Odesílání úloh Sparku ve službě Azure Machine Learning
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Azure Machine Learning podporuje odesílání samostatných úloh strojového učení a vytváření kanálů strojového učení, které zahrnují několik kroků pracovního postupu strojového učení. Azure Machine Learning zpracovává samostatné vytváření úloh Sparku i vytváření opakovaně použitelných komponent Sparku, které můžou používat kanály Azure Machine Learning. V tomto článku se dozvíte, jak odesílat úlohy Sparku pomocí:
- uživatelské rozhraní studio Azure Machine Learning
- Rozhraní CLI služby Azure Machine Learning
- Azure Machine Learning SDK
Další informace o Apache Sparku v konceptech služby Azure Machine Learning najdete v tomto prostředku.
Požadavky
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
- Předplatné Azure; Pokud nemáte předplatné Azure, vytvořte si před zahájením bezplatný účet .
- Pracovní prostor služby Azure Machine Learning. Další informace najdete v tématu Vytvoření prostředků pracovního prostoru.
- Vytvořte výpočetní instanci služby Azure Machine Learning.
- Nainstalujte rozhraní příkazového řádku služby Azure Machine Learning.
- (Volitelné): Připojený fond Synapse Spark v pracovním prostoru Azure Machine Learning.
Poznámka:
- Další informace o přístupu k prostředkům při používání bezserverového výpočetního prostředí Spark ve službě Azure Machine Learning a připojeném fondu Synapse Sparku najdete v tématu Zajištění přístupu k prostředkům pro úlohy Sparku.
- Azure Machine Learning poskytuje fond sdílených kvót , ze kterého mají všichni uživatelé přístup k kvótě výpočetních prostředků, aby mohli provádět testování po omezenou dobu. Když použijete výpočetní prostředí Spark bez serveru, azure Machine Learning vám umožní získat přístup k této sdílené kvótě po krátkou dobu.
Připojení spravované identity přiřazené uživatelem pomocí rozhraní příkazového řádku v2
- Vytvořte soubor YAML, který definuje spravovanou identitu přiřazenou uživatelem, která by se měla připojit k pracovnímu prostoru:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Pomocí parametru
--filepřipojte spravovanou identitu přiřazenou uživatelem pomocí souboru YAML vaz ml workspace updatepříkazu:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Připojení spravované identity přiřazené uživatelem pomocí ARMClient
- Nainstalujte
ARMClientjednoduchý nástroj příkazového řádku, který vyvolá rozhraní API Azure Resource Manageru. - Vytvořte soubor JSON, který definuje spravovanou identitu přiřazenou uživatelem, která by se měla připojit k pracovnímu prostoru:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Pokud chcete k pracovnímu prostoru připojit spravovanou identitu přiřazenou uživatelem, spusťte na příkazovém řádku PowerShellu nebo na příkazovém řádku následující příkaz.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Poznámka:
- Pokud chcete zajistit úspěšné spuštění úlohy Sparku, přiřaďte role Přispěvatel a Přispěvatel dat objektů blob služby Storage v účtu úložiště Azure používaném pro vstup a výstup dat identitě, kterou úloha Spark používá.
- Přístup k veřejné síti by měl být povolený v pracovním prostoru Azure Synapse, aby se zajistilo úspěšné spuštění úlohy Sparku pomocí připojeného fondu Synapse Spark.
- V pracovním prostoru Azure Synapse, který má přidruženou spravovanou virtuální síť, pokud připojený fond Synapse Spark odkazuje na fond Synapse Spark, měli byste nakonfigurovat spravovaný privátní koncový bod pro účet úložiště, abyste zajistili přístup k datům.
- Bezserverové výpočetní prostředí Spark podporuje virtuální síť spravovanou službou Azure Machine Learning. Pokud je spravovaná síť zřízená pro výpočetní prostředí Spark bez serveru, měly by se zřídit také odpovídající privátní koncové body pro účet úložiště, aby se zajistil přístup k datům.
Odeslání samostatné úlohy Sparku
Po provedení nezbytných změn pro parametrizaci skriptu Pythonu můžete použít skript Pythonu vyvinutý s interaktivním uspořádáním dat k odeslání dávkové úlohy ke zpracování většího objemu dat. Datovou úlohu transformace dat můžete odeslat jako samostatnou úlohu Sparku.
Úloha Sparku vyžaduje skript Pythonu, který přebírá argumenty. Kód Pythonu, který byl původně vyvinutý z interaktivní transformace dat, můžete upravit tak, aby se tento skript vyvinul. Tady se zobrazí ukázkový skript Pythonu.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Poznámka:
Tento vzorový kód Pythonu používá pyspark.pandas. Tuto možnost podporuje pouze modul runtime Spark verze 3.2 nebo novější.
Tento skript přebírá dva argumenty, které předávají cestu vstupních dat a výstupní složky:
--titanic_data--wrangled_data
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Pokud chcete vytvořit úlohu, můžete definovat samostatnou úlohu Sparku jako soubor specifikace YAML, který můžete použít v az ml job create příkazu s parametrem --file . Definujte tyto vlastnosti v souboru YAML:
Vlastnosti YAML ve specifikaci úlohy Spark
type- nastaveno naspark.code– definuje umístění složky, která obsahuje zdrojový kód a skripty pro tuto úlohu.entry– definuje vstupní bod pro úlohu. Měla by zahrnovat jednu z těchto vlastností:file– definuje název skriptu Pythonu, který slouží jako vstupní bod pro úlohu.class_name- definuje název třídy, kterou servery jako vstupní bod pro úlohu.
py_files- definuje seznam.zip,.eggnebo.pysoubory, které mají být umístěny doPYTHONPATH, pro úspěšné provedení úlohy. Tato vlastnost je nepovinná.jars– definuje seznam.jarsouborů, které se mají zahrnout do ovladače Sparku, a exekutorCLASSPATHpro úspěšné spuštění úlohy. Tato vlastnost je nepovinná.files– definuje seznam souborů, které by se měly zkopírovat do pracovního adresáře každého exekutoru pro úspěšné provedení úlohy. Tato vlastnost je nepovinná.archives- definuje seznam archivů, které by se měly extrahovat do pracovního adresáře každého exekutoru pro úspěšné provedení úlohy. Tato vlastnost je nepovinná.conf– definuje tyto vlastnosti ovladače Sparku a exekutoru:spark.driver.cores: počet jader pro ovladač Spark.spark.driver.memory: přidělená paměť pro ovladač Spark v gigabajtech (GB).spark.executor.cores: počet jader pro exekutor Sparku.spark.executor.memory: přidělení paměti pro exekutor Sparku v gigabajtech (GB).spark.dynamicAllocation.enabled– zda by exekutory měly být dynamicky přiděleny jakoTruehodnota neboFalsehodnota.- Pokud je povolené dynamické přidělování exekutorů, definujte tyto vlastnosti:
spark.dynamicAllocation.minExecutors– minimální počet instancí exekutorů Sparku pro dynamické přidělování.spark.dynamicAllocation.maxExecutors– maximální počet instancí exekutorů Sparku pro dynamické přidělení.
- Pokud je dynamické přidělování exekutorů zakázané, definujte tuto vlastnost:
spark.executor.instances– počet instancí exekutoru Sparku.
environment– prostředí Azure Machine Learning pro spuštění úlohy.args– argumenty příkazového řádku, které by se měly předat skriptu Pythonu vstupního bodu úlohy. Projděte si soubor specifikace YAML uvedený tady, například.resources– tato vlastnost definuje prostředky, které mají být používány výpočetním prostředím Spark bez serveru služby Azure Machine Learning. Používá následující vlastnosti:instance_type– typ výpočetní instance, který se má použít pro fond Sparku. V současné době jsou podporovány následující typy instancí:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version– definuje verzi modulu runtime Spark. V současné době se podporují následující verze modulu runtime Spark:3.33.4Důležité
Azure Synapse Runtime pro Apache Spark: Oznámení
- Azure Synapse Runtime pro Apache Spark 3.3:
- Datum oznámení EOLA: 12. července 2024
- Datum ukončení podpory: 31. března 2025. Po tomto datu bude modul runtime zakázán.
- Pro trvalou podporu a optimální výkon doporučujeme migrovat na Apache Spark 3.4.
- Azure Synapse Runtime pro Apache Spark 3.3:
Toto je příklad souboru YAML:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute– tato vlastnost definuje název připojeného fondu Synapse Spark, jak je znázorněno v tomto příkladu:compute: mysparkpoolinputs– tato vlastnost definuje vstupy pro úlohu Spark. Vstupy pro úlohu Sparku můžou být literální hodnota nebo data uložená v souboru nebo složce.- Hodnota literálu může být číslo, logická hodnota nebo řetězec. Tady je několik příkladů:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Data uložená v souboru nebo složce by měla být definována pomocí těchto vlastností:
type- nastavte tuto vlastnost nauri_filenebouri_folderpro vstupní data obsažená v souboru nebo složce.path– identifikátor URI vstupních dat, napříkladazureml://,abfss://nebowasbs://.mode- nastavte tuto vlastnost nadirecthodnotu . Tato ukázka ukazuje definici vstupu úlohy, která může být označována takto$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Hodnota literálu může být číslo, logická hodnota nebo řetězec. Tady je několik příkladů:
outputs– tato vlastnost definuje výstupy úloh Sparku. Výstupy úlohy Sparku je možné zapsat do souboru nebo do umístění složky, které je definováno pomocí následujících tří vlastností:type- Tuto vlastnost můžete nastavit nauri_filehodnotu nebouri_folder, pro zápis výstupních dat do souboru nebo složky.path– tato vlastnost definuje identifikátor URI výstupního umístění, napříkladazureml://,abfss://nebowasbs://.mode- nastavte tuto vlastnost nadirecthodnotu . Tato ukázka ukazuje definici výstupu úlohy, na kterou můžete odkazovat takto${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity– tato volitelná vlastnost definuje identitu použitou k odeslání této úlohy. Může obsahovatuser_identityamanagedhodnoty. Pokud specifikace YAML nedefinuje identitu, úloha Sparku použije výchozí identitu.
Samostatná úloha Sparku
Tato ukázková specifikace YAML ukazuje samostatnou úlohu Sparku. Používá výpočetní prostředí Spark bez serveru Azure Machine Learning:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Poznámka:
Chcete-li použít připojený fond Synapse Spark, definujte compute vlastnost v ukázkovém souboru specifikace YAML zobrazeném resources dříve místo vlastnosti.
Soubory YAML zobrazené výše v az ml job create příkazu s parametrem --file můžete použít k vytvoření samostatné úlohy Sparku, jak je znázorněno na následujícím obrázku:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Výše uvedený příkaz můžete spustit z:
- terminál výpočetní instance služby Azure Machine Learning.
- terminál editoru Visual Studio Code připojený k výpočetní instanci služby Azure Machine Learning.
- váš místní počítač s nainstalovaným rozhraním příkazového řádku služby Azure Machine Learning.
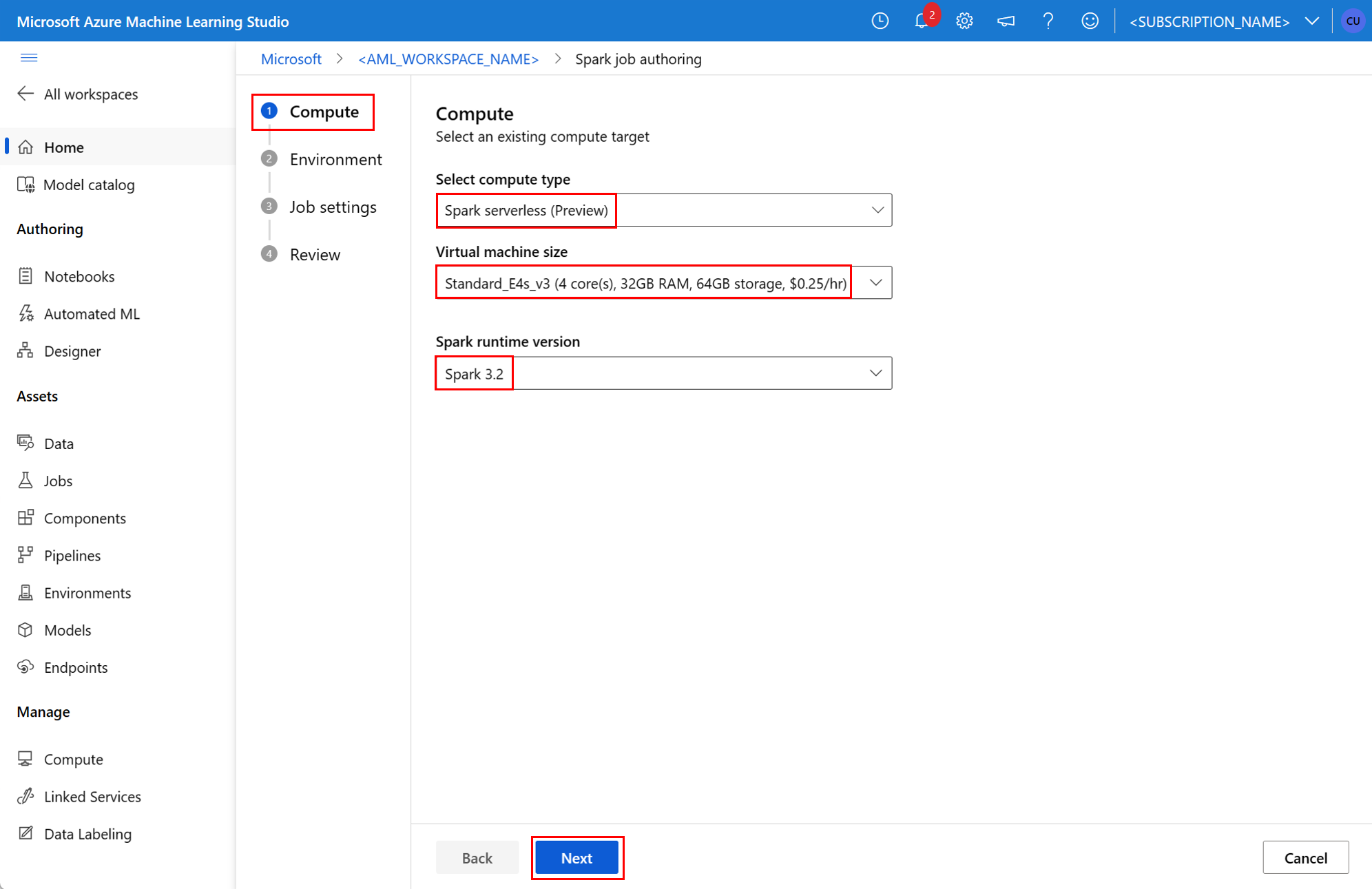
Komponenta Spark v úloze kanálu
Komponenta Spark nabízí flexibilitu používat stejnou komponentu v několika kanálech Azure Machine Learning jako krok kanálu.
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Syntaxe YAML pro komponentu Sparku se ve většině způsobů podobá syntaxi YAML pro specifikaci úlohy Sparku. Tyto vlastnosti jsou definovány odlišně ve specifikaci YAML komponenty Spark:
name– název komponenty Spark.version– verze komponenty Spark.display_name– název komponenty Spark, která se má zobrazit v uživatelském rozhraní a jinde.description– popis komponenty Spark.inputs– tato vlastnost se podobáinputsvlastnosti popsané v syntaxi YAML pro specifikaci úlohy Sparku s tím rozdílem, že tuto vlastnost nedefinujepath. Tento fragment kódu ukazuje příklad vlastnosti komponentyinputsSpark:inputs: titanic_data: type: uri_file mode: directoutputs– tato vlastnost se podobáoutputsvlastnosti popsané v syntaxi YAML pro specifikaci úlohy Sparku s tím rozdílem, že tuto vlastnost nedefinujepath. Tento fragment kódu ukazuje příklad vlastnosti komponentyoutputsSpark:outputs: wrangled_data: type: uri_folder mode: direct
Poznámka:
Komponenta identitycompute Sparku nedefinuje vlastnost nebo resources vlastnosti. Soubor specifikace YAML kanálu definuje tyto vlastnosti.
Tento soubor specifikace YAML poskytuje příklad komponenty Spark:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Komponentu Spark definovanou ve výše uvedeném souboru specifikace YAML můžete použít v úloze kanálu Azure Machine Learning. Další informace o syntaxi YAML definující úlohu kanálu najdete v prostředku schématu YAML. Tento příklad ukazuje soubor specifikace YAML pro úlohu kanálu s komponentou Spark a výpočetním prostředím Spark bez serveru služby Azure Machine Learning:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Poznámka:
Chcete-li použít připojený fond Synapse Spark, definujte compute vlastnost v ukázkovém souboru specifikace YAML uvedené výše místo resources vlastnosti.
K vytvoření úlohy kanálu můžete použít soubor specifikace YAML uvedený výše v az ml job create příkazu pomocí parametru --file , jak je znázorněno na následujícím obrázku:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Výše uvedený příkaz můžete spustit z:
- terminál výpočetní instance služby Azure Machine Learning.
- terminál editoru Visual Studio Code připojený k výpočetní instanci služby Azure Machine Learning.
- váš místní počítač s nainstalovaným rozhraním příkazového řádku služby Azure Machine Learning.
Řešení potíží s úlohami Sparku
Pokud chcete řešit potíže s úlohou Spark, můžete získat přístup k protokolům vygenerovaným pro danou úlohu v studio Azure Machine Learning. Zobrazení protokolů pro úlohu Sparku:
- Přechod na Úlohy z levého panelu v uživatelském rozhraní studio Azure Machine Learning
- Výběr karty Všechny úlohy
- Vyberte hodnotu zobrazovaného názvu pro úlohu.
- Na stránce podrobností úlohy vyberte kartu Výstup a protokoly .
- V Průzkumníku souborů rozbalte složku protokolů a pak rozbalte složku azureml .
- Přístup k protokolům úloh Sparku ve složkách správce ovladačů a knihoven
Poznámka:
Pokud chcete řešit potíže s úlohami Sparku vytvořenými během interaktivní transformace dat v relaci poznámkového bloku, vyberte Podrobnosti úlohy v pravém horním rohu uživatelského rozhraní poznámkového bloku. Úlohy Sparku z interaktivní relace poznámkového bloku se vytvoří v rámci spuštění poznámkového bloku s názvem experimentu.