Úložiště znalostí ve službě Azure AI Search
Úložiště znalostí je sekundární úložiště pro obsah obohacený O AI vytvořený sadou dovedností ve službě Azure AI Search. Ve službě Azure AI Search úloha indexování vždy odesílá výstup do indexu vyhledávání, ale pokud připojíte sadu dovedností k indexeru, můžete volitelně také odeslat výstup obohacený o AI do kontejneru nebo tabulky ve službě Azure Storage. Úložiště znalostí lze použít k nezávislé analýze nebo zpracování v podřízených scénářích, jako je dolování znalostí.
Dva výstupy indexování, indexu vyhledávání a úložiště znalostí, se vzájemně vylučují produkty stejného kanálu. Jsou odvozeny ze stejných vstupů a obsahují stejná data, ale jejich obsah je strukturovaný, uložený a používaný v různých aplikacích.

Úložiště znalostí je fyzicky Azure Storage, azure Table Storage, Azure Blob Storage nebo obojí. Jakýkoli nástroj nebo proces, který se může připojit ke službě Azure Storage, může využívat obsah úložiště znalostí. Azure AI Search nepodporuje dotazy pro načítání obsahu z úložiště znalostí.
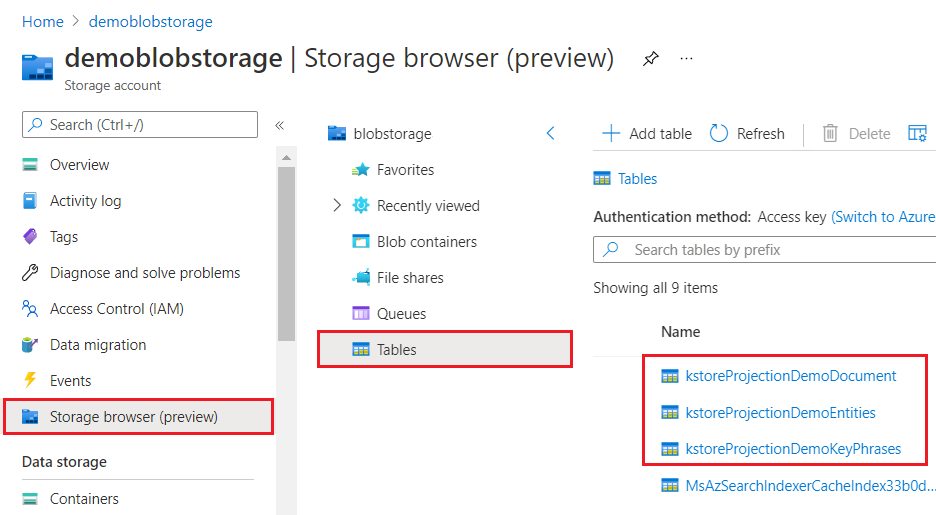
Při prohlížení prostřednictvím webu Azure Portal vypadá úložiště znalostí jako jakákoli jiná kolekce tabulek, objektů nebo souborů. Následující snímek obrazovky ukazuje úložiště znalostí složené ze tří tabulek. Můžete přijmout konvenci vytváření názvů, jako je předpona kstore , aby byl obsah pohromadě.
Výhody úložiště znalostí
Hlavními výhodami úložiště znalostí jsou dvounásobný: flexibilní přístup k obsahu a schopnost tvarovat data.
Na rozdíl od indexu vyhledávání, ke kterému je možné přistupovat pouze prostřednictvím dotazů ve službě Azure AI Search, je úložiště znalostí přístupné pro jakýkoli nástroj, aplikaci nebo proces, který podporuje připojení ke službě Azure Storage. Tato flexibilita otevírá nové scénáře pro využívání analyzovaného a rozšířeného obsahu vytvořeného kanálem rozšiřování.
Stejnou sadu dovedností, která rozšiřuje data, lze také použít k tvarování dat. Některé nástroje, jako je Power BI, fungují lépe s tabulkami, zatímco úloha datových věd může vyžadovat složitou datovou strukturu ve formátu objektu blob. Přidání dovednosti Shaper do sady dovedností vám dává kontrolu nad tvarem dat. Tyto obrazce pak můžete předat projekcím, ať už tabulkám nebo objektům blob, a vytvořit tak fyzické datové struktury, které odpovídají zamýšlenému použití dat.
Následující video vysvětluje jak tyto výhody, tak i další.
Definice úložiště znalostí
Úložiště znalostí je definováno v definici sady dovedností a má dvě komponenty:
Připojovací řetězec do Azure Storage
Projekce, které určují, jestli se úložiště znalostí skládá z tabulek, objektů nebo souborů. Prvek projekce je pole. V jednom úložišti znalostí můžete vytvořit více sad kombinací tabulek-object-file.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
Typ projekce, kterou zadáte v této struktuře, určuje typ úložiště používaného úložištěm znalostí, ale ne jeho strukturu. Pole v tabulkách, objektech a souborech jsou určena výstupem dovednosti Shaper, pokud vytváříte úložiště znalostí prostřednictvím kódu programu, nebo průvodcem importem dat, pokud používáte Azure Portal.
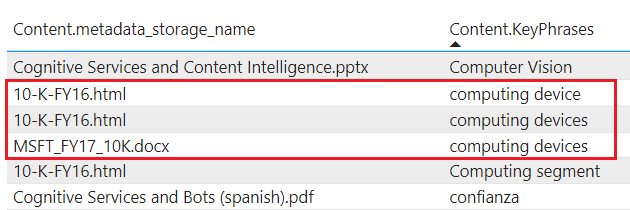
tablesrozšíření obsahu projektu do služby Table Storage Definujte projekci tabulky, pokud potřebujete tabulkové struktury generování sestav pro vstupy analytickým nástrojům nebo exportovat jako datové rámce do jiných úložišť dat. Pokud chcete získat podmnožinu nebo průřez obohacených dokumentů, můžete zadat vícetablesve stejné skupině projekce. Ve stejné skupině projekcí jsou relace mezi tabulkami zachovány, abyste s nimi mohli pracovat.Projektovaný obsah není agregovaný ani normalizovaný. Následující snímek obrazovky ukazuje tabulku seřazenou podle klíčové fráze s nadřazeným dokumentem označeným v sousedním sloupci. Na rozdíl od příjmu dat během indexování neexistuje žádná lingvistická analýza ani agregace obsahu. Tvary a rozdíly v množném čísle jsou považovány za jedinečné instance.
objectsdokument JSON projektu do úložiště objektů blob. Fyzická reprezentace jeobjecthierarchická struktura JSON, která představuje obohacený dokument.filessoubory obrázků projektu do úložiště objektů blob. Afileje obrázek extrahovaný z dokumentu, přenesený beze změny do úložiště objektů blob. I když se jmenuje "files", zobrazuje se ve službě Blob Storage, nikoli v úložišti souborů.
Vytvoření úložiště znalostí
K vytvoření úložiště znalostí použijte Azure Portal nebo rozhraní API.
Potřebujete Azure Storage, sadu dovedností a indexer. Protože indexery vyžadují index vyhledávání, musíte také zadat definici indexu.
Projděte si přístup k webu Azure Portal, který vám umožní nejrychlejší trasu do hotového úložiště znalostí. Nebo zvolte rozhraní REST API, které vám pomůže lépe pochopit, jak jsou objekty definované a související.
Pomocí průvodce importem dat vytvořte první úložiště znalostí ve čtyřech krocích.
Definujte zdroj dat obsahující data, která chcete rozšířit.
Definujte sadu dovedností. Sada dovedností určuje kroky rozšiřování a úložiště znalostí.
Definujte schéma indexu. Možná ho nepotřebujete, ale indexery ho vyžadují. Průvodce může odvodit index.
Dokončete práci v průvodci. V tomto posledním kroku dochází k extrakci, rozšiřování a vytváření úložiště znalostí.
Průvodce automatizuje několik úloh. Konkrétně se pro vás vytvoří tvarování i projekce (definice fyzických datových struktur ve službě Azure Storage).
Připojení s aplikacemi
Jakmile v úložišti existuje obohacený obsah, můžete k prozkoumání, analýze nebo využívání obsahu použít jakýkoli nástroj nebo technologie, které se připojují ke službě Azure Storage. Následující seznam představuje začátek:
Průzkumník služby Storage nebo prohlížeč úložiště na webu Azure Portal k zobrazení rozšířené struktury a obsahu dokumentu. Zvažte to jako základní nástroj pro zobrazení obsahu úložiště znalostí.
Power BI pro vytváření sestav a analýzu
Azure Data Factory pro další manipulaci.
Životní cyklus obsahu
Při každém spuštění indexeru a sady dovedností se úložiště znalostí aktualizuje, pokud se sada dovedností nebo podkladová zdrojová data změnila. Všechny změny získané indexerem se šíří prostřednictvím procesu rozšiřování do projekcí v úložišti znalostí a zajišťují, aby data, která se promítají, představují aktuální reprezentaci obsahu ve zdrojovém zdroji dat.
Poznámka:
I když můžete upravit data v projekcích, všechny úpravy se přepíšou při dalším vyvolání kanálu za předpokladu, že se dokument ve zdrojových datech aktualizuje.
Změny ve zdrojových datech
U zdrojů dat, které podporují sledování změn, indexer zpracuje nové a změněné dokumenty a vynechá stávající dokumenty, které už byly zpracovány. Informace o časovém razítku se liší podle zdroje dat, ale v kontejneru objektů blob se indexer podívá na lastmodified datum a určí, které objekty blob je potřeba ingestovat.
Změny sady dovedností
Pokud provádíte změny v sadě dovedností, měli byste povolit ukládání do mezipaměti obohacených dokumentů , abyste mohli opakovaně používat existující rozšiřování, pokud je to možné.
Bez přírůstkového ukládání do mezipaměti bude indexer vždy zpracovávat dokumenty v pořadí od horního horního znaméčku, aniž by se zostal. U objektů blob by indexer zpracovával objekty blob seřazené podle lastModified, bez ohledu na změny nastavení indexeru nebo sady dovedností. Pokud změníte sadu dovedností, dříve zpracované dokumenty se neaktualizují tak, aby odrážely novou sadu dovedností. Dokumenty zpracovávané po změně sady dovedností budou používat novou sadu dovedností, což vede k tomu, že dokumenty indexu jsou kombinací starých a nových sad dovedností.
S přírůstkovým ukládáním do mezipaměti a po aktualizaci sady dovedností indexer znovu použije všechny rozšiřování, na které nemá změna sady dovedností vliv. Upstreamové rozšiřování se načítají z mezipaměti, stejně jako všechny rozšiřování, které jsou nezávislé a izolované od dovednosti, která se změnila.
Deletions
I když indexer vytváří a aktualizuje struktury a obsah ve službě Azure Storage, neodstraní je. Projekce nadále existují, i když se indexer nebo sada dovedností odstraní. Jako vlastník účtu úložiště byste měli odstranit projekci, pokud už ji nepotřebujete.
Další kroky
Úložiště znalostí nabízí trvalost obohacených dokumentů, užitečné při navrhování sady dovedností nebo vytváření nových struktur a obsahu pro použití všemi klientskými aplikacemi, které mají přístup k účtu Azure Storage.
Nejjednodušší přístup k vytváření obohacených dokumentů je prostřednictvím webu Azure Portal, ale klient REST a rozhraní REST API můžou poskytnout lepší přehled o tom, jak se objekty vytvářejí a odkazují programově.