Rychlý start: Interaktivní transformace dat pomocí Apache Sparku ve službě Azure Machine Learning
Integrace služby Azure Machine Learning s azure Synapse Analytics pro zpracování interaktivních dat poznámkového bloku Azure Machine Learning poskytuje snadný přístup k rozhraní Apache Spark. Tento přístup umožňuje uspořádání interaktivních dat v poznámkovém bloku Azure Machine Learning.
V této příručce pro rychlý start se dozvíte, jak provádět interaktivní transformace dat pomocí výpočetních prostředků Spark bezserverové služby Azure Machine Learning, účtu úložiště Azure Data Lake Storage (ADLS) Gen2 a předávání identity uživatele.
Požadavky
- Předplatné Azure; Pokud nemáte předplatné Azure, vytvořte si před zahájením bezplatný účet .
- Pracovní prostor služby Azure Machine Learning. Navštivte stránku Vytvoření prostředků pracovního prostoru.
- Účet úložiště Azure Data Lake Storage (ADLS) Gen2. Navštivte web Vytvoření účtu úložiště Azure Data Lake Storage (ADLS) Gen2.
Ukládání přihlašovacích údajů účtu úložiště Azure jako tajných kódů ve službě Azure Key Vault
Pokud chcete přihlašovací údaje účtu úložiště Azure uložit jako tajné kódy ve službě Azure Key Vault, s uživatelským rozhraním webu Azure Portal:
Na webu Azure Portal přejděte do služby Azure Key Vault.
Výběr tajných kódů z levého panelu
Výběr a vygenerování/importu
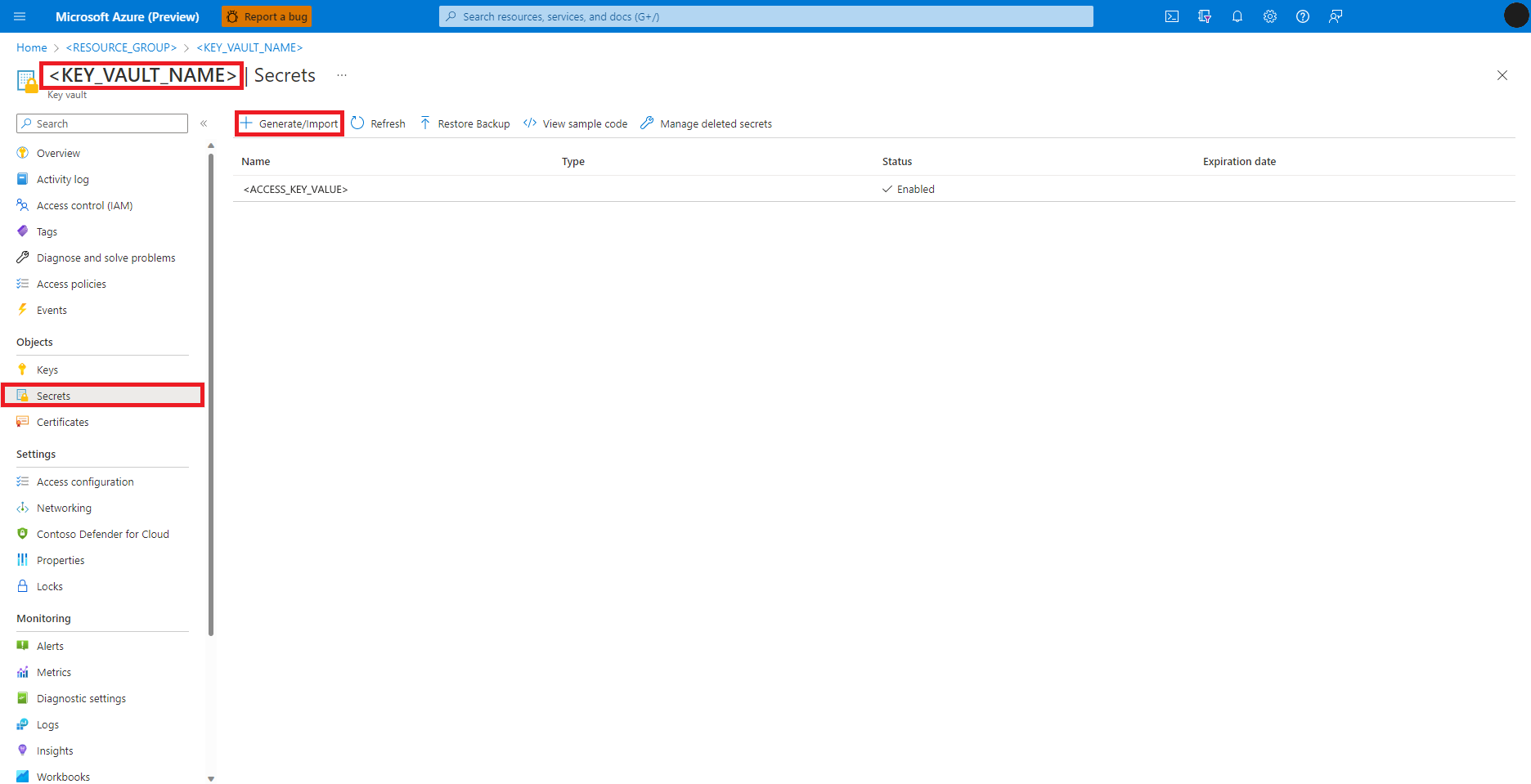
Na obrazovce Vytvořit tajný kód zadejte název tajného kódu, který chcete vytvořit.
Na webu Azure Portal přejděte na účet služby Azure Blob Storage, jak je znázorněno na tomto obrázku:
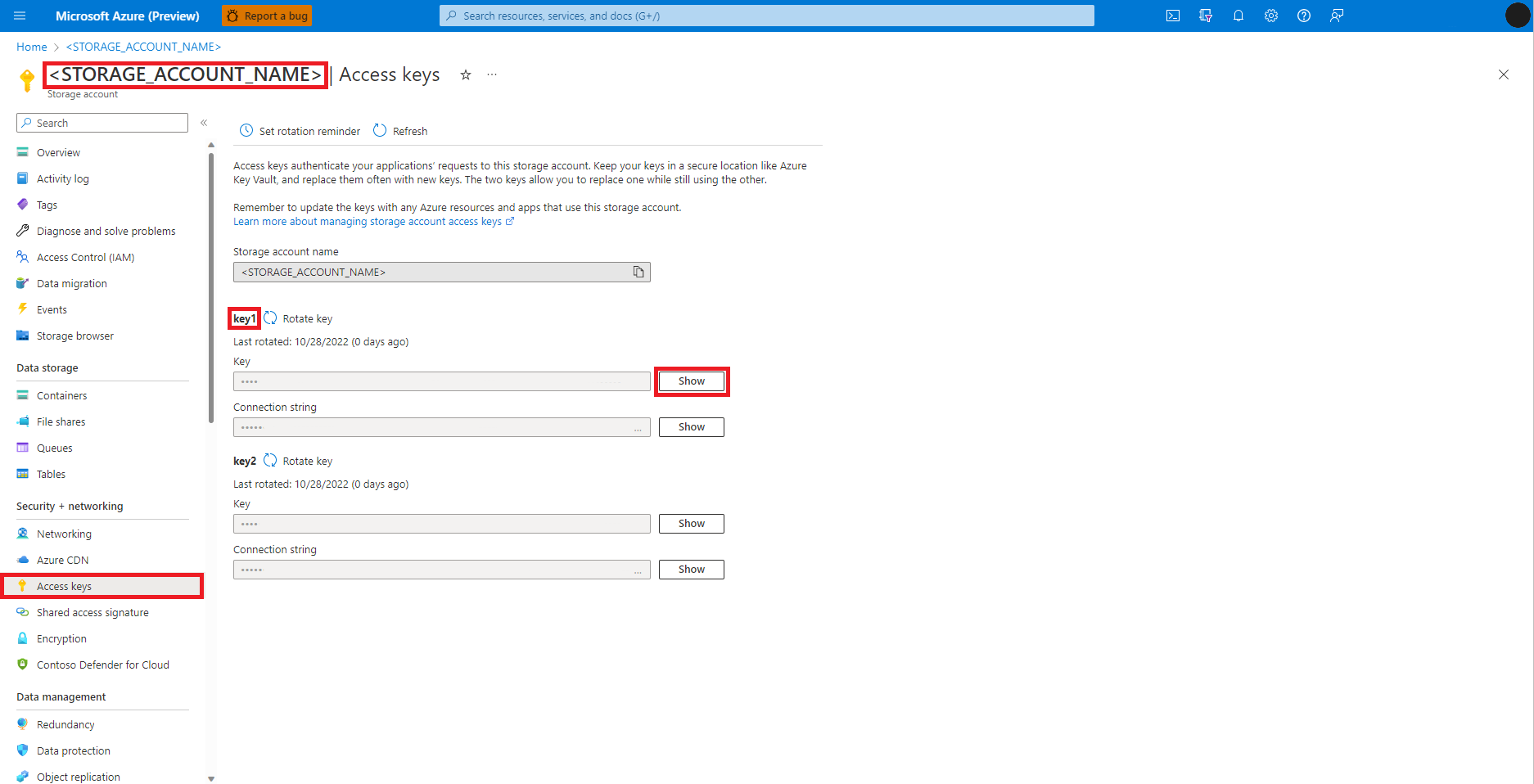
Výběr přístupových klíčů na levém panelu účtu služby Azure Blob Storage
Vyberte Zobrazit vedle klíče 1 a pak zkopírujte do schránky a získejte přístupový klíč účtu úložiště.
Poznámka:
Vyberte vhodné možnosti pro kopírování.
- Tokeny sdíleného přístupového podpisu (SAS) kontejneru služby Azure Blob Storage
- Přihlašovací údaje instančního objektu účtu úložiště Azure Data Lake Storage (ADLS) Gen2
- ID tenanta
- ID klienta a
- Tajný kód
v příslušných uživatelských rozhraních při vytváření tajných kódů služby Azure Key Vault pro ně
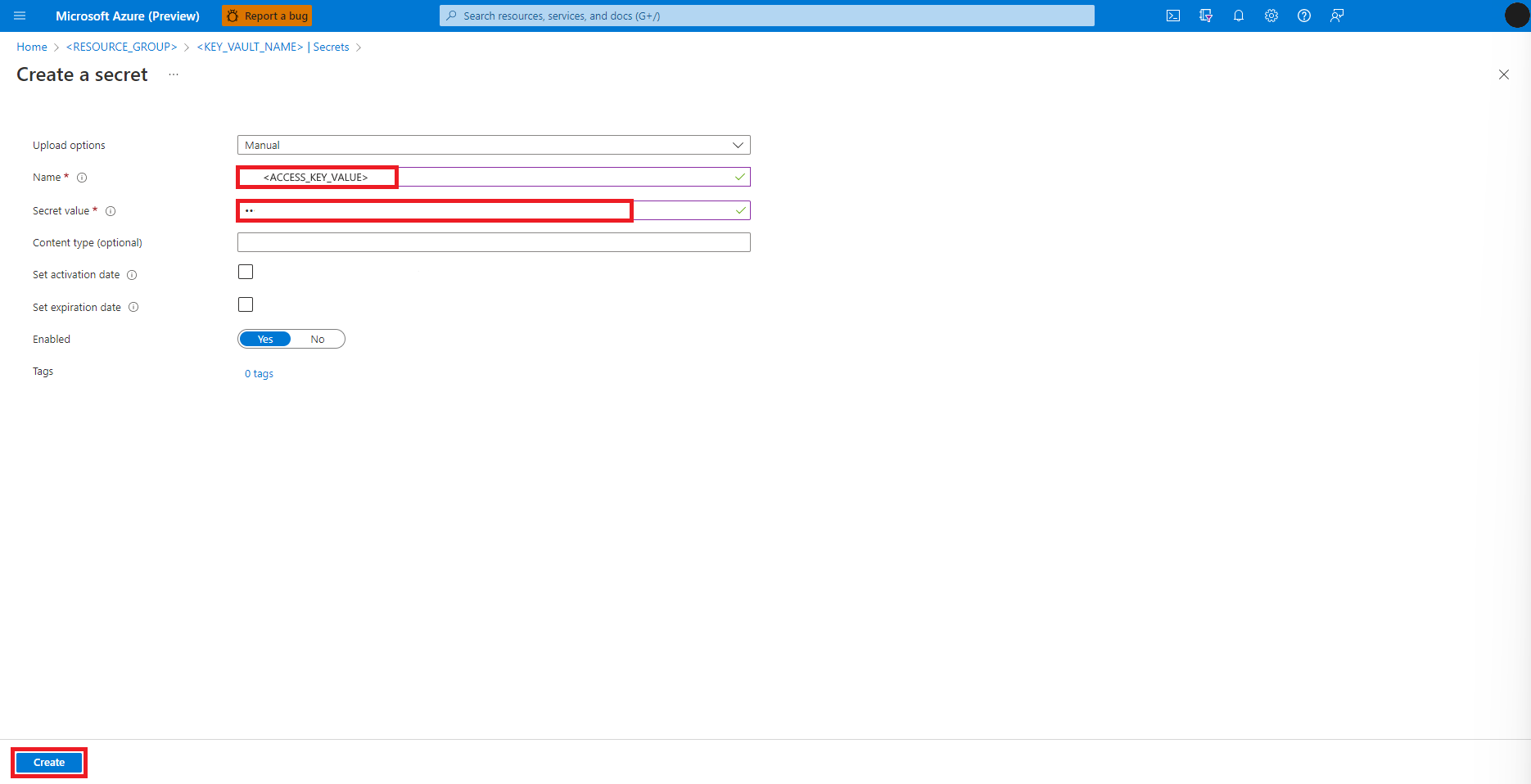
Přechod zpět na obrazovku Vytvořit tajný kód
Do textového pole Hodnota tajného kódu zadejte přihlašovací údaje přístupového klíče pro účet úložiště Azure, který se zkopíroval do schránky v předchozím kroku.
Vyberte příkaz Vytvořit.
Tip
Azure CLI a klientská knihovna tajných kódů služby Azure Key Vault pro Python můžou také vytvářet tajné kódy služby Azure Key Vault.
Přidání přiřazení rolí v účtech úložiště Azure
Před zahájením interaktivní transformace dat musíme zajistit přístupnost vstupních a výstupních datových cest. Za prvé, pro
identita uživatele relace poznámkových bloků přihlášeného uživatele
nebo
instanční objekt
přiřaďte role Čtenář a Čtenář dat objektů blob služby Storage k identitě uživatele přihlášeného uživatele. V některých scénářích ale můžeme chtít uspořádaná data zapsat zpět do účtu úložiště Azure. Role Čtenář a Čtenář dat objektů blob služby Storage poskytují přístup jen pro čtení k identitě uživatele nebo instančnímu objektu. Pokud chcete povolit přístup pro čtení a zápis, přiřaďte k identitě uživatele nebo instančnímu objektu role Přispěvatel dat Přispěvatel a Přispěvatel dat v objektu blob služby Storage. Přiřazení odpovídajících rolí identitě uživatele:
Otevření webu Microsoft Azure Portal
Hledání a výběr služby Účty úložiště

Na stránce Účty úložiště vyberte ze seznamu účet úložiště Azure Data Lake Storage (ADLS) Gen2. Otevře se stránka zobrazující přehled účtu úložiště.

Na levém panelu vyberte Řízení přístupu (IAM).
Vyberte Přidat přiřazení role.
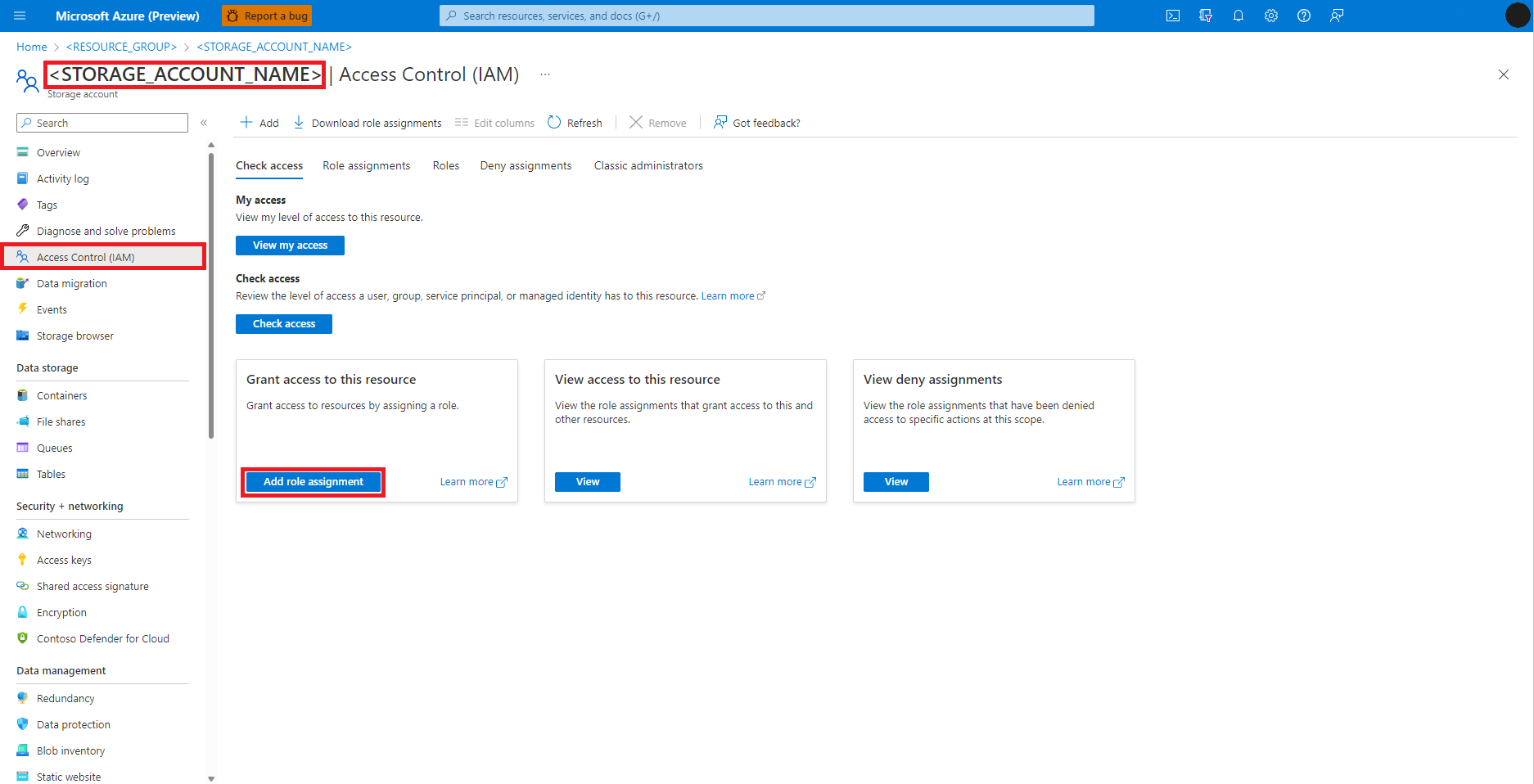
Vyhledání a výběr role Přispěvatel dat objektů blob služby Storage
Vyberte Další.

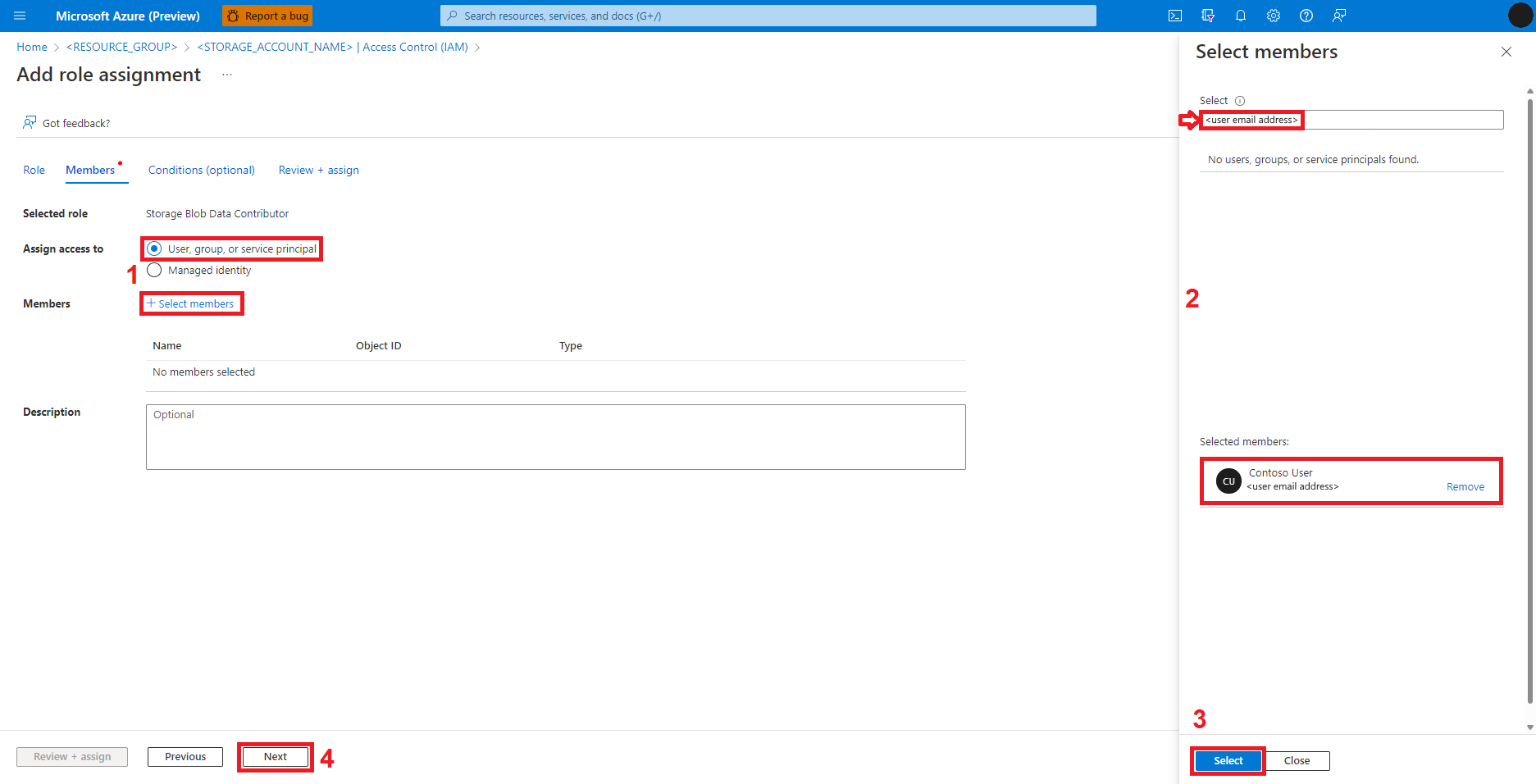
Výběr uživatele, skupiny nebo instančního objektu
Vybrat a vybrat členy
Vyhledejte identitu uživatele níže : Vyberte
Ze seznamu vyberte identitu uživatele, aby se zobrazovala v části Vybrané členy.
Vyberte příslušnou identitu uživatele.
Vyberte Další.
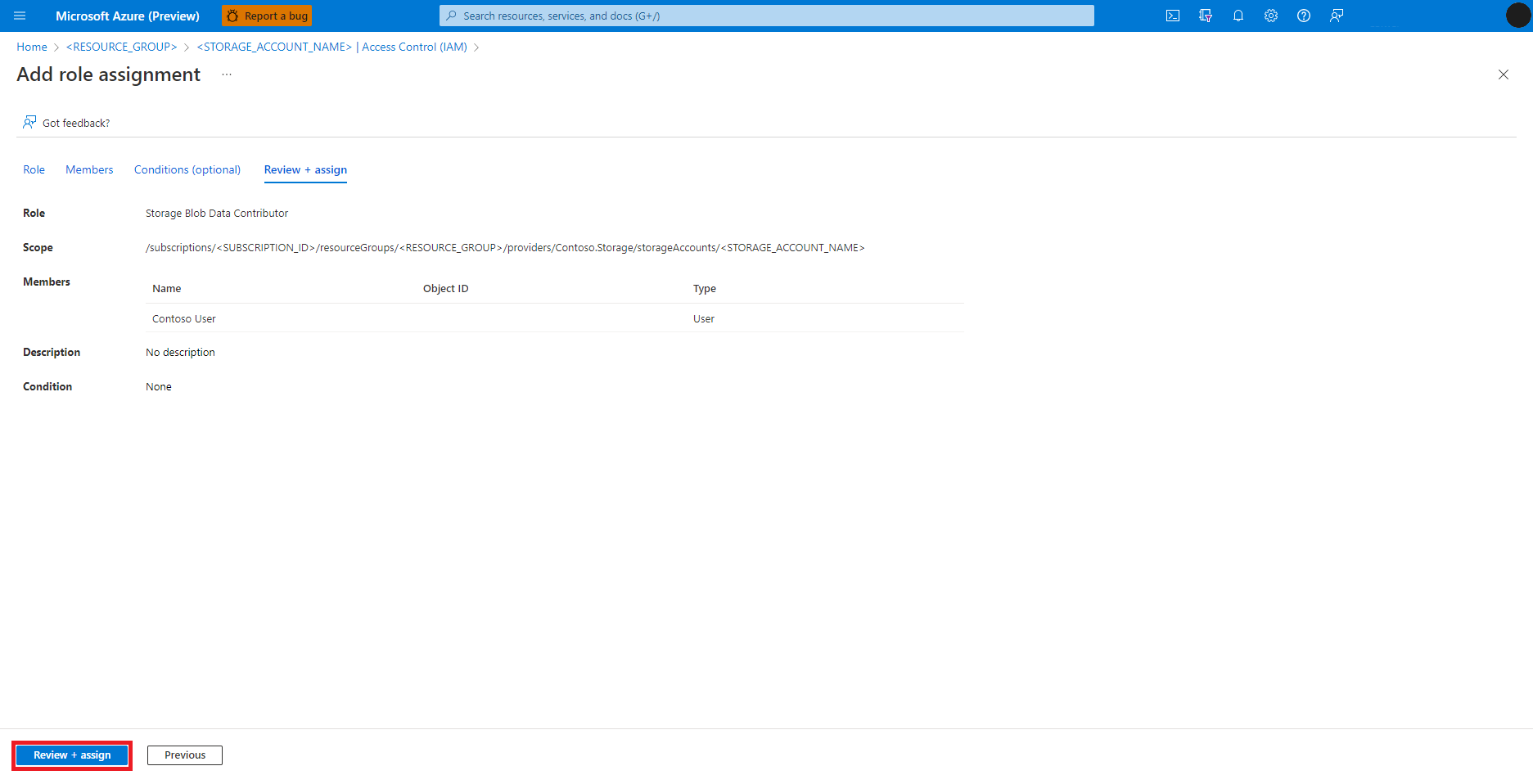
Vyberte Zkontrolovat a přiřadit.
Opakování kroků 2 až 13 pro přiřazení role přispěvatele






Jakmile má identita uživatele přiřazené příslušné role, měla by být data v účtu úložiště Azure přístupná.
Poznámka:
Pokud připojený fond Synapse Spark odkazuje na fond Synapse Spark v pracovním prostoru Azure Synapse, který má přidruženou spravovanou virtuální síť, měli byste nakonfigurovat spravovaný privátní koncový bod na účet úložiště, abyste zajistili přístup k datům.
Zajištění přístupu k prostředkům pro úlohy Sparku
Pro přístup k datům a dalším prostředkům můžou úlohy Sparku používat spravovanou identitu nebo předávací identitu uživatele. Následující tabulka shrnuje různé mechanismy přístupu k prostředkům, zatímco používáte výpočetní prostředky Spark bez serveru Azure Machine Learning a připojený fond Synapse Spark.
| Fond Sparku | Podporované identity | Výchozí identita |
|---|---|---|
| Výpočetní prostředí Spark bez serveru | Identita uživatele, spravovaná identita přiřazená uživatelem připojená k pracovnímu prostoru | Identita uživatele |
| Připojený fond Synapse Spark | Identita uživatele, spravovaná identita přiřazená uživatelem připojená k připojenému fondu Synapse Spark, spravovaná identita přiřazená systémem připojeného fondu Synapse Spark | Spravovaná identita přiřazená systémem připojeného fondu Synapse Spark |
Pokud kód rozhraní příkazového řádku nebo sady SDK definuje možnost použití spravované identity, výpočetní prostředí Spark bez serveru služby Azure Machine Learning spoléhá na spravovanou identitu přiřazenou uživatelem připojenou k pracovnímu prostoru. Spravovanou identitu přiřazenou uživatelem můžete připojit k existujícímu pracovnímu prostoru Azure Machine Learning pomocí Azure Machine Learning CLI v2 nebo pomocí ARMClient.
Další kroky
- Apache Spark ve službě Azure Machine Learning
- Připojení a správa fondu Synapse Spark ve službě Azure Machine Learning
- Interaktivní transformace dat pomocí Apache Sparku ve službě Azure Machine Learning
- Odesílání úloh Sparku ve službě Azure Machine Learning
- Ukázky kódu pro úlohy Sparku pomocí azure Machine Learning CLI
- Ukázky kódu pro úlohy Sparku pomocí sady Azure Machine Learning Python SDK