Indexery ve službě Azure AI Search
Indexer ve službě Azure AI Search je prohledávací modul, který extrahuje textová data z cloudových zdrojů dat a naplní index vyhledávání pomocí mapování polí na pole mezi zdrojovými daty a indexem vyhledávání. Tento přístup se někdy označuje jako "model vyžádání", protože vyhledávací služba načítá data, aniž byste museli psát jakýkoli kód, který přidává data do indexu.
Indexery také řídí spouštění sady dovedností a rozšiřování AI, kde můžete nakonfigurovat dovednosti pro integraci dalšího zpracování obsahu na cestě k indexu. Několik příkladů je OCR přes soubory obrázků, dovednosti rozdělení textu pro bloky dat a volání vložených modelů pro generování vektorů pro vektorové vyhledávání.
Indexery cílí na podporované zdroje dat. Konfigurace indexeru určuje zdroj dat (zdroj) a index vyhledávání (cíl). Několik zdrojů, jako je Azure Blob Storage, má více vlastností konfigurace indexeru specifických pro daný typ obsahu.
Indexery můžete spouštět na vyžádání nebo v plánu opakované aktualizace dat, který se spouští tak často jako každých pět minut. Častější aktualizace zabraňují použití indexerů a vyžadují, abyste implementovali model nabízených oznámení, který současně odešle data do služby Azure AI Search i do externího zdroje dat pro synchronizaci dat.
Vyhledávací služba spouští jednu úlohu indexeru na jednotku vyhledávání. Pokud potřebujete souběžné zpracování, ujistěte se, že máte dostatek replik. Indexery se nespouštějí na pozadí, takže pokud je služba pod tlakem, můžete zjistit větší omezování dotazů než obvykle.
Scénáře indexeru a případy použití
Indexer můžete použít jako jediný způsob příjmu dat nebo v kombinaci s jinými technikami. Následující tabulka shrnuje hlavní scénáře.
| Scénář | Strategie |
|---|---|
| Jeden zdroj dat | Tento vzor je nejjednodušší: jeden zdroj dat je jediným poskytovatelem obsahu pro index vyhledávání. Většina podporovaných zdrojů dat poskytuje určitou formu detekce změn, aby následný indexer spustil rozdíl při přidání nebo aktualizaci obsahu ve zdroji. |
| Více zdrojů dat | Specifikace indexeru může mít pouze jeden zdroj dat, ale samotný index vyhledávání může přijímat obsah z více zdrojů, kde každá úloha indexeru přináší nový obsah z jiného zprostředkovatele dat. Každý zdroj může přispívat svou sdílenou složkou celých dokumentů nebo naplnit vybraná pole v každém dokumentu. Podrobnější pohled na tento scénář najdete v tématu Kurz: Indexování z více zdrojů dat. |
| Více indexerů | Více zdrojů dat se obvykle spáruje s více indexery, pokud potřebujete měnit parametry doby spuštění, plán nebo mapování polí.
Horizontální navýšení kapacity napříč oblastmi ve službě Azure AI Search je variantou tohoto scénáře. V různých oblastech můžete mít kopie stejného indexu vyhledávání. Pokud chcete synchronizovat obsah indexu vyhledávání, můžete mít více indexerů, které načítá ze stejného zdroje dat, kde každý indexer cílí na jiný index vyhledávání v každé oblasti. Paralelní indexování velmi velkých datových sad také vyžaduje strategii více indexerů, kde každý indexer cílí na podmnožinu dat. |
| Transformace obsahu | Indexery řídí spouštění sady dovedností a rozšiřování AI. Transformace obsahu jsou definovány v sadě dovedností, kterou připojíte k indexeru. Dovednosti můžete použít k začlenění bloků dat a vektorizace. |
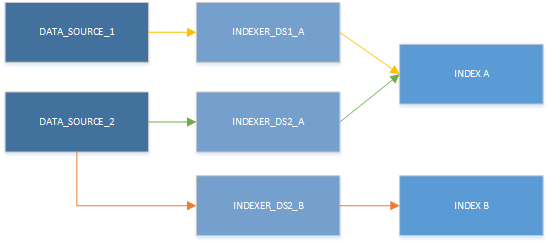
Měli byste naplánovat vytvoření jednoho indexeru pro každou kombinaci cílového indexu a zdroje dat. Můžete mít více indexerů, které se zapisují do stejného indexu, a stejný zdroj dat můžete znovu použít pro více indexerů. Indexer ale může současně využívat pouze jeden zdroj dat a může zapisovat pouze do jednoho indexu. Jak znázorňuje následující obrázek, jeden zdroj dat poskytuje vstup do jednoho indexeru, který pak naplní jeden index:

I když můžete současně použít pouze jeden indexer, prostředky se dají použít v různých kombinacích. Hlavním názorem dalšího obrázku je, že zdroj dat je možné spárovat s více indexery a více indexerů může zapisovat do stejného indexu.
Podporované zdroje dat
Indexery procházejí úložiště dat v Azure a mimo Azure.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure Table Storage
- Spravovaná instance Azure SQL
- SQL Server na Azure Virtual Machines
- Soubory Azure (ve verzi Preview)
- Azure MySQL (ve verzi Preview)
- SharePoint v Microsoftu 365 (ve verzi Preview)
- Azure Cosmos DB pro MongoDB (ve verzi Preview)
- Azure Cosmos DB pro Apache Gremlin (ve verzi Preview)
Azure Cosmos DB pro Cassandra se nepodporuje.
Indexery přijímají zploštěné sady řádků, například tabulku nebo zobrazení, nebo položky v kontejneru nebo složce. Ve většině případů vytvoří jeden hledaný dokument na řádek, záznam nebo položku.
Připojení indexeru ke vzdáleným zdrojům dat je možné provádět pomocí standardních internetových připojení (veřejných) nebo šifrovaných privátních připojení při použití sdíleného privátního propojení. Můžete také nastavit připojení k ověření pomocí spravované identity. Další informace o zabezpečených připojeních najdete v tématu Přístup indexeru k obsahu chráněnému funkcemi zabezpečení sítě Azure a připojení ke zdroji dat pomocí spravované identity.
Fáze indexování
Při počátečním spuštění, když je index prázdný, indexer přečte všechna data zadaná v tabulce nebo kontejneru. Při následných spuštěních může indexer obvykle rozpoznat a načíst pouze data, která se změnila. U dat objektů blob je detekce změn automatická. U jiných zdrojů dat, jako je Azure SQL nebo Azure Cosmos DB, musí být povolená detekce změn.
Pro každý dokument, který obdrží, indexer implementuje nebo koordinuje více kroků, od načtení dokumentu do konečného vyhledávacího webu "předání" pro indexování. Indexer také řídí spouštění a výstupy sady dovedností za předpokladu, že je definována sada dovedností.

Fáze 1: Zdokumentování praskání
Prolomení dokumentů je proces otevírání souborů a extrakce obsahu. Textový obsah lze extrahovat ze souborů ve službě, řádků v tabulce nebo položkách v kontejneru nebo kolekci. Pokud přidáte sadu dovedností a dovednosti k obrázkům, můžete také extrahovat obrázky a zařadíte je do fronty pro zpracování obrázků.
V závislosti na zdroji dat se indexer pokusí extrahovat potenciálně indexovatelný obsah různými operacemi:
Pokud je dokument souborem s vloženými obrázky, jako je PDF, indexer extrahuje text, obrázky a metadata. Indexery můžou otevírat soubory ze služby Azure Blob Storage, Azure Data Lake Storage Gen2 a SharePointu.
Pokud je dokument záznamem v Azure SQL, indexer extrahuje nebinární obsah z každého pole v každém záznamu.
Pokud je dokument záznamem ve službě Azure Cosmos DB, indexer extrahuje nebinární obsah z polí a dílčích polí z dokumentu Azure Cosmos DB.
Fáze 2: Mapování polí
Indexer extrahuje text ze zdrojového pole a odešle ho do cílového pole v indexu nebo úložišti znalostí. Pokud se názvy polí a datové typy shodují, cesta je jasná. Ve výstupu ale můžete chtít jiné názvy nebo typy, v takovém případě potřebujete indexeru sdělit, jak mapovat pole.
Pokud chcete zadat mapování polí, zadejte do definice indexeru zdrojová a cílová pole.
Mapování polí probíhá po prolomení dokumentu, ale před transformacemi, když indexer čte ze zdrojových dokumentů. Při definování mapování polí se hodnota zdrojového pole odešle tak, jak je do cílového pole beze změn.
Fáze 3: Spuštění sady dovedností
Spuštění sady dovedností je volitelný krok, který vyvolá integrované nebo vlastní zpracování AI. Sady dovedností mohou přidat optické rozpoznávání znaků (OCR) nebo jiné formy analýzy obrázků, pokud je obsah binární. Sady dovedností mohou také přidávat zpracování přirozeného jazyka. Můžete například přidat překlad textu nebo extrakci klíčových frází.
Ať už transformace probíhá, provádění sady dovedností je místo, kde probíhá rozšiřování. Pokud je indexer kanálem, můžete si sadu dovedností představit jako "kanál v rámci kanálu".
Fáze 4: Mapování výstupních polí
Pokud zahrnete sadu dovedností, budete muset v definici indexeru zadat mapování výstupních polí. Výstup sady dovedností se projevuje interně jako struktura stromu označovaná jako obohacený dokument. Mapování výstupních polí umožňuje vybrat, které části tohoto stromu se mají mapovat na pole v indexu.
Navzdory podobnosti v názvech vytvářejí mapování výstupních polí a mapování polí přidružení z různých zdrojů. Mapování polí přidružují obsah zdrojového pole k cílovému poli v indexu vyhledávání. Mapování výstupních polí přidružují obsah interního rozšířeného dokumentu (výstupy dovedností) k cílovým polím v indexu. Na rozdíl od mapování polí, která jsou považována za volitelná, se pro veškerý transformovaný obsah, který by měl být v indexu, vyžaduje mapování výstupního pole.
Další obrázek znázorňuje ukázkovou reprezentaci relace ladění indexeru pro fáze indexeru: prolomení dokumentu, mapování polí, spuštění sady dovedností a mapování výstupních polí.

Základní pracovní postup
Indexery můžou nabízet funkce, které jsou jedinečné pro daný zdroj dat. Z toho důvodu se budou některé aspekty konfigurace indexeru nebo zdroje dat lišit podle typu indexeru. Všechny indexery ale sdílejí stejné základní složení a požadavky. Níže najdete popis kroků společných pro všechny indexery.
Krok 1: Vytvoření zdroje dat
Indexery vyžadují objekt zdroje dat, který poskytuje připojovací řetězec a případně přihlašovací údaje. Zdroje dat jsou nezávislé objekty. Více indexerů může použít stejný objekt zdroje dat k načtení více indexů najednou.
Zdroj dat můžete vytvořit pomocí některého z těchto přístupů:
- Na webu Azure Portal na kartě Zdroje dat na stránkách vyhledávací služby vyberte Přidat zdroj dat a určete definici zdroje dat.
- Pomocí webu Azure Portal průvodce importem dat vypíše zdroj dat.
- Pomocí rozhraní REST API volejte vytvořit zdroj dat.
- Pomocí sady Azure SDK pro .NET volejte třídu SearchIndexerDataSourceConnection.
Krok 2: Vytvoření indexu
Indexer automatizuje některé úkoly související s příjmem dat, ale vytváření indexu k nim obvykle nepatří. Předpokladem je, že musíte mít předdefinovaný index, který obsahuje odpovídající cílová pole pro všechna zdrojová pole ve vašem externím zdroji dat. Pole se musí shodovat podle názvu a datového typu. Pokud ne, můžete definovat mapování polí pro vytvoření přidružení.
Další informace najdete v tématu Vytvoření indexu.
Krok 3: Vytvoření a spuštění (nebo naplánování) indexeru
Definice indexeru se skládá z vlastností, které jednoznačně identifikují indexer, určují, který zdroj dat a index se mají použít, a poskytují další možnosti konfigurace, které ovlivňují chování doby běhu, včetně toho, jestli indexer běží na vyžádání nebo podle plánu.
Během provádění indexeru dojde k chybám nebo upozorněním týkajícím se přístupu k datům nebo ověřování sady dovedností. Dokud se nespustí spuštění indexeru, závislé objekty, jako jsou zdroje dat, indexy a sady dovedností, jsou ve vyhledávací službě pasivní.
Další informace najdete v tématu Vytvoření indexeru.
Po prvním spuštění indexeru ho můžete znovu spustit na vyžádání nebo nastavit plán.
Stav indexeru můžete monitorovat na webu Azure Portal nebo prostřednictvím rozhraní API pro získání stavu indexeru. Měli byste také spouštět dotazy na index , abyste ověřili, že výsledek je to, co jste očekávali.
Indexery nemají vyhrazené prostředky pro zpracování. Na základě toho se stav indexerů může před spuštěním zobrazit jako nečinný (v závislosti na jiných úlohách ve frontě) a doby spuštění nemusí být předvídatelné. Další faktory definují také výkon indexeru, například velikost dokumentu, složitost dokumentu, analýzu obrázků, mimo jiné.
Další kroky
Teď, když jste se seznámili s indexery, je dalším krokem kontrola vlastností a parametrů indexeru, plánování a monitorování indexeru. Případně se můžete vrátit do seznamu podporovaných zdrojů dat, kde najdete další informace o konkrétním zdroji.