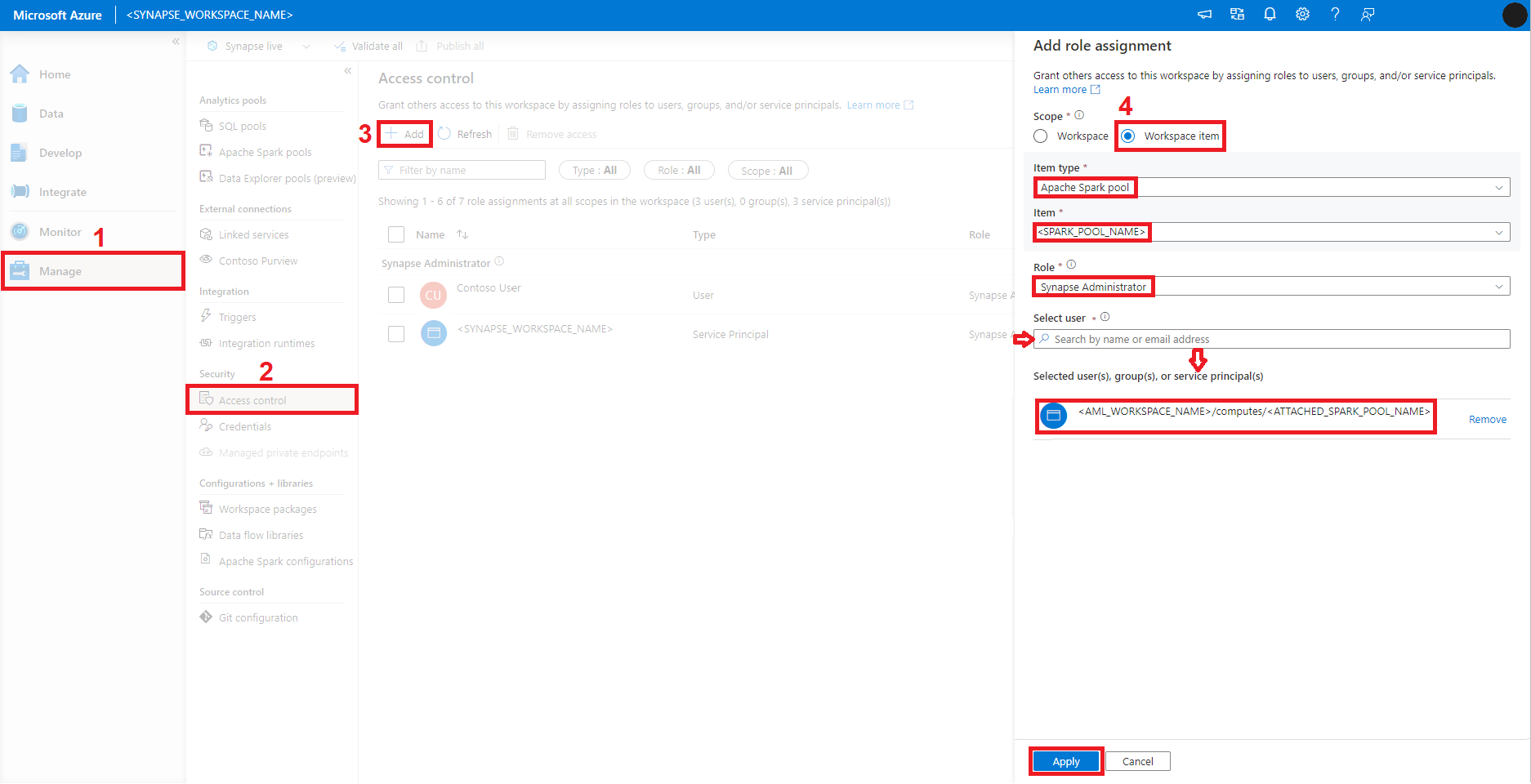
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)
Pomocí rozhraní příkazového řádku Azure Machine Learning MŮŽEME použít intuitivní syntaxi a příkazy YAML z rozhraní příkazového řádku k připojení a správě fondu Synapse Spark.
Pokud chcete definovat připojený fond Synapse Spark pomocí syntaxe YAML, měl by soubor YAML pokrývat tyto vlastnosti:
name – název připojeného fondu Synapse Spark.
type – nastavte tuto vlastnost na synapsesparkhodnotu .
resource_id – Tato vlastnost by měla obsahovat hodnotu ID prostředku fondu Synapse Spark vytvořeného v pracovním prostoru Azure Synapse Analytics. ID prostředku Azure zahrnuje
ID předplatného Azure
název skupiny prostředků,
Název pracovního prostoru Azure Synapse Analytics a
název fondu Synapse Spark.
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity – tato vlastnost definuje typ identity, který se přiřadí připojenému fondu Synapse Spark. Může mít jednu z těchto hodnot:
identity Pro typ user_assignedbyste také měli zadat seznam user_assigned_identities hodnot. Každá identita přiřazená uživatelem by měla být deklarována jako prvek seznamu pomocí resource_id hodnoty identity přiřazené uživatelem. První identita přiřazená uživatelem v seznamu se ve výchozím nastavení používá k odeslání úlohy.
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity:
type: user_assigned
user_assigned_identities:
- resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>
Výše uvedené soubory YAML lze použít v az ml compute attach příkazu jako --file parametr. Fond Synapse Spark je možné připojit k pracovnímu prostoru Azure Machine Learning v zadané skupině prostředků předplatného pomocí az ml compute attach příkazu, jak je znázorněno tady:
az ml compute attach --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Tato ukázka ukazuje očekávaný výstup výše uvedeného příkazu:
Class SynapseSparkCompute: This is an experimental class, and may change at any time. Please visit https://aka.ms/azuremlexperimental for more information.
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
Pokud připojený fond Synapse Spark se zadaným v souboru specifikace YAML již v pracovním prostoru existuje, pak az ml compute attach spuštění příkazu aktualizuje existující fond informacemi uvedenými v souboru specifikace YAML. Můžete aktualizovat
- typ identity
- identity přiřazené uživatelem
- značky
hodnoty prostřednictvím souboru specifikace YAML.
Pokud chcete zobrazit podrobnosti o připojeném fondu Synapse Spark, spusťte az ml compute show příkaz. Předejte název připojeného fondu Synapse Spark s parametrem --name , jak je znázorněno níže:
az ml compute show --name <ATTACHED_SPARK_POOL_NAME> --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Tato ukázka ukazuje očekávaný výstup výše uvedeného příkazu:
<ATTACHED_SPARK_POOL_NAME>
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
Pokud chcete zobrazit seznam všech výpočetních prostředků, včetně připojených fondů Synapse Spark v pracovním prostoru, použijte az ml compute list tento příkaz. Pomocí parametru name předejte název pracovního prostoru, jak je znázorněno na obrázku:
az ml compute list --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Tato ukázka ukazuje očekávaný výstup výše uvedeného příkazu:
[
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-09 21:28:54.871251+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"identity": {
"principal_id": "<PRINCIPAL_ID>",
"tenant_id": "<TENANT_ID>",
"type": "system_assigned"
},
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
},
...
]
PLATÍ PRO: Python SDK azure-ai-ml v2 (aktuální)
Sada Azure Machine Learning Python SDK poskytuje praktické funkce pro připojení a správu fondu Synapse Spark pomocí kódu Pythonu v poznámkových blocích Azure Machine Learning.
Pokud chcete připojit Synapse Compute pomocí sady Python SDK, nejprve vytvořte instanci třídy azure.ai.ml.MLClient. To poskytuje praktické funkce pro interakci se službami Azure Machine Learning. Následující ukázka kódu se používá azure.identity.DefaultAzureCredential pro připojení k pracovnímu prostoru ve skupině prostředků zadaného předplatného Azure. V následující ukázce kódu definujte SynapseSparkCompute tyto parametry:
name – uživatelem definovaný název nového připojeného fondu Synapse Spark.resource_id – ID prostředku fondu Synapse Sparku vytvořeného dříve v pracovním prostoru Azure Synapse Analytics
Volání funkce azure.ai.ml.MLClient.begin_create_or_update() připojí definovaný fond Synapse Spark k pracovnímu prostoru Azure Machine Learning.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_comp = SynapseSparkCompute(name=synapse_name, resource_id=synapse_resource)
ml_client.begin_create_or_update(synapse_comp)
Pokud chcete připojit fond Synapse Spark, který používá identitu přiřazenou systémem, předejte IdentityConfiguration s typem nastaveným na SystemAssigned, jako identity parametr SynapseSparkCompute třídy. Tento fragment kódu připojí fond Synapse Spark, který používá identitu přiřazenou systémem:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute, IdentityConfiguration
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(type="SystemAssigned")
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
Fond Synapse Spark může také používat identitu přiřazenou uživatelem. Pro identitu přiřazenou uživatelem můžete předat definici spravované identity pomocí třídy IdentityConfiguration jako identity parametr SynapseSparkCompute třídy. Pro definici spravované identity, která se používá tímto způsobem, nastavte type na hodnotu UserAssigned. Kromě toho předejte user_assigned_identities parametr. user_assigned_identities Parametr je seznam objektů UserAssignedIdentity třídy. Identita resource_id přiřazená uživatelem naplní každý UserAssignedIdentity objekt třídy. Tento fragment kódu připojí fond Synapse Spark, který používá identitu přiřazenou uživatelem:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
SynapseSparkCompute,
IdentityConfiguration,
UserAssignedIdentity,
)
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(
type="UserAssigned",
user_assigned_identities=[
UserAssignedIdentity(
resource_id="/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>"
)
],
)
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
Poznámka:
Funkce azure.ai.ml.MLClient.begin_create_or_update() připojí nový fond Synapse Spark, pokud fond se zadaným názvem v pracovním prostoru ještě neexistuje. Pokud je však fond Synapse Spark se zadaným názvem již připojený k pracovnímu prostoru, volání azure.ai.ml.MLClient.begin_create_or_update() funkce aktualizuje existující připojený fond novou identitou nebo identitami.