Kurz k Lakehouse: Vytvoření jezera, ingestování ukázkových dat a sestavení sestavy
V tomto kurzu vytvoříte lakehouse, ingestujete ukázková data do tabulky Delta, použijete transformace tam, kde je to potřeba, a pak vytvoříte sestavy. V tomto kurzu se naučíte:
- Vytvořte datový jezero v Microsoft Fabric
- Stažení a příjem ukázkových zákaznických dat
- Přidání tabulek do sémantického modelu
- Vytvoření sestavy
Pokud nemáte Microsoft Fabric, zaregistrujte si bezplatnou zkušební kapacitu.
Požadavky
- Než vytvoříte lakehouse, musíte vytvořit pracovní prostor Fabric.
- Než budete ingestovat soubor CSV, musíte mít nakonfigurovaný OneDrive. Pokud nemáte nakonfigurovaný OneDrive, zaregistrujte si bezplatnou zkušební verzi Microsoftu 365: bezplatnou zkušební verzi – Vyzkoušejte Microsoft 365 za měsíc.
Vytvoření jezerahouse
V této části vytvoříte lakehouse v Fabric.
V Fabricvyberte z navigačního panelu Pracovní prostory.
Pokud chcete otevřít pracovní prostor, zadejte jeho název do vyhledávacího pole umístěného nahoře a vyberte ho z výsledků hledání.
V pracovním prostoru vyberte Nová položka, pak vyberte Lakehouse.
V dialogovém okně New lakehouse zadejte do pole Název wwilakehouse.
Výběrem možnosti Vytvořit vytvořte a otevřete nový jezerní dům.
Ingestace ukázkových dat
V této části ingestujete ukázková zákaznická data do jezera.
Poznámka:
Pokud nemáte nakonfigurovaný OneDrive, zaregistrujte si bezplatnou zkušební verzi Microsoftu 365: bezplatnou zkušební verzi – Vyzkoušejte Microsoft 365 za měsíc.
Stáhněte si soubor dimension_customer.csv z úložiště ukázek prostředků infrastruktury.
Na kartě Domů v části Získat data v jezeře se zobrazí možnosti načtení dat do jezera. Vyberte Nový tok dat Gen2.
Na nové obrazovce toku dat vyberte Importovat ze souboru Text/CSV.
Na obrazovce Připojit ke zdroji dat vyberte přepínač Nahrát soubor. Přetáhněte dimension_customer.csv soubor, který jste stáhli v kroku 1. Po nahrání souboru vyberte Další.
Na stránce Náhled dat souboru si prohlédněte náhled dat a výběrem možnosti Vytvořit pokračujte a vraťte se zpět na plátno toku dat.
V podokně Nastavení dotazu aktualizujte pole Název na dimension_customer.
Poznámka:
Prostředky infrastruktury ve výchozím nastavení přidají na konec názvu tabulky mezeru a číslo. Názvy tabulek musí být malé a nesmí obsahovat mezery. Přejmenujte ho odpovídajícím způsobem a odeberte všechny mezery z názvu tabulky.
V tomto kurzu jste přidružli zákaznická data k jezeru. Pokud máte další datové položky, které chcete přidružit k jezeře, můžete je přidat:
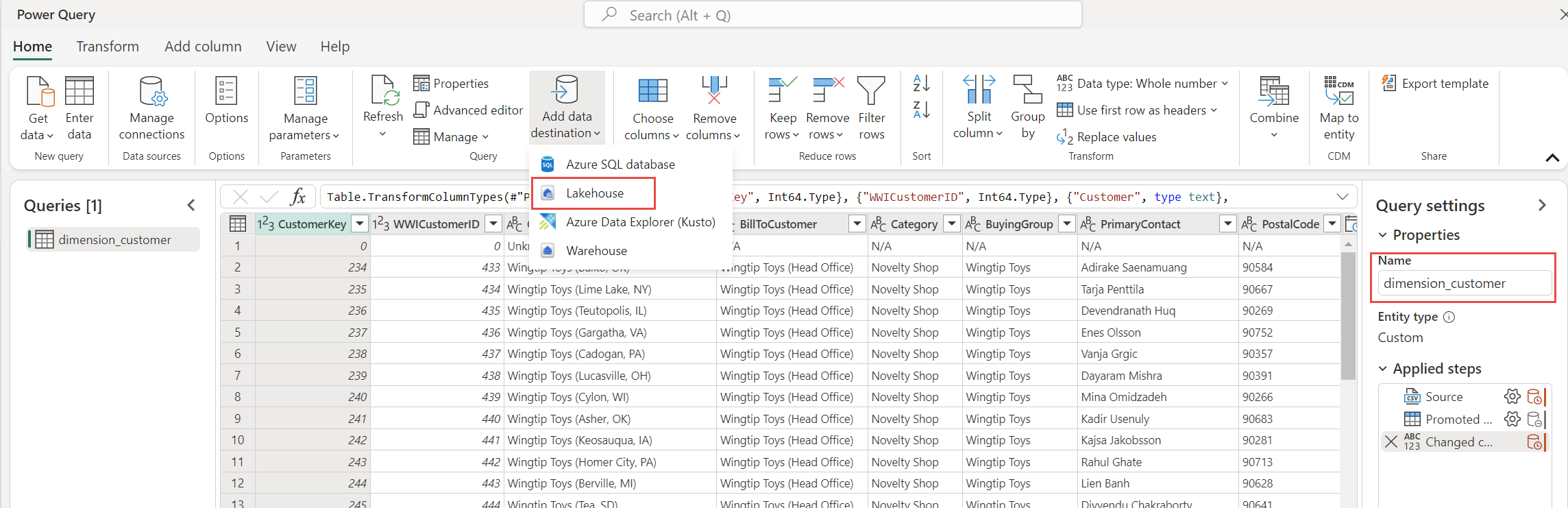
V položkách nabídky vyberte Přidat cíl dat a vyberte Lakehouse. Na obrazovce Připojit k cíli dat se v případě potřeby přihlaste ke svému účtu a vyberte Další.
Přejděte do wwilakehouse v pracovním prostoru.
Pokud tabulka dimension_customer neexistuje, vyberte nastavení Nová tabulka a zadejte název tabulky dimension_customer. Pokud tabulka již existuje, vyberte nastavení Existující tabulka a v seznamu tabulek v Průzkumníku objektů zvolte dimension_customer . Vyberte Další.
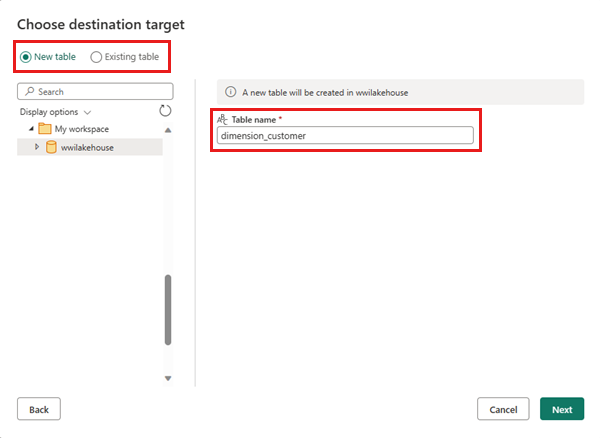
V podokně Zvolit nastavení cíle vyberte Nahradit jako metodu aktualizace. Výběrem možnosti Uložit nastavení se vrátíte na plátno toku dat.
Na plátně toku dat můžete data snadno transformovat na základě vašich obchodních požadavků. Pro zjednodušení neprobínáme žádné změny v tomto kurzu. Pokračujte výběrem možnosti Publikovat v pravém dolním rohu obrazovky.
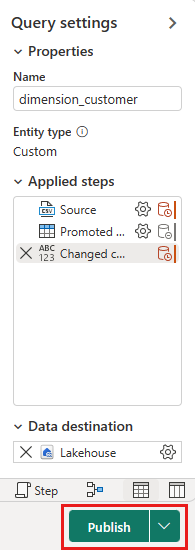
Rotující kruh vedle názvu toku dat označuje, že publikování probíhá v zobrazení položky. Po dokončení publikování vyberte ... a vyberte Vlastnosti. Přejmenujte tok dat na Load Lakehouse Table a vyberte Uložit.
Výběrem možnosti Aktualizovat hned vedle názvu toku dat aktualizujte tok dat. Tato možnost spustí tok dat a přesune data ze zdrojového souboru do tabulky Lakehouse. Zatímco probíhá, uvidíte v zobrazení položky rotující kruh pod obnoveným sloupcem.
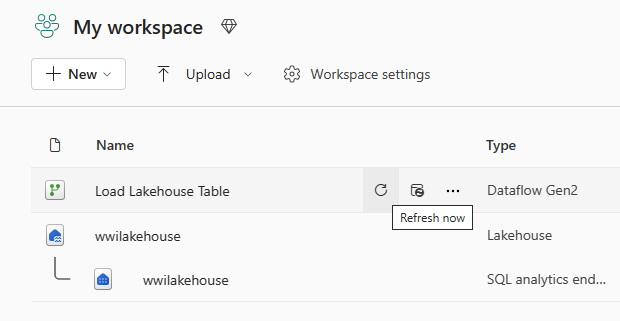
Po aktualizaci toku dat vyberte na navigačním panelu nový lakehouse a zobrazte tabulku dimension_customer Delta.
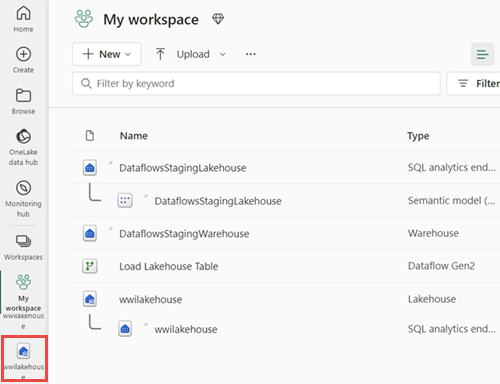
Výběrem tabulky zobrazíte náhled dat. K dotazování dat pomocí příkazů SQL můžete také použít koncový bod analýzy SQL lakehouse. V rozevírací nabídce Lakehouse v pravém horním rohu obrazovky vyberte koncový bod sql Analytics.
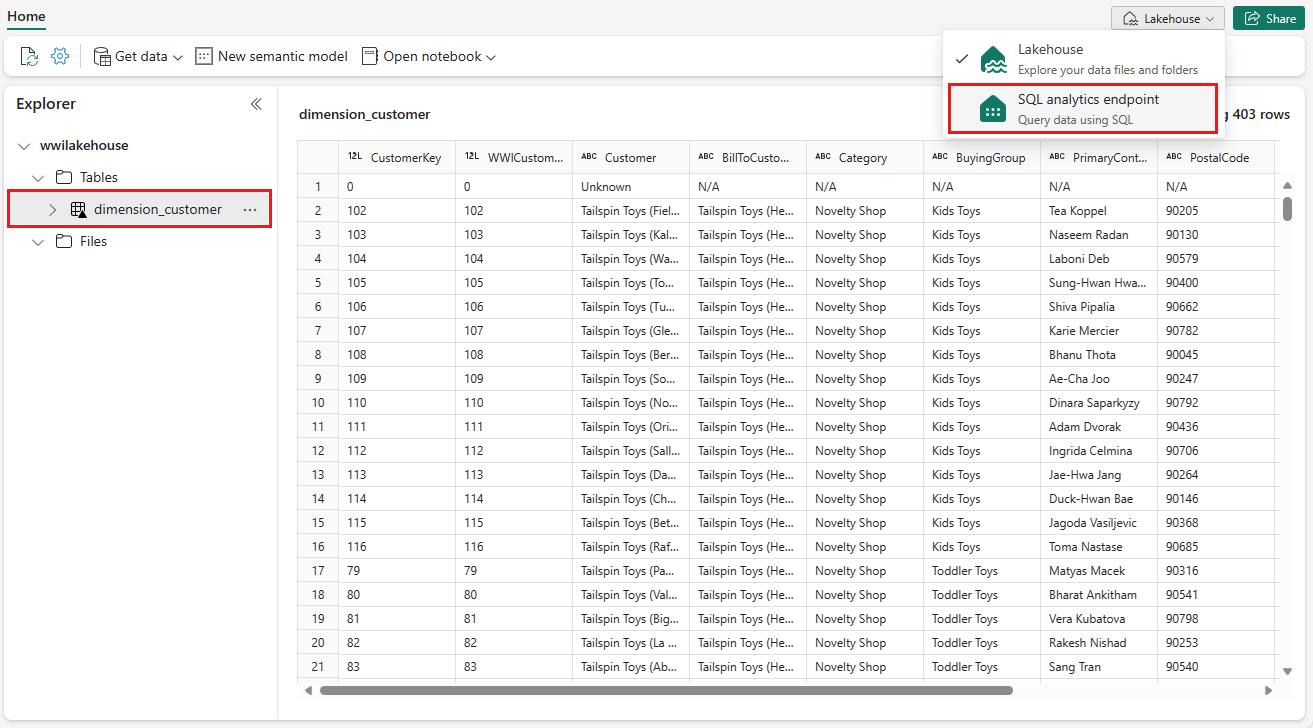
Výběrem tabulky dimension_customer zobrazíte náhled svých dat, nebo vyberte Nový dotaz SQL pro zápis příkazů SQL.
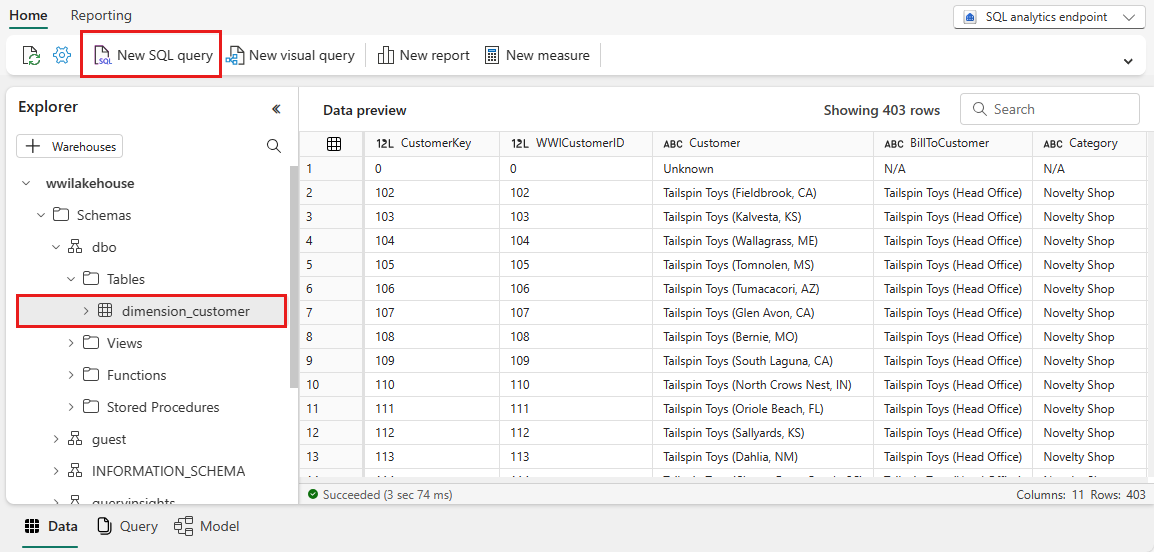
Následující ukázkový dotaz agreguje počet řádků na základě sloupce BuyingGroup v tabulce dimension_customer . Soubory dotazů SQL se automaticky ukládají pro budoucí referenci a tyto soubory můžete podle potřeby přejmenovat nebo odstranit.
Pokud chcete skript spustit, vyberte ikonu Spustit v horní části souboru skriptu.
SELECT BuyingGroup, Count(*) AS Total FROM dimension_customer GROUP BY BuyingGroup



Vytvoření sestavy
V této části sestavíte sestavu z přijatých dat.
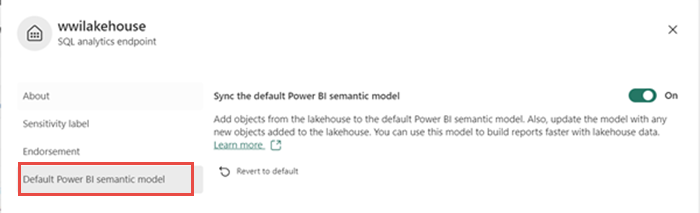
Dříve se do sémantického modelu automaticky přidaly všechny tabulky a zobrazení jezera. V nedávných aktualizacích nových jezer musíte do sémantického modelu ručně přidat tabulky. Otevřete lakehouse a přepněte do zobrazení koncového bodu analýzy SQL. Na kartě Vytváření sestav vyberte Spravovat výchozí sémantický model a vyberte tabulky, které chcete přidat do sémantického modelu. V tomto případě vyberte tabulku dimension_customer .
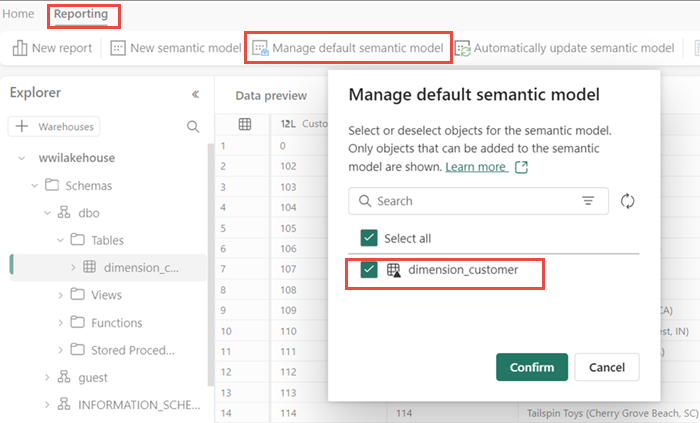
Pokud chcete zajistit, aby se tabulky v sémantickém modelu vždy synchronizovaly, přepněte do zobrazení koncového bodu analýzy SQL a otevřete podokno nastavení lakehouse. Vyberte Výchozí sémantický model Power BI a zapněte Synchronizaci výchozího sémantického modelu Power BI. Další informace najdete v tématu Výchozí sémantické modely Power BI.
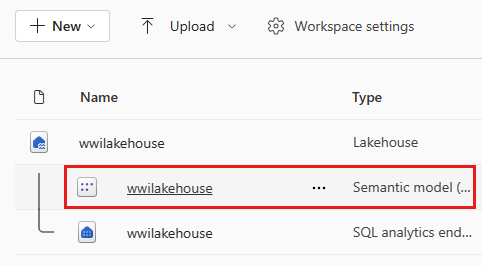
Po přidání tabulky vytvoří Fabric sémantický model se stejným názvem jako je lakehouse.
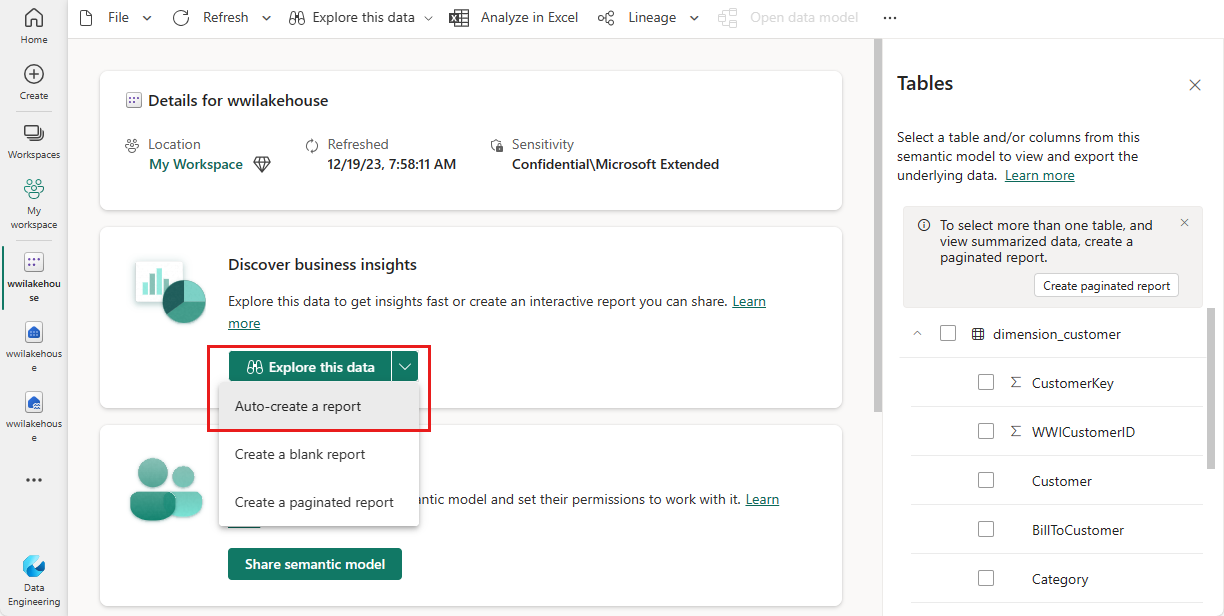
V podokně sémantický model můžete zobrazit všechny tabulky. Můžete vytvářet sestavy úplně od začátku, stránkovaných sestav nebo nechat Power BI automaticky vytvořit sestavu na základě vašich dat. Pro účely tohoto kurzu vyberte v části Prozkoumat tato data možnost Automaticky vytvořit sestavu. V dalším kurzu vytvoříme sestavu úplně od začátku.
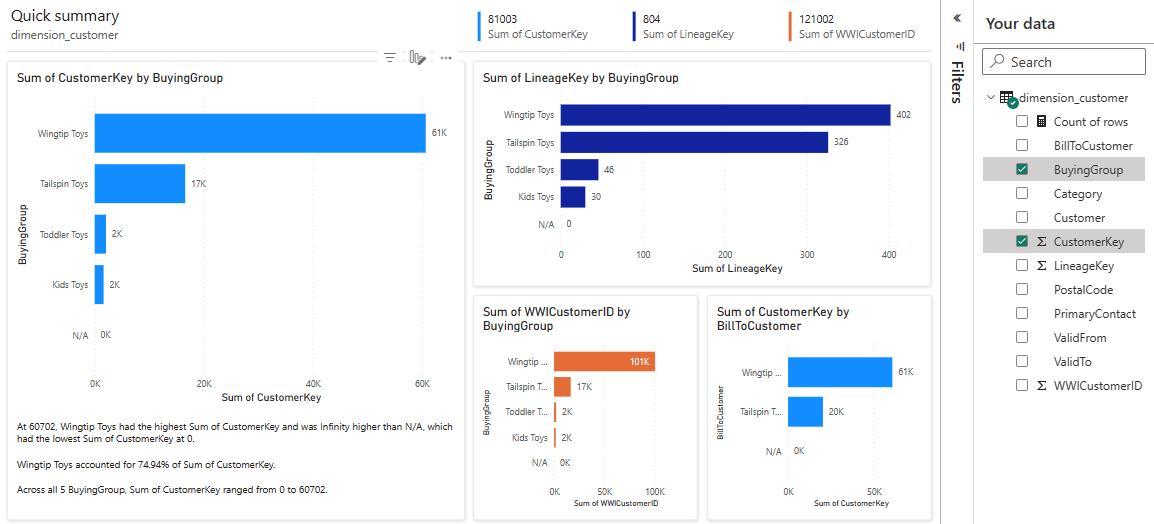
Vzhledem k tomu, že tabulka je dimenze a v ní nejsou žádné míry, Power BI vytvoří míru pro počet řádků a agreguje ji napříč různými sloupci a vytvoří různé grafy, jak je znázorněno na následujícím obrázku. Tuto sestavu můžete uložit pro budoucnost výběrem možnosti Uložit na horním pásu karet. V této sestavě můžete provádět další změny tak, aby splňovaly vaše požadavky zahrnutím nebo vyloučením jiných tabulek nebo sloupců.