什麼是 Azure Synapse Analytics?
Azure Synapse 是一項企業分析服務,可讓您更快速地取得資料倉儲和巨量資料系統間的深入解析。 Azure Synapse 匯集了企業資料倉儲中所用的 SQL 技術、巨量資料所用的 Spark 技術、用於記錄和時間序列分析的資料總管、用於資料整合和 ETL/ELT 的管線,以及與其他 Azure 服務 (例如 Power BI、CosmosDB 和 AzureML) 的深度整合之精華。
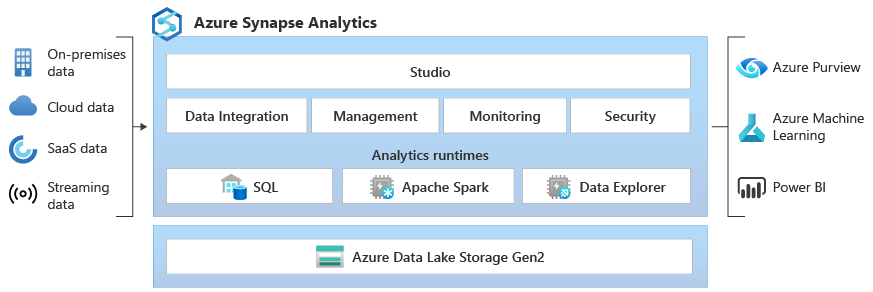
領先業界的 SQL
Synapse SQL 是適用於 T-SQL 的分散式查詢系統,可實現資料倉儲和資料虛擬化案例,並擴充了 T-SQL 以因應串流和機器學習案例。
- Synapse SQL 提供無伺服器和專用的資源模型。 針對可預測的效能和成本,請建立專用 SQL 集區來為 SQL 資料表中所儲存的資料保留處理效能。 針對非計畫或暴增的工作負載,請使用永遠可用的無伺服器 SQL 端點。
- 請使用內建的串流功能,將雲端資料來源中的資料放入 SQL 資料表
- 若要整合 AI 與 SQL,請使用機器學習模型,以利用 T-SQL PREDICT 函式來為資料評分
業界標準的 Apache Spark
適用於 Synapse Spark 的 Apache Spark 會深入且完美地整合 Apache Spark (這是最受歡迎的開放原始碼巨量資料引擎,可用於資料準備、資料工程、ETL 和機器學習)。
- Apache Spark 3.1 具有搭配 SparkML 演算法和 Azure 機器學習整合的 ML 模型,且內建 Linux Foundation Delta Lake 支援。
- 簡化的資源模型,讓您不必擔心如何管理叢集。
- 快速的 Spark 啟動和主動進行自動調整。
- Spark 的內建 .NET 支援,可讓您在 Spark 應用程式中重複使用您的 C# 專業知識和現有的 .NET 程式碼。
使用您的資料湖
Azure Synapse 移除了同時使用 SQL 和 Spark 的傳統技術障礙。 您可以根據需求和專長,順暢地混搭這兩項功能。
- Spark 或 SQL 會順暢地取用 Data Lake 中檔案上定義的數據表。
- SQL 和 Spark 可直接探索及分析儲存在資料湖中的 Parquet、CSV、TSV 與 JSON 檔案。
- 在 SQL 與 Spark 資料庫之間進行快速、可擴充的資料載入
內建資料整合
Azure Synapse 包含與 Azure Data Factory 相同的資料整合引擎和體驗,可讓您建立豐富的大規模 ETL 管線,而不需離開 Azure Synapse Analytics。
- 從 90 個以上的資料來源內嵌資料
- 搭配資料流程活動的無程式碼 ETL
- 協調筆記本、Spark 作業、預存程序、SQL 指令碼等等
資料總管 (預覽)
Azure Synapse 資料總管提供客戶互動式查詢體驗,揭開系統產生的記錄和遙測資料的深入解析。 為補充現有的 SQL 和 Apache Spark 分析執行階段引擎,資料總管分析執行階段使用強大的索引技術,自動編製索引任意文字與系統產生記錄常見的半結構化資料,將高效記錄分析最佳化。
使用資料總管作為資料平台,建立近即時的記錄分析和 IoT 分析解決方案,即可:
- 跨內部部署、雲端和協力廠商資料來源,合併記錄和事件資料,並使其相互關聯。
- 加速 AI Ops 旅程 (模式辨識、異常偵測、預測等)
- 取代基礎結構的記錄搜尋解決方案,節省成本並提高產能。
- 建置 IoT 資料的 IoT 分析解決方案。
- 建置分析 SaaS 解決方案,為您的內、外部客戶提供服務。
整合式體驗
Synapse Studio 提供一種方式,讓企業可在單一使用者體驗下建置解決方案、維護及保護一切
- 執行主要工作:擷取、探索、準備、協調、視覺化
- 跨 SQL、Spark 和資料總管監視資源、使用量和使用者
- 使用角色型存取控制簡化對分析資源的存取
- 撰寫 SQL、Spark 或 KQL 程式碼,並與企業 CI/CD 程序整合
與 Synapse 社群交流
- Microsoft Q&A:詢問技術問題。
- Stack Overflow:詢問開發問題。