使用醫療保健資料解決方案中的非結構化臨床筆記擴充 (預覽版)
[本文章是發行前版本文件,隨時可能變更。]
注意
目前正在更新此內容。
非結構化臨床記錄豐富 (預覽版) 使用 Azure AI 語言的 Text Analytics for health 服務,從非結構化臨床記錄中提取關鍵的快速醫療互通性資源 (FHIR) 實體。 它從這些臨床記錄中生成結構化資料。 接著,您可以分析這些結構化資料,以獲得洞察、進行預測並衡量品質,目標是提升患者的健康成果。
若要了解此功能的詳細資訊並了解如何部署和設定它,請參閱:
非結構化臨床記錄增強功能 (預覽版) 直接依賴於醫療資料基礎功能。 請先確保成功設定並執行醫療資料基礎管線。
先決條件
- 在 Microsoft Fabric 中部署醫療資料解決方案
- 在部署醫療保健資料基礎中安裝基礎筆記本和管線。
- 按照設定 Azure 語言服務中的說明來設定 Azure 語言服務。
- 部署和設定非結構化臨床筆記擴充 (預覽版)
- 部署和設定 OMOP 轉換。 此步驟是選擇性的。
NLP 擷取服務
healthcare#_msft_ta4h_silver_ingestion 筆記本在醫療保健資料解決方案庫中執行 NLPIngestionService 模組,並叫用 Text Analytics for health 服務。 此服務從 FHIR 資源 DocumentReference.Content 中提取非結構化臨床筆記,以建立平展輸出。 若要瞭解詳細資訊,請參閱查看筆記本設定。
資料儲存在銀層
在自然語言處理 (NLP) API 分析之後,結構化和扁平化的輸出存儲在 healthcare#_msft_silver 湖倉內的以下本機表中:
- nlpentity:包含從非結構化臨床筆記中提取的扁平實體。 每一列都是在執行文本分析後,從非結構化文本中擷取出的單一術語。
- nlprelationship:提取的實體之間的關係。
- nlpfhir:以 JSON 字串形式包含 FHIR 輸出捆綁包。
為了追蹤最後更新的時間戳,NLPIngestionService 在三個銀湖倉資料表中都使用 parent_meta_lastUpdated 欄位。 此追蹤確保來源文件 DocumentReference 作為上層資源被首先儲存,以維持參照完整性。 此過程有助於防止資料不一致和孤立資源的產生。
重要
目前,Text Analytics for health 傳回的詞彙來自 UMLS Metathesaurus 詞彙文件中的詞彙表。 有關這些詞彙表的指導,請參閱 從 UMLS 匯入資料。
對於預覽版,我們使用 SNOMED-CT (醫學系統化命名法 - 臨床術語)、LOINC (邏輯觀察標識符、名稱和代碼) 和 RxNorm 術語,這些術語包含在基於觀察健康資料指導的 OMOP 範例資料集中科學與資訊學 (OHDSI)。
OMOP 轉換
中的 Microsoft Fabric 醫療保健資料解決方案還為觀察性醫療結果合作夥伴關係 (OMOP) 轉換提供了另一種功能。 執行此功能時,從銀湖倉到金湖倉的基礎 OMOP 轉換也會轉換非結構化臨床筆記分析的結構化和扁平化輸出。 該轉換從銀湖倉中的 nlpentity 資料表讀取資料,並將輸出對應到 OMOP 湖倉中的 NOTE_NLP 資料表。
如需詳細資訊,請參閱 OMOP 轉換概觀。
下面是結構化 NLP 輸出的架構,以及相應的 NOTE_NLP 列對應到 OMOP 通用資料模型:
| 展平的文件參照 | 描述 | Note_NLP 對應 | 範例資料 |
|---|---|---|---|
| id | 唯一的實體識別碼。 parent_id、offset 和 length 的複合鍵。 |
note_nlp_id |
1380 |
| parent_id | 從中提取術語的扁平化 documentreferencecontent 參考內容文本的外部索引鍵。 | note_id |
625 |
| 文字 | 顯示在文件中的實體文字。 | lexical_variant |
無已知過敏 |
| 位移 | 輸入 documentreferencecontent 文字中提取的術語的字元偏移量。 | offset |
294 |
| data_source_entity_id | 指定來源目錄中的實體識別碼。 | note_nlp_concept_id 和 note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | 文件引用內容 documentreferencecontent 日期。 | nlp_date_time 和 nlp_date |
2023-05-17T00:00:00.0000000 |
| 機型 | NLP 系統的名稱和版本 (Text Analytics for health NLP 系統的名稱和版本)。 | nlp_system |
MSFT TA4H |

Text Analytics for Health 的服務限制
- 每個文件的最大字元數限制為 125,000。
- 整個請求中包含的文件的最大大小限制為 1 MB。
- 每個請求的最大文件數量限制為:
- 25 用於基於 Web 的 API。
- 容器的 1000。
啟用記錄
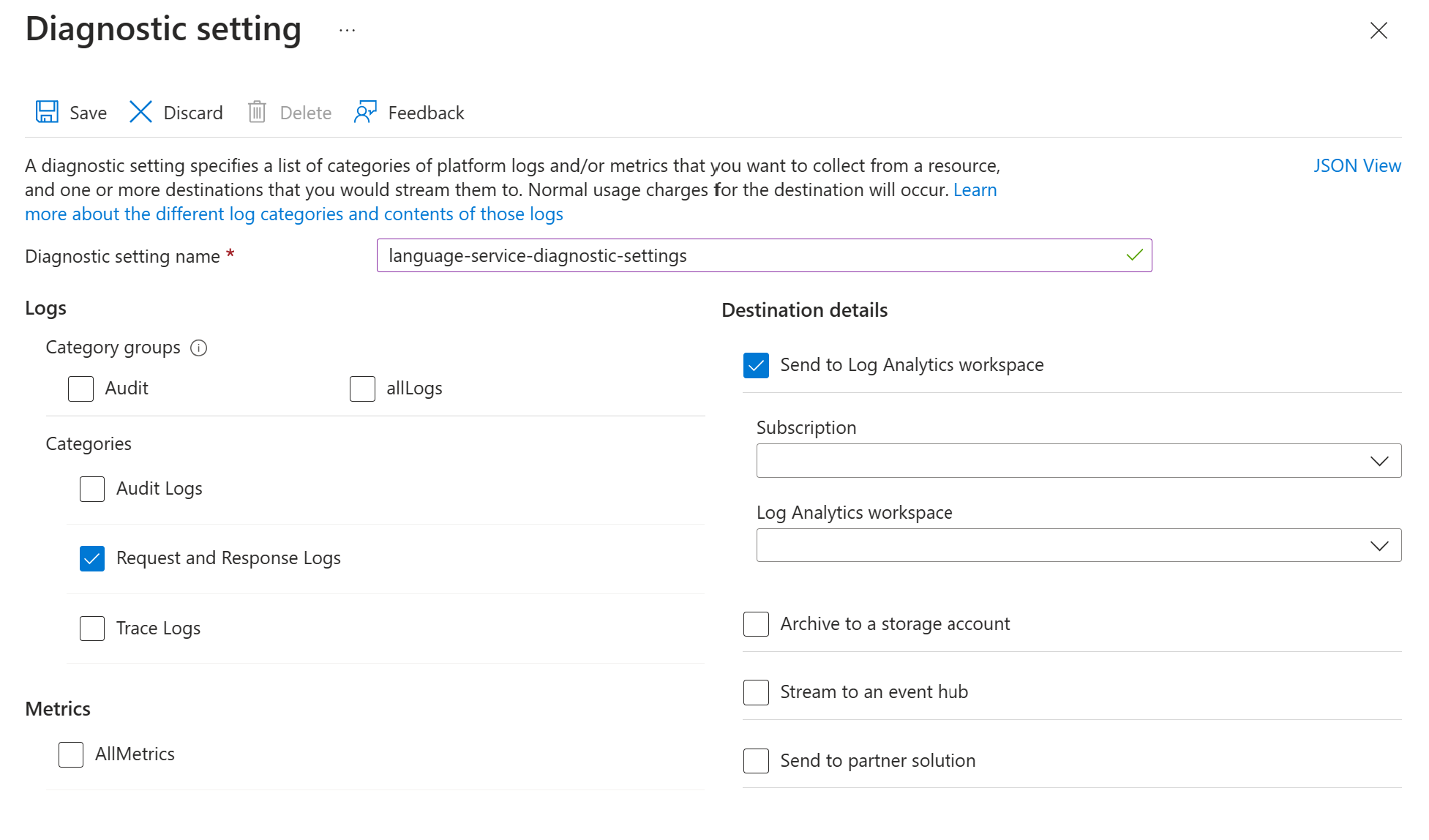
請按照以下步驟為 Text Analytics for Health API 啟用要求和回應記錄:
使用啟用 Azure AI 服務的診斷記錄中的說明來啟用您的 Azure 語言服務資源的診斷設置。 此資源與您在設定 Azure 語言服務部署步驟中建立的語言服務相同。
- 輸入診斷設定名稱。
- 將類別設置為請求與回應記錄。
- 有關目標詳細資訊,請選擇發送到 Log Analytics 工作區,然後選擇所需的 Log Analytics 工作區。 如果沒有工作區,請按照提示建立一個工作區。
- 儲存設定。
前往 NLP 擷取服務筆記本中的 NLP 配置部分。 將設定參數的值
enable_text_analytics_logs更新為True。 如需此筆記本的詳細資訊,請參閱檢閱您的筆記本設定。

檢視 Azure Log Analytics 中的記錄檔
若要瀏覽紀錄分析資料,請執行以下操作:
- 瀏覽至您的 Log Analytics 工作區 工作區。
- 找到並選擇記錄。 在此頁中,您可以對記錄執行查詢。
樣本查詢
以下是您可以用來探索記錄資料的基本 Kusto 查詢: 此範例查詢擷取過去一天中來自 Azure 認知服務資源提供程式的所有失敗請求,按錯誤類型分組:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature