Kurz: Vytvoření kanálů strojového učení v produkčním prostředí
PLATÍ PRO:  Python SDK azure-ai-ml v2 (aktuální)
Python SDK azure-ai-ml v2 (aktuální)
Poznámka:
Kurz, který k sestavení kanálu používá sadu SDK v1, najdete v kurzu : Sestavení kanálu Služby Azure Machine Learning pro klasifikaci obrázků.
Základem kanálu strojového učení je rozdělení kompletní úlohy strojového učení na vícekrokový pracovní postup. Každý krok je spravovatelná komponenta, kterou je možné vyvíjet, optimalizovat, konfigurovat a automatizovat jednotlivě. Kroky jsou propojeny prostřednictvím dobře definovaných rozhraní. Služba kanálu Azure Machine Learning automaticky orchestruje všechny závislosti mezi kroky kanálu. Výhody používání kanálu jsou standardizované postupy MLOps, škálovatelná týmová spolupráce, efektivita trénování a snížení nákladů. Další informace o výhodách kanálů najdete v tématu Co jsou kanály Azure Machine Learning.
V tomto kurzu použijete Azure Machine Learning k vytvoření projektu strojového učení připraveného pro produkční prostředí pomocí sady Azure Machine Learning Python SDK v2.
To znamená, že budete moct využít sadu Azure Machine Learning Python SDK k:
- Získání popisovače pracovního prostoru Služby Azure Machine Learning
- Vytvoření datových prostředků služby Azure Machine Learning
- Vytváření opakovaně použitelných komponent služby Azure Machine Learning
- Vytváření, ověřování a spouštění kanálů Služby Azure Machine Learning
V tomto kurzu vytvoříte kanál Služby Azure Machine Learning pro trénování modelu pro výchozí predikci kreditu. Kanál zpracovává dva kroky:
- Příprava dat
- Trénování a registrace natrénovaného modelu
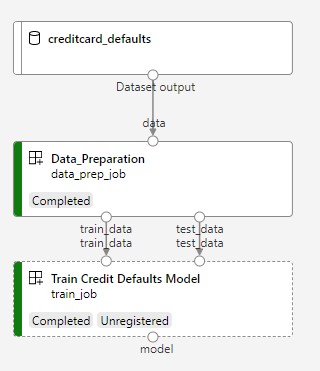
Další obrázek ukazuje jednoduchý kanál, jak ho uvidíte v Azure Studiu po odeslání.
Dva kroky jsou první příprava dat a druhé trénování.
Toto video ukazuje, jak začít studio Azure Machine Learning, abyste mohli postupovat podle kroků v tomto kurzu. Video ukazuje, jak vytvořit poznámkový blok, vytvořit výpočetní instanci a naklonovat poznámkový blok. Kroky jsou popsané také v následujících částech.
Požadavky
-
Pokud chcete používat Azure Machine Learning, potřebujete pracovní prostor. Pokud ho nemáte, dokončete vytváření prostředků, které potřebujete, abyste mohli začít vytvářet pracovní prostor a získat další informace o jeho používání.
Důležité
Pokud je váš pracovní prostor Azure Machine Learning nakonfigurovaný se spravovanou virtuální sítí, možná budete muset přidat odchozí pravidla, která umožní přístup k veřejným úložištím balíčků Pythonu. Další informace najdete v tématu Scénář: Přístup k veřejným balíčkům strojového učení.
-
Přihlaste se do studia a vyberte pracovní prostor, pokud ještě není otevřený.
Dokončete kurz Nahrání, přístup k datům a prozkoumání dat a vytvořte datový prostředek, který potřebujete v tomto kurzu. Ujistěte se, že spustíte veškerý kód pro vytvoření počátečního datového assetu. Prozkoumejte data a upravte je, pokud chcete, ale budete potřebovat jenom počáteční data v tomto kurzu.
-
Otevřete nebo vytvořte poznámkový blok v pracovním prostoru:
- Pokud chcete zkopírovat a vložit kód do buněk, vytvořte nový poznámkový blok.
- Nebo otevřete kurzy/get-started-notebooks/pipeline.ipynb v části Ukázky studia. Potom vyberte Clone (Klonovat ) a přidejte poznámkový blok do složky Soubory. Ukázkové poznámkové bloky najdete v tématu Výuka z ukázkových poznámkových bloků.
Nastavení jádra a otevření v editoru Visual Studio Code (VS Code)
Na horním panelu nad otevřeným poznámkovým blokem vytvořte výpočetní instanci, pokud ji ještě nemáte.

Pokud je výpočetní instance zastavená, vyberte Spustit výpočetní prostředky a počkejte, až bude spuštěný.

Počkejte na spuštění výpočetní instance. Pak se ujistěte, že jádro, které se nachází v pravém horním rohu, je
Python 3.10 - SDK v2. Pokud ne, vyberte toto jádro pomocí rozevíracího seznamu.
Pokud toto jádro nevidíte, ověřte, že je vaše výpočetní instance spuštěná. Pokud ano, vyberte tlačítko Aktualizovat v pravém horním rohu poznámkového bloku.
Pokud se zobrazí banner s informací, že potřebujete být ověřeni, vyberte Ověřit.
Poznámkový blok můžete spustit tady nebo ho otevřít ve VS Code pro úplné integrované vývojové prostředí (IDE) s využitím prostředků Azure Machine Learning. Vyberte Otevřít v editoru VS Code a pak vyberte možnost Web nebo Desktop. Při spuštění tímto způsobem se VS Code připojí k vaší výpočetní instanci, jádru a systému souborů pracovního prostoru.





Důležité
Zbytek tohoto kurzu obsahuje buňky poznámkového bloku kurzu. Pokud jste ho naklonovali, zkopírujte je a vložte do nového poznámkového bloku nebo ho teď přepněte do poznámkového bloku.
Nastavení prostředků kanálu
Rozhraní Azure Machine Learning je možné použít z rozhraní příkazového řádku, sady Python SDK nebo studia. V tomto příkladu vytvoříte kanál pomocí sady Azure Machine Learning Python SDK v2.
Před vytvořením kanálu potřebujete následující prostředky:
- Datový asset pro trénování
- Softwarové prostředí pro spuštění kanálu
- Výpočetní prostředek, do kterého se úloha spouští
Vytvoření popisovače do pracovního prostoru
Než se pustíme do kódu, potřebujete způsob, jak odkazovat na váš pracovní prostor. ml_client Vytvoříte pro popisovač pracovního prostoru. Pak použijete ml_client ke správě prostředků a úloh.
Do další buňky zadejte ID předplatného, název skupiny prostředků a název pracovního prostoru. Tyto hodnoty najdete takto:
- V pravém horním studio Azure Machine Learning panelu nástrojů vyberte název pracovního prostoru.
- Zkopírujte hodnotu pro pracovní prostor, skupinu prostředků a ID předplatného do kódu.
- Budete muset zkopírovat jednu hodnotu, zavřít oblast a vložit a pak se vrátit k další hodnotě.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Poznámka:
Vytvoření MLClient se nepřipojí k pracovnímu prostoru. Inicializace klienta je opožděná, bude čekat poprvé, až bude muset provést volání (k tomu dojde v další buňce kódu).
Ověřte připojení voláním ml_client. Vzhledem k tomu, že toto je poprvé, co voláte do pracovního prostoru, můžete být požádáni o ověření.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Přístup k registrovanému datovému assetu
Začněte tím, že získáte data, která jste dříve zaregistrovali v kurzu: Nahrání, přístup k datům a prozkoumání dat ve službě Azure Machine Learning.
- Azure Machine Learning používá
Dataobjekt k registraci opakovaně použitelné definice dat a využívání dat v rámci kanálu.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Vytvoření prostředí úlohy pro kroky kanálu
Zatím jste vytvořili vývojové prostředí na výpočetní instanci, ve vývojovém počítači. Pro každý krok kanálu potřebujete také prostředí. Každý krok může mít vlastní prostředí nebo můžete použít některá běžná prostředí pro několik kroků.
V tomto příkladu vytvoříte prostředí Conda pro vaše úlohy pomocí souboru conda yaml. Nejprve vytvořte adresář pro uložení souboru.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Teď vytvořte soubor v adresáři závislostí.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
Specifikace obsahuje některé obvyklé balíčky, které používáte v kanálu (numpy, pip), společně s některými konkrétními balíčky služby Azure Machine Learning (azureml-mlflow).
Balíčky Azure Machine Learning nejsou povinné ke spouštění úloh Azure Machine Learning. Přidáním těchto balíčků ale můžete pracovat se službou Azure Machine Learning pro metriky protokolování a registraci modelů, a to vše v rámci úlohy Azure Machine Learning. Použijete je v trénovacím skriptu později v tomto kurzu.
Pomocí souboru yaml vytvořte a zaregistrujte toto vlastní prostředí ve vašem pracovním prostoru:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Sestavení trénovacího kanálu
Teď, když máte všechny prostředky potřebné ke spuštění kanálu, je čas vytvořit samotný kanál.
Kanály Azure Machine Learning jsou opakovaně použitelné pracovní postupy ML, které se obvykle skládají z několika komponent. Typická životnost komponenty je:
- Napište specifikaci yaml komponenty nebo ji vytvořte programově pomocí
ComponentMethod. - Volitelně můžete zaregistrovat komponentu s názvem a verzí v pracovním prostoru, aby byla opakovaně použitelná a sdílená.
- Načtěte komponentu z kódu kanálu.
- Implementujte kanál pomocí vstupů, výstupů a parametrů komponenty.
- Odešlete kanál.
Existují dva způsoby, jak vytvořit komponentu, programový kód a definici yaml. Následující dvě části vás provedou vytvořením komponenty oběma způsoby. Můžete buď vytvořit dvě komponenty, které vyzkouší obě možnosti, nebo vybrat upřednostňovanou metodu.
Poznámka:
V tomto kurzu pro zjednodušení používáme stejný výpočetní výkon pro všechny komponenty. Pro každou komponentu ale můžete nastavit různé výpočty, například přidáním řádku jako train_step.compute = "cpu-cluster". Pokud chcete zobrazit příklad vytvoření kanálu s různými výpočetními prostředky pro každou komponentu, přečtěte si část Základní úloha kanálu v kurzu kanálu cifar-10.
Vytvoření komponenty 1: příprava dat (pomocí programové definice)
Začněme vytvořením první komponenty. Tato komponenta zpracovává předběžné zpracování dat. Úloha předběžného zpracování se provádí v souboru data_prep.py Pythonu.
Nejprve vytvořte zdrojovou složku pro komponentu data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Tento skript provádí jednoduchou úlohu rozdělení dat na trénovací a testovací datové sady. Azure Machine Learning připojí datové sady jako složky k výpočtům, proto jsme vytvořili pomocnou select_first_file funkci pro přístup k datovému souboru uvnitř připojené vstupní složky.
MLFlow se používá k protokolování parametrů a metrik během spuštění kanálu.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Teď, když máte skript, který může provést požadovanou úlohu, vytvořte z něj komponentu Azure Machine Learning.
Použijte obecné účely CommandComponent , které můžou spouštět akce příkazového řádku. Tato akce příkazového řádku může přímo volat systémové příkazy nebo spustit skript. Vstupy a výstupy se zadají na příkazovém řádku prostřednictvím zápisu ${{ ... }} .
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Volitelně můžete zaregistrovat komponentu v pracovním prostoru pro budoucí použití.
# Now we register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create (register) the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Vytvoření komponenty 2: trénování (pomocí definice yaml)
Druhá komponenta, kterou vytvoříte, využívá trénování a testování dat, trénování stromového modelu a vrácení výstupního modelu. Pomocí možností protokolování služby Azure Machine Learning můžete zaznamenávat a vizualizovat průběh učení.
Použili CommandComponent jste třídu k vytvoření první komponenty. Tentokrát použijete definici yaml k definování druhé komponenty. Každá metoda má své vlastní výhody. Definice yaml může být ve skutečnosti vrácena se změnami v kódu a poskytovala by čitelné sledování historie. Použití programové metody CommandComponent může být snazší s integrovanou dokumentací třídy a dokončováním kódu.
Vytvořte adresář pro tuto komponentu:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Vytvořte trénovací skript v adresáři:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Jak vidíte v tomto trénovacím skriptu, po vytrénování modelu se soubor modelu uloží a zaregistruje do pracovního prostoru. Teď můžete použít zaregistrovaný model při odvozování koncových bodů.
Pro prostředí tohoto kroku použijete jedno z předdefinovaných (kurátorovaných) prostředí Azure Machine Learning. Značka azuremlříká systému, aby hledal název v kurátorovaných prostředích.
Nejprve vytvořte soubor yaml popisující komponentu:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Teď vytvořte a zaregistrujte komponentu. Když ho zaregistrujete, můžete ho znovu použít v jiných kanálech. Zaregistrovanou komponentu může používat také kdokoli jiný s přístupem k vašemu pracovnímu prostoru.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now we register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create (register) the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Vytvoření kanálu z komponent
Teď, když jsou obě komponenty definované a registrované, můžete začít s implementací kanálu.
Tady jako vstupní proměnné použijete vstupní data, poměr rozdělení a registrovaný název modelu. Potom volejte komponenty a připojte je pomocí jejich vstupů/výstupních identifikátorů. K výstupům každého kroku je možné přistupovat prostřednictvím .outputs vlastnosti.
Funkce Pythonu load_component() vrácené prací fungují jako všechny běžné funkce Pythonu, které používáme v rámci kanálu k volání jednotlivých kroků.
K kódování kanálu použijete konkrétní @dsl.pipeline dekorátor, který identifikuje kanály Azure Machine Learning. V dekorátoru můžeme zadat popis kanálu a výchozí prostředky, jako jsou výpočetní prostředky a úložiště. Stejně jako funkce Pythonu můžou kanály obsahovat vstupy. Pak můžete vytvořit více instancí jednoho kanálu s různými vstupy.
Tady jsme jako vstupní proměnné použili vstupní data, poměr rozdělení a registrovaný název modelu. Potom tyto komponenty zavoláme a propojíme je pomocí jejich vstupů/výstupních identifikátorů. K výstupům každého kroku je možné přistupovat prostřednictvím .outputs vlastnosti.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Teď pomocí definice kanálu vytvořte instanci kanálu s datovou sadou, rozdělením rychlosti výběru a názvem, který jste vybrali pro svůj model.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Odeslání úlohy
Teď je čas odeslat úlohu, která se má spustit ve službě Azure Machine Learning. Tentokrát použijete create_or_update na ml_client.jobs.
Tady také předáte název experimentu. Experiment je kontejner pro všechny iterace, které provádí v určitém projektu. Všechny úlohy odeslané pod stejným názvem experimentu se zobrazí vedle sebe v studio Azure Machine Learning.
Po dokončení kanál zaregistruje v pracovním prostoru model v důsledku trénování.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Průběh kanálu můžete sledovat pomocí odkazu vygenerovaného v předchozí buňce. Při prvním výběru tohoto odkazu se může zobrazit, že kanál stále běží. Po dokončení můžete prozkoumat výsledky jednotlivých komponent.
Poklikejte na komponentu Train Credit Defaults Model ( Trénování výchozích hodnot kreditu).
O trénování se budete chtít podívat na dva důležité výsledky:
Prohlédněte si protokoly:
- Vyberte kartu Výstupy a protokoly.
- Otevření složek do
user_logs>std_log.txttéto části ukazuje spuštění skriptu stdout.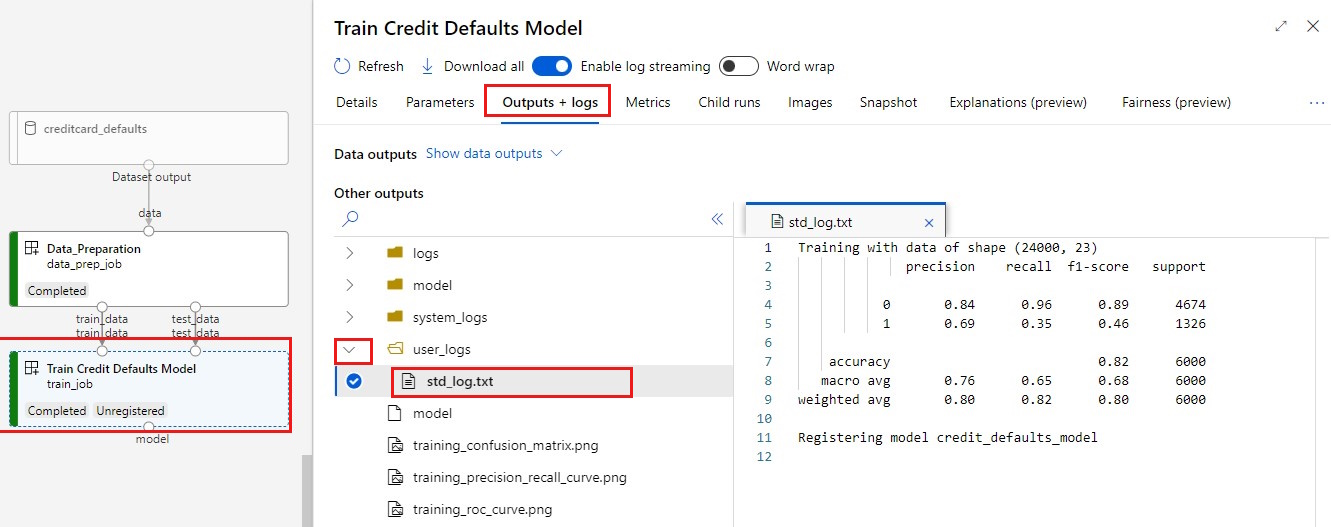
Zobrazení metrik: Vyberte kartu Metriky . Tato část zobrazuje různé protokolované metriky. V tomto příkladu. mlflow
autologging, automaticky protokoloval trénovací metriky.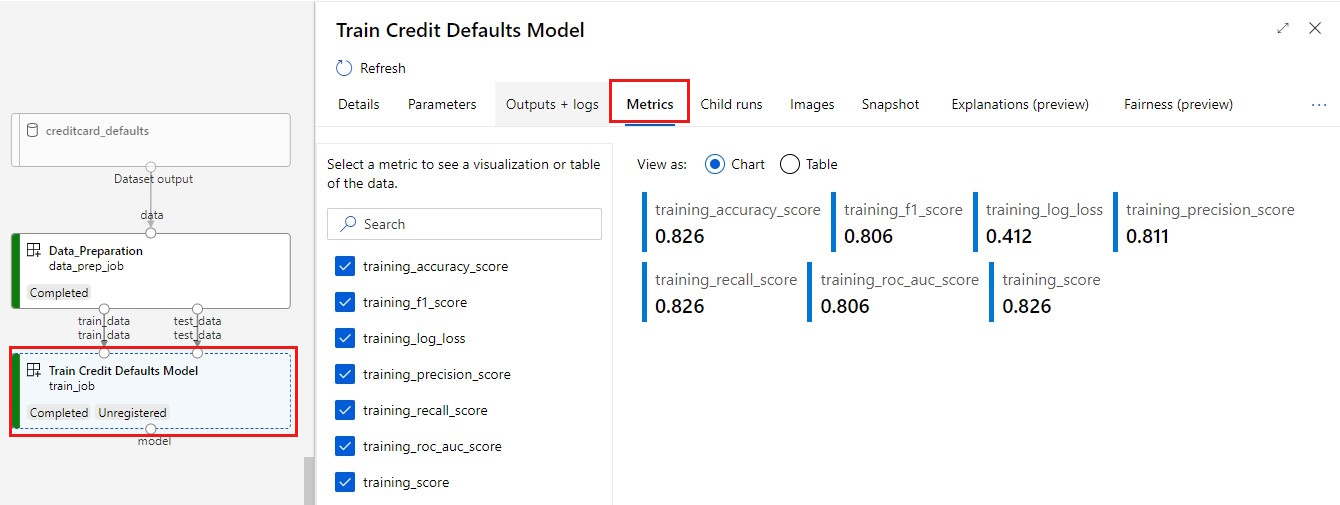


Nasazení modelu jako online koncového bodu
Informace o nasazení modelu do online koncového bodu najdete v tématu Nasazení modelu jako kurzu online koncového bodu.
Vyčištění prostředků
Pokud chcete pokračovat v dalších kurzech, přejděte k dalším krokům.
Zastavení výpočetní instance
Pokud ji teď nebudete používat, zastavte výpočetní instanci:
- V sadě Studio v levé navigační oblasti vyberte Compute.
- Na horních kartách vyberte Výpočetní instance.
- V seznamu vyberte výpočetní instanci.
- Na horním panelu nástrojů vyberte Zastavit.
Odstranění všech prostředků
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a články s postupy pro Azure Machine Learning.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Na webu Azure Portal do vyhledávacího pole zadejte skupiny prostředků a vyberte je z výsledků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Na stránce Přehled vyberte Odstranit skupinu prostředků.
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Další kroky
Informace o plánování úloh kanálu strojového učení