po spuštění průvodce můžete pro zabezpečení povolit brány firewall a privátní koncové body. Další informace naleznete v tématu Zabezpečené připojení v průvodcích importem.
Pokud už existují privátní koncové body a nemůžete je zakázat, je alternativní možností spuštění příslušného kompletního toku ze skriptu nebo programu na virtuálním počítači. Virtuální počítač musí být ve stejné virtuální síti jako privátní koncový bod. Tady je ukázka kódu Pythonu pro integrovanou vektorizaci. Stejné úložiště GitHub obsahuje ukázky v jiných programovacích jazycích.
Oprávnění
Můžete použít ověřování klíčů a úplný přístup připojovací řetězec nebo ID Microsoft Entra s přiřazeními rolí. Doporučujeme přiřazení rolí pro připojení vyhledávací služby k jiným prostředkům.
Ve službě Azure AI Search povolte role.
Nakonfigurujte vyhledávací službu tak, aby používala spravovanou identitu.
Na platformě zdroje dat a poskytovateli modelu pro vložení vytvořte přiřazení rolí, která vyhledávací službě umožňují přístup k datům a modelům. Příprava ukázkových dat obsahuje pokyny pro nastavení rolí pro každý podporovaný zdroj dat.
Bezplatná vyhledávací služba podporuje připojení založená na rolích ke službě Azure AI Search, ale nepodporuje spravované identity u odchozích připojení ke službě Azure Storage nebo Azure AI Vision. Tato úroveň podpory znamená, že pro připojení mezi bezplatnou vyhledávací službou a dalšími službami Azure musíte použít ověřování založené na klíči.
Bezpečnější připojení:
- Použijte úroveň Basic nebo vyšší.
- Nakonfigurujte spravovanou identitu a použijte role pro autorizovaný přístup.
Poznámka:
Pokud nemůžete procházet průvodcem, protože nejsou dostupné možnosti (například nemůžete vybrat zdroj dat nebo vložený model), znovu se k přiřazení rolí vrátit. Chybové zprávy označují, že modely nebo nasazení neexistují, pokud ve skutečnosti skutečná příčina znamená, že vyhledávací služba nemá oprávnění k přístupu k nim.
Kontrola místa
Pokud začínáte s bezplatnou službou, jste omezeni na tři indexy, zdroje dat, sady dovedností a indexery. Základní omezení na 15. Než začnete, ujistěte se, že máte místo pro další položky. Tento rychlý start vytvoří jeden z každého objektu.
Příprava ukázkových dat
Tato část vás odkazuje na obsah, který funguje pro účely tohoto rychlého startu.
Přihlaste se k webu Azure Portal pomocí svého účtu Azure a přejděte ke svému účtu Azure Storage.
V levém podokně v části Úložiště dat vyberte Kontejnery.
Vytvořte nový kontejner a pak nahrajte dokumenty PDF plánu stavu použité pro účely tohoto rychlého startu.
V levém podokně v části Řízení přístupu přiřaďte roli Čtenář dat objektů blob služby Storage k identitě vyhledávací služby. Nebo získejte připojovací řetězec k účtu úložiště ze stránky Přístupové klíče.
Volitelně můžete synchronizovat odstranění v kontejneru s odstraněními v indexu vyhledávání. Následující kroky vám umožní nakonfigurovat indexer pro detekci odstranění:
Pokud používáte nativní obnovitelné odstranění, v Azure Storage se nevyžadují žádné další kroky.
V opačném případě přidejte vlastní metadata, která indexer může zkontrolovat a určit, které objekty blob jsou označené k odstranění. Zadejte vlastní vlastnost popisný název. Můžete například pojmenovat vlastnost IsDeleted, která je nastavená na hodnotu false. Proveďte to pro každý objekt blob v kontejneru. Později, když chcete odstranit objekt blob, změňte vlastnost na true. Další informace najdete v tématu Změna a odstranění detekce při indexování ze služby Azure Storage.
Nastavení modelů vkládání
Průvodce může používat modely vkládání nasazené z Azure OpenAI, Azure AI Vision nebo z katalogu modelů na portálu Azure AI Foundry.
Průvodce podporuje vkládání textu ada-002, text-embedding-3-large a text-embedding-3-small. Průvodce interně volá dovednosti AzureOpenAIEmbedding pro připojení k Azure OpenAI.
Přihlaste se k webu Azure Portal pomocí svého účtu Azure a přejděte k prostředku Azure OpenAI.
Nastavení oprávnění:
V nabídce vlevo vyberte Řízení přístupu.
Vyberte Přidat a pak vyberte Přidat přiřazení role.
V části Role funkce úlohy vyberte Uživatele OpenAI služeb Cognitive Services a pak vyberte Další.
V části Členové vyberte Spravovanou identitu a pak vyberte Členové.
Vyfiltrujte podle předplatného a typu prostředku (vyhledávací služby) a pak vyberte spravovanou identitu vyhledávací služby.
Vyberte Zkontrolovat + přiřadit.
Na stránce Přehled vyberte Kliknutím sem zobrazíte koncové body. Pokud potřebujete zkopírovat koncový bod nebo klíč rozhraní API, klikněte sem a spravujte klíče. Tyto hodnoty můžete vložit do průvodce, pokud používáte prostředek Azure OpenAI s ověřováním na základě klíče.
V části Správa prostředků a nasazení modelu vyberte Spravovat nasazení a otevřete Azure AI Foundry.
Zkopírujte název
text-embedding-ada-002nasazení nebo jiný podporovaný model vkládání. Pokud model vkládání nemáte, nasaďte ho teď.
Spuštění průvodce
Přihlaste se k webu Azure Portal pomocí svého účtu Azure a přejděte na Search Azure AI.
Na stránce Přehled vyberte Importovat a vektorizovat data.

Připojení k datům
Dalším krokem je připojení ke zdroji dat, který se má použít pro index vyhledávání.
V připojení k datům vyberte Azure Blob Storage.
Zadejte předplatné Azure.
Zvolte účet úložiště a kontejner, který data poskytuje.
Určete, jestli chcete podporu detekce odstranění. Při následných spuštěních indexování se index vyhledávání aktualizuje, aby odebral všechny vyhledávací dokumenty na základě obnovitelně odstraněných objektů blob ve službě Azure Storage.
- Objekty blob podporují obnovitelné odstranění nativního objektu blob nebo obnovitelné odstranění pomocí vlastních dat.
- V Azure Storage musíte mít dříve povolené obnovitelné odstranění a volitelně jste přidali vlastní metadata , která indexování dokáže rozpoznat jako příznak odstranění. Další informace o těchto krocích najdete v tématu Příprava ukázkových dat.
- Pokud jste nakonfigurovali objekty blob pro obnovitelné odstranění pomocí vlastních dat, zadejte v tomto kroku dvojici název-hodnota vlastnosti metadat. Doporučujeme "IsDeleted". Pokud je vlastnost IsDeleted nastavená na hodnotu true u objektu blob, indexer zahodí odpovídající vyhledávací dokument při dalším spuštění indexeru.
Průvodce nekontroluje platné nastavení služby Azure Storage nebo vyvolá chybu, pokud nejsou splněné požadavky. Místo toho detekce odstranění nefunguje a index vyhledávání bude pravděpodobně shromažďovat osamocené dokumenty v průběhu času.
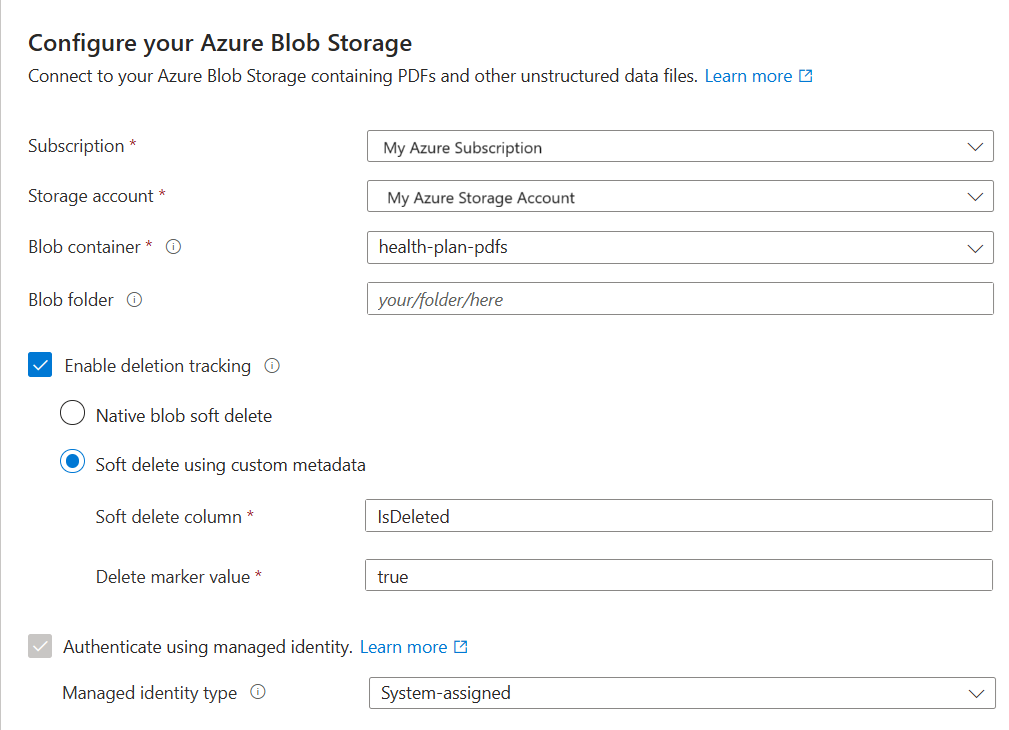
Určete, jestli se má vaše vyhledávací služba připojit ke službě Azure Storage pomocí své spravované identity.
- Zobrazí se výzva, abyste zvolili identitu spravovanou systémem nebo spravovanou uživatelem.
- Identita by měla mít v Azure Storage roli Čtenář dat objektů blob služby Storage.
- Tento krok nepřeskočte. Při indexování dojde k chybě připojení, pokud se průvodce nemůže připojit ke službě Azure Storage.
Vyberte Další.
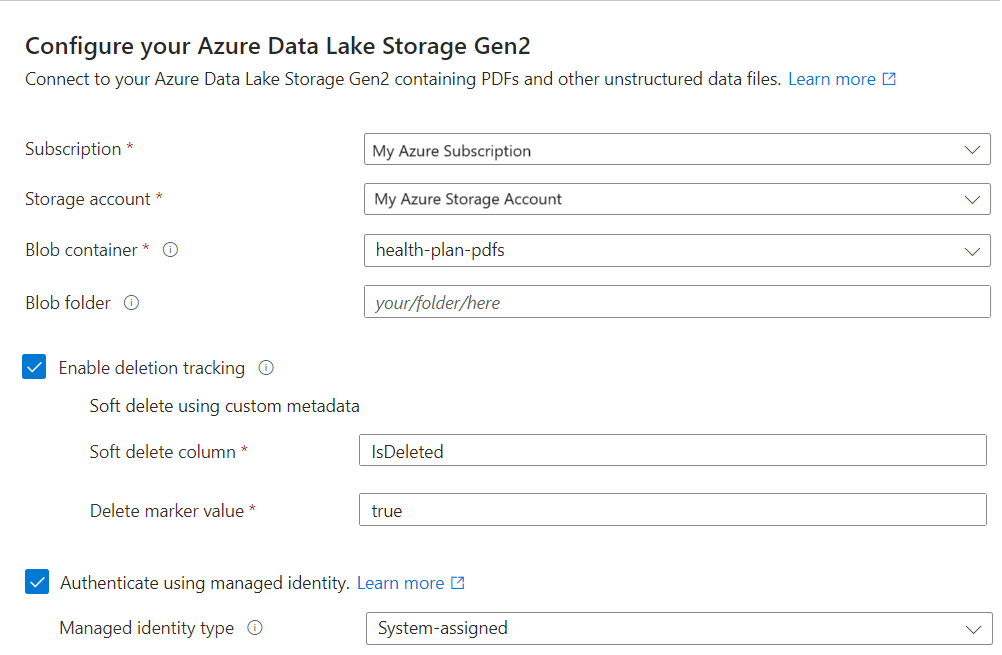
Vektorizace textu
V tomto kroku zadejte model vkládání pro vektorizaci dat v bloku dat.
Bloky dat jsou integrované a nekonfigurovatelné. Platná nastavení jsou:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
Na stránce Vektorizace textu zvolte zdroj modelu vkládání:
- Azure OpenAI
- Katalog modelů Azure AI Foundry
- Existující multimodální prostředek Azure AI Vision ve stejné oblasti jako Azure AI Search. Pokud ve stejné oblasti není žádný účet azure AI Services s více službami, tato možnost není dostupná.
Zvolte předplatné Azure.
Proveďte výběry podle prostředku:
V případě Azure OpenAI zvolte existující nasazení vkládání textu ada-002, vkládání textu-3-large nebo text-embedding-3-small.
V případě katalogu Azure AI Foundry zvolte existující nasazení modelu vložení Azure nebo Cohere.
U multimodálních vkládání AI Vision vyberte účet.
Další informace najdete v tématu Nastavení modelů vkládání dříve v tomto článku.
Určete, jestli se má vyhledávací služba ověřovat pomocí klíče rozhraní API nebo spravované identity.
- Identita by měla mít roli uživatele služeb Cognitive Services v účtu Azure AI s více službami.
Zaškrtněte políčko, které potvrzuje účinky fakturace používání těchto prostředků.
Vyberte Další.
Vektorizace a rozšiřování obrázků
Soubory PDF plánu stavu obsahují firemní logo, ale jinak neexistují žádné obrázky. Pokud používáte ukázkové dokumenty, můžete tento krok přeskočit.
Pokud ale pracujete s obsahem, který obsahuje užitečné obrázky, můžete AI použít dvěma způsoby:
Použijte podporovaný model vkládání obrázků z katalogu nebo zvolte multimodální rozhraní API služby Azure AI Vision pro vložení obrázků.
K rozpoznávání textu v obrázcích použijte optické rozpoznávání znaků (OCR). Tato možnost vyvolá dovednost OCR ke čtení textu z obrázků.
Azure AI Search a prostředek Azure AI musí být ve stejné oblasti nebo musí být nakonfigurované pro připojení pro fakturaci bez klíčů.
Na stránce Vektorizace obrázků zadejte typ připojení, které má průvodce vytvořit. V případě vektorizace obrázků se průvodce může připojit k vkládání modelů na portálu Azure AI Foundry nebo azure AI Vision.
Zadejte předplatné.
Pro katalog modelů Azure AI Foundry zadejte projekt a nasazení. Další informace najdete v tématu Nastavení modelů vkládání dříve v tomto článku.
Volitelně můžete prolomit binární obrázky (například naskenované soubory dokumentů) a použít OCR k rozpoznávání textu.
Zaškrtněte políčko, které potvrzuje účinky fakturace používání těchto prostředků.

Vyberte Další.
Přidání sémantického řazení
Na stránce Upřesnit nastavení můžete volitelně přidat sémantické řazení, aby se výsledky na konci provádění dotazu přeřadily. Přehodnocování podporuje nejvíce séanticky relevantní shody na vrcholu.
Mapování nových polí
Klíčové body týkající se tohoto kroku:
- Schéma indexu poskytuje vektorová a nevectorová pole pro blokovaná data.
- Můžete přidat pole, ale nemůžete odstranit ani upravit vygenerovaná pole.
- Režim analýzy dokumentů vytváří bloky dat (jeden vyhledávací dokument na jeden blok dat).
Na stránce Upřesnit nastavení můžete volitelně přidat nová pole za předpokladu, že zdroj dat poskytuje metadata nebo pole, která se při prvním průchodu nezabírají. Ve výchozím nastavení průvodce vygeneruje následující pole s těmito atributy:
| Pole | Platí pro | Popis |
|---|---|---|
| chunk_id | Vektory textu a obrázku | Pole vygenerovaného řetězce Prohledávatelné, načístelné, řaditelné. Toto je klíč dokumentu indexu. |
| text_parent_id | Textové vektory | Pole vygenerovaného řetězce Načístelné, filtrovatelné. Identifikuje nadřazený dokument, ze kterého pochází blok dat. |
| chunk | Vektory textu a obrázku | Pole Řetězce. Lidsky čitelná verze datového bloku Prohledávatelné a načístelné, ale nefiltrovatelné, fasetové nebo řaditelné. |
| title | Vektory textu a obrázku | Pole Řetězce. Název dokumentu čitelný pro člověka nebo název stránky nebo číslo stránky Prohledávatelné a načístelné, ale nefiltrovatelné, fasetové nebo řaditelné. |
| text_vector | Textové vektory | Collection(Edm.single). Vektorové znázornění bloku dat Prohledávatelné a načístelné, ale nefiltrovatelné, fasetové nebo řaditelné. |
Vygenerovaná pole ani jejich atributy nemůžete upravovat, ale pokud je zdroj dat poskytuje, můžete přidat nová pole. Azure Blob Storage například poskytuje kolekci polí metadat.
Vyberte Přidat nový.
Ze seznamu dostupných polí zvolte zdrojové pole, zadejte název pole pro index a podle potřeby přijměte výchozí datový typ nebo přepsání.
Pole metadat jsou prohledávatelná, ale nedají se načíst, filtrovatelná, fasetová nebo řaditelná.
Pokud chcete obnovit schéma do původní verze, vyberte Obnovit .
Plánování indexování
Na stránce Upřesnit nastavení můžete volitelně zadat plán spuštění indexeru.
- Až budete hotovi se stránkou Upřesnit nastavení, vyberte Další.
Dokončení průvodce
Na stránce Kontrola konfigurace zadejte předponu pro objekty, které průvodce vytvoří. Běžná předpona vám pomůže udržet si přehled.
Vyberte Vytvořit.
Po dokončení konfigurace průvodce vytvoří následující objekty:
Připojení ke zdroji dat
Indexujte pomocí vektorových polí, vektorizátorů, vektorových profilů a vektorových algoritmů. Během pracovního postupu průvodce nemůžete navrhnout ani upravit výchozí index. Indexy odpovídají rozhraní REST API verze 2024-05-01-preview.
Sada dovedností s dovedností Rozdělení textu pro blokování dat a vloženou dovedností pro vektorizaci. Dovednost vkládání je dovednost AzureOpenAIEmbeddingModel pro Azure OpenAI nebo dovednost AML pro katalog modelů Azure AI Foundry. Sada dovedností má také konfiguraci projekcí indexu , která umožňuje mapování dat z jednoho dokumentu ve zdroji dat na odpovídající bloky dat v indexu "child".
Indexer s mapováním polí a mapováním výstupních polí (pokud je to možné).
Kontrola výsledků
Průzkumník služby Search přijímá textové řetězce jako vstup a pak vektorizuje text pro provádění vektorového dotazu.
Na webu Azure Portal přejděte do indexů správy>vyhledávání a vyberte index, který jste vytvořili.
Vyberte možnosti dotazu a skryjte vektorové hodnoty ve výsledcích hledání. Tento krok usnadňuje čtení výsledků hledání.
V nabídce Zobrazení vyberte zobrazení JSON, abyste do parametru vektorového
textdotazu mohli zadat text pro vektorový dotaz.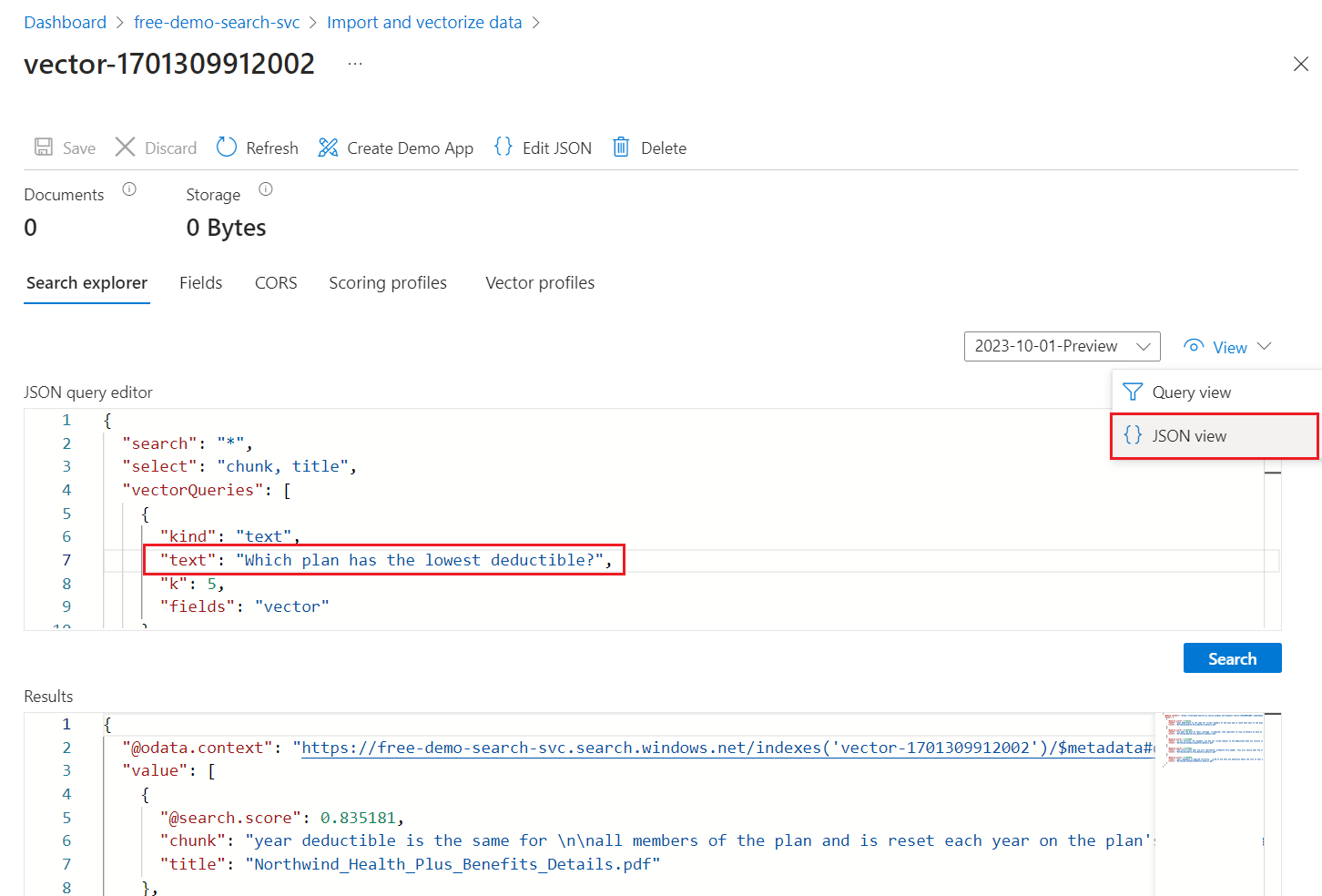
Výchozí dotaz je prázdné hledání (
"*"), ale obsahuje parametry pro vrácení odpovídajících čísel. Jedná se o hybridní dotaz, který paralelně spouští textové a vektorové dotazy. Zahrnuje sémantické hodnocení. Určuje, která pole se mají ve výsledcích vrátit prostřednictvímselectpříkazu.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Zástupné symboly hvězdičky (
*) nahraďte otázkou související s plány stavu, napříkladWhich plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Výběrem možnosti Hledat spusťte dotaz.
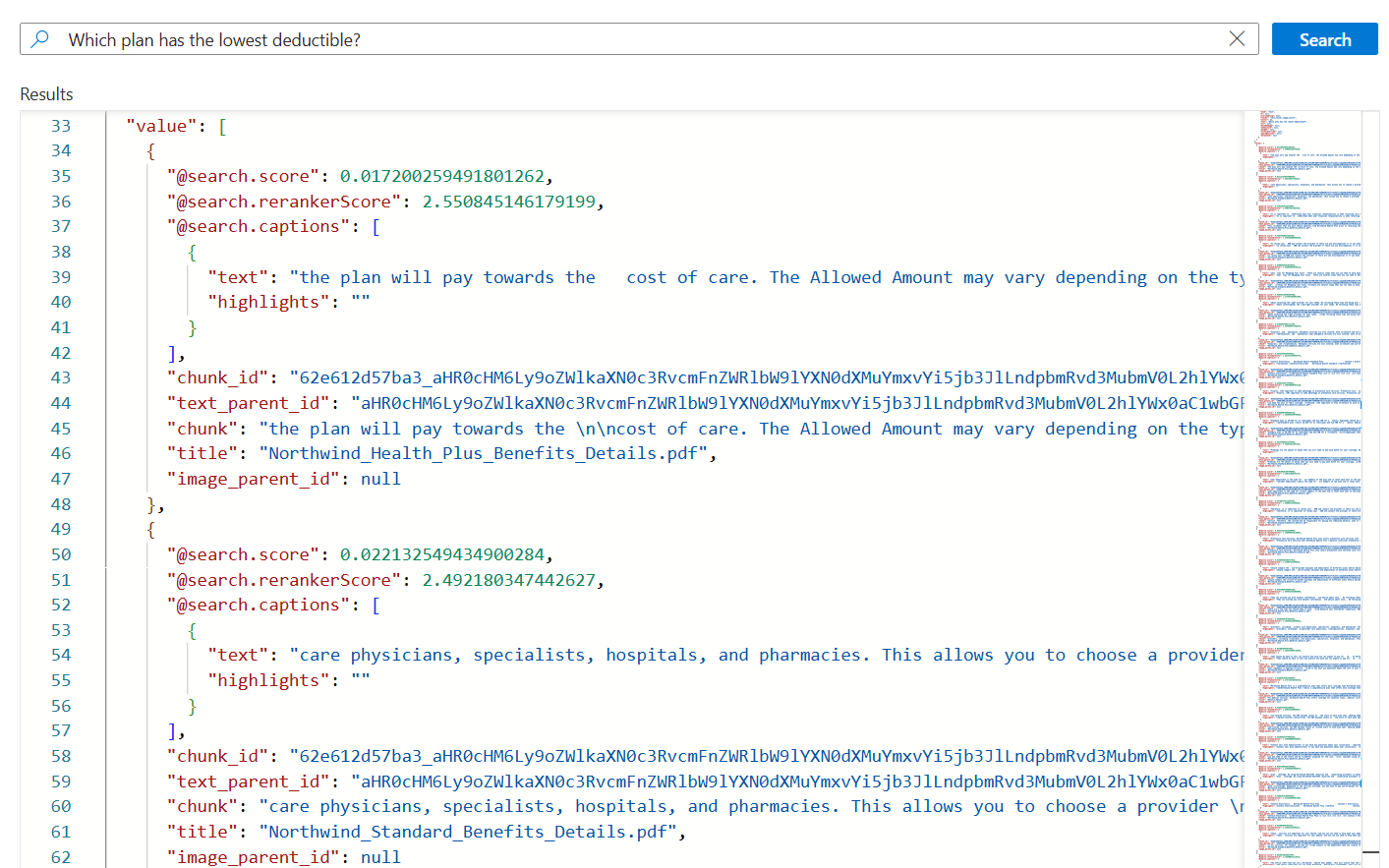
Každý dokument je blokem původního souboru PDF. Pole
titleukazuje, ze kterého souboru PDF blok pochází. Každýchunkje docela dlouhý. Pokud chcete přečíst celou hodnotu, můžete ho zkopírovat a vložit do textového editoru.Pokud chcete zobrazit všechny bloky dat z konkrétního dokumentu, přidejte filtr pro
title_parent_idpole pro konkrétní PDF. Pokud chcete ověřit, že je toto pole filtrovatelné, můžete zkontrolovat kartu Pole v indexu.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Vyčištění
Azure AI Search je fakturovatelný prostředek. Pokud ho už nepotřebujete, odstraňte ho z předplatného, abyste se vyhnuli poplatkům.
Další krok
V tomto rychlém startu jste se seznámili s průvodcem importem a vektorizací dat , který vytvoří všechny potřebné objekty pro integrovanou vektorizaci. Pokud chcete podrobně prozkoumat jednotlivé kroky, vyzkoušejte integrovaný vektorizační vzorek.