使用 Azure Data Lake Tools for Visual Studio 解決 Azure Data Lake Analytics 中的數據扭曲問題
重要
Azure Data Lake Analytics 於 2024 年 2 月 29 日淘汰。 使用此公告深入瞭解。
針對數據分析,您的組織可以使用 Azure Synapse Analytics 或 Microsoft Fabric。
什麼是資料扭曲?
簡單來說,資料扭曲就是被過度代表的值。 假設您已指派 50 個稅務檢查員來稽核稅務稅金,每個美國州都有一個檢查員。 Wyoming 檢查程式,因為人口很小,所以只需要執行一些動作。 但加州的審查員則因為該州人口眾多,因此一直都很忙碌。

在我們的案例中,所有稅務審查員所需處理的資料並非平均分配的,這表示某些審查員必須完成的工作會多過他人。 在您自己的作業中,您經常會遇到如這裡所說的稅務審查員範例的情況。 更專業的說法是,會有一個人拿到比他的同事多很多的資料,在這種情況下,那個人的工作量會多過其他人,因此最終會拖累整個作業的進度。 更糟糕的是,該項作業可能會失敗,因為舉例來說,那個人可能受到 5 小時執行階段和 6 GB 記憶體的限制。
解決資料扭曲問題
Azure Data Lake Tools for Visual Studio 和 Visual Studio Code 有助於偵測您的作業是否有數據扭曲問題。
如果有此問題,您可以試試本節的解決方案來加以解決。
解決方案 1:改善資料表分割
選項 1:事先篩選扭曲的索引鍵值
如果不會影響商業規則,您可以事先篩選較高的頻率值。 例如,如果數據行 GUID 中有許多 000-000-000,您可能不想匯總該值。 在彙總之前,您可以撰寫 “WHERE GUID != “000-000-000”” 來篩選高頻率值。
選項 2:選擇不同的分割區或散發索引鍵
在前面的範例中,如果您只想要檢查國家/區域的稅務稽核工作量,則可以選取 ID 號碼作為索引鍵,以改善資料散發。 有時候,選擇不同的分割區或散發索引鍵可以更平均地散發資料,但您必須確保此舉不會影響商務邏輯。 比方說,為了計算各州的總稅額,您可以指定州別做為資料分割索引鍵。 如果您仍然遇到這個問題,請嘗試使用選項 3。
選項 3:新增更多分割區或散發索引鍵
您可以不只使用州別做為資料分割索引鍵,而使用多個資料分割索引鍵。 例如,請考慮將 郵遞區區編碼 新增為另一個數據分割索引鍵,以減少數據分割大小,並更平均地散發數據。
選項 4:使用循環配置資源散發
如果您找不到適合分割區和散發的索引鍵,您可以嘗試使用迴圈配置資源散發。 循環配置資源散發會平等對待所有資料列,並將資料列隨機放到對應的貯體。 資料會平均地散發,但將會失去位置資訊,這項缺點也會減少部分作業的作業效能。 此外,如果您要對扭曲的索引鍵進行匯總,數據扭曲問題將會持續發生。 若要深入瞭解迴圈配置資源散發,請參閱 CREATE TABLE (U-SQL) :使用架構建立數據表中的 U-SQL 數據表散發一節。
解決方案 2︰改善查詢計劃
選項 1︰使用 CREATE STATISTICS 陳述式
U-SQL 針對資料表提供 CREATE STATISTICS 陳述式。 此語句提供查詢優化器的詳細資訊,例如,儲存在數據表中的值分佈) (數據特性。 對於大部分查詢而言,查詢最佳化工具已為高品質的查詢計劃產生所需的統計資料。 有時候,您可能需要使用 CREATE STATISTICS 建立更多統計數據或修改查詢設計,以改善查詢效能。 如需詳細資訊,請參閱 CREATE STATISTICS (U-SQL) 頁面。
程式碼範例:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
注意
統計資料的資訊不會自動更新。 如果您沒有重新建立統計資料就更新資料表中的資料,查詢效能可能會下滑。
選項 2:使用 SKEWFACTOR
如果您想要加總各州的稅額,您必須使用 GROUP BY 狀態這種無法避免資料扭曲問題的方法。 不過,您可以在查詢中提供資料提示以識別索引鍵中的資料扭曲,讓最佳化工具能夠為您準備好執行計畫。
通常,您可以將 參數設定為 0.5 和 1,0.5 表示不多扭曲,一個表示重扭曲。 提示會影響目前陳述式及所有下游陳述式的執行計畫最佳化,因此請務必在執行可能的扭曲索引鍵彙總之前新增提示。
SKEWFACTOR (columns) = x
提供提示,指出指定的數據行具有 0 (沒有扭曲) 到 1 (繁重扭曲) 的扭曲因數 x。
程式碼範例:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
選項 3:使用 ROWCOUNT
除了 SKEWFACTOR,若為特定的扭曲索引鍵聯結案例,如果您知道其他的聯結資料列集很小,您可以在 U-SQL 陳述式的 JOIN 前面新增 ROWCOUNT 提示,以將此情形告知最佳化工具。 如此一來,最佳化工具就可以選擇廣播聯結策略來協助改善效能。 請注意,ROWCOUNT 無法解決數據扭曲問題,但可以提供一些額外的協助。
OPTION(ROWCOUNT = n)
提供估計的整數資料列計數,以識別 JOIN 之前的小型資料列集。
程式碼範例:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
解決方案 3:改善使用者定義的歸納器和結合器
有時候,您可以撰寫使用者定義的運算子來處理複雜的程序邏輯,而撰寫良好的歸納器和結合器可能會在某些情況下降低資料扭曲問題。
選項 1:在情況允許時使用遞迴歸納器
根據預設,使用者定義的歸納器會以非遞歸模式執行,這表示索引鍵的縮減工作會散發到單一頂點。 但如果您的資料已扭曲,大型的資料集可能會在單一頂點中處理,並執行相當久的時間。
若要改善效能,您可以在程式碼中新增屬性,將歸納器定義為以遞迴模式執行。 然後,大量的資料集就可以散發到多個頂點並平行執行,以加快作業速度。
若要將非遞歸歸歸歸器變更為遞歸,您必須確定您的演算法具有關聯性。 例如,總和是關聯的,而中位數則不是。 此外,您必須確保歸納器的輸入和輸出會保持相同的結構描述。
遞迴歸納器的屬性:
[SqlUserDefinedReducer(IsRecursive = true)]
程式碼範例:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
選項 2:在情況允許時使用資料列層級結合器模式
結合器模式與針對特定扭曲索引鍵加入案例的 ROWCOUNT 提示類似,會嘗試將大型扭曲索引鍵值集散發到多個頂點,讓工作可以並行執行。 結合器模式無法解決數據扭曲問題,但它可為大型扭曲索引鍵值集提供一些額外的協助。
根據預設,合併器模式為 Full,這表示無法分隔左數據列集和右數據列集。 將模式設為 Left/Right/Inner 則可進行資料列層級聯結。 系統會將對應的資料列集分開,並將其分散到多個平行執行的頂點。 不過,在設定結合器模式之前,請務必確保對應的資料列集可以分開。
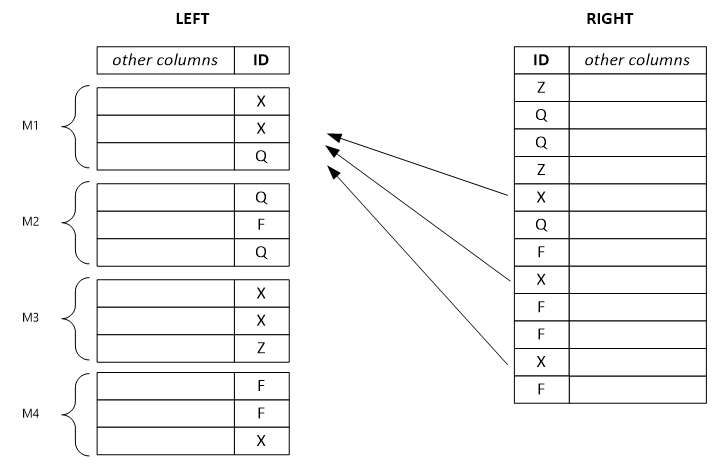
接下來的範例顯示分開的左資料列集。 每個輸出資料列相依於左邊的單一輸入資料列,並可能相依於所有具有相同索引鍵值的右邊資料列。 如果您將結合器模式設定為 Left,系統會將大型的左資料列集分開成較小的資料列集,並將它們指派給多個頂點。
注意
如果您設定了錯誤的結合器模式,其組合會較無效率,且結果可能會出錯。
結合器模式的屬性︰
SqlUserDefinedCombiner(Mode=CombinerMode.Full):每個輸出資料列都可能相依於左側和右側具有相同索引鍵值的所有輸入資料列。
SqlUserDefinedCombiner(Mode=CombinerMode.Left):每個輸出資料列相依於左邊的單一輸入資料列 (並可能相依於所有具有相同索引鍵值的右邊資料列)。
qlUserDefinedCombiner(Mode=CombinerMode.Right):每個輸出資料列相依於右邊的單一輸入資料列 (並可能相依於所有具有相同索引鍵值的左邊資料列)。
SqlUserDefinedCombiner(Mode=CombinerMode.Inner):每個輸出資料列相依於左邊和右邊具有相同值的單一輸入資料列。
程式碼範例:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}