在醫療保健資料解決方案中部署和設定 OMOP 轉換
注意
目前正在更新此內容。
OMOP 轉換透過觀察性醫療結果研究聯盟 (OMOP) 開放社區標準為標準化分析提供資料準備。 將醫療保健資料解決方案和醫療保健資料基礎功能部署到 Fabric 工作區後,就可以使用該功能。
OMOP 轉換是 Microsoft Fabric 中的醫療保健資料解決方案底下的一項選用功能。 您可以根據特定需求或情境靈活地決定是否使用它。
先決條件
- 在 Microsoft Fabric 中部署醫療保健資料解決方案。
- 在部署醫療保健資料基礎中安裝基礎筆記本和管線。
部署 OMOP 轉換
您可以使用醫療保健資料解決方案:部署醫療保健資料基礎中所述的設定模組來部署該功能。 但是,此模組中的樣本資料選取步驟不會為此功能部署樣本資料。 OMOP 轉換樣本資料在完成功能部署後,以獨佔方式安裝在醫療保健資料解決方案環境中。
如果您沒有使用設定模組來部署此功能,而是希望使用功能面板,請按照以下步驟操作:
前往 Fabric 上的醫療保健資料解決方案首頁。
選取 OMOP 轉換圖格。
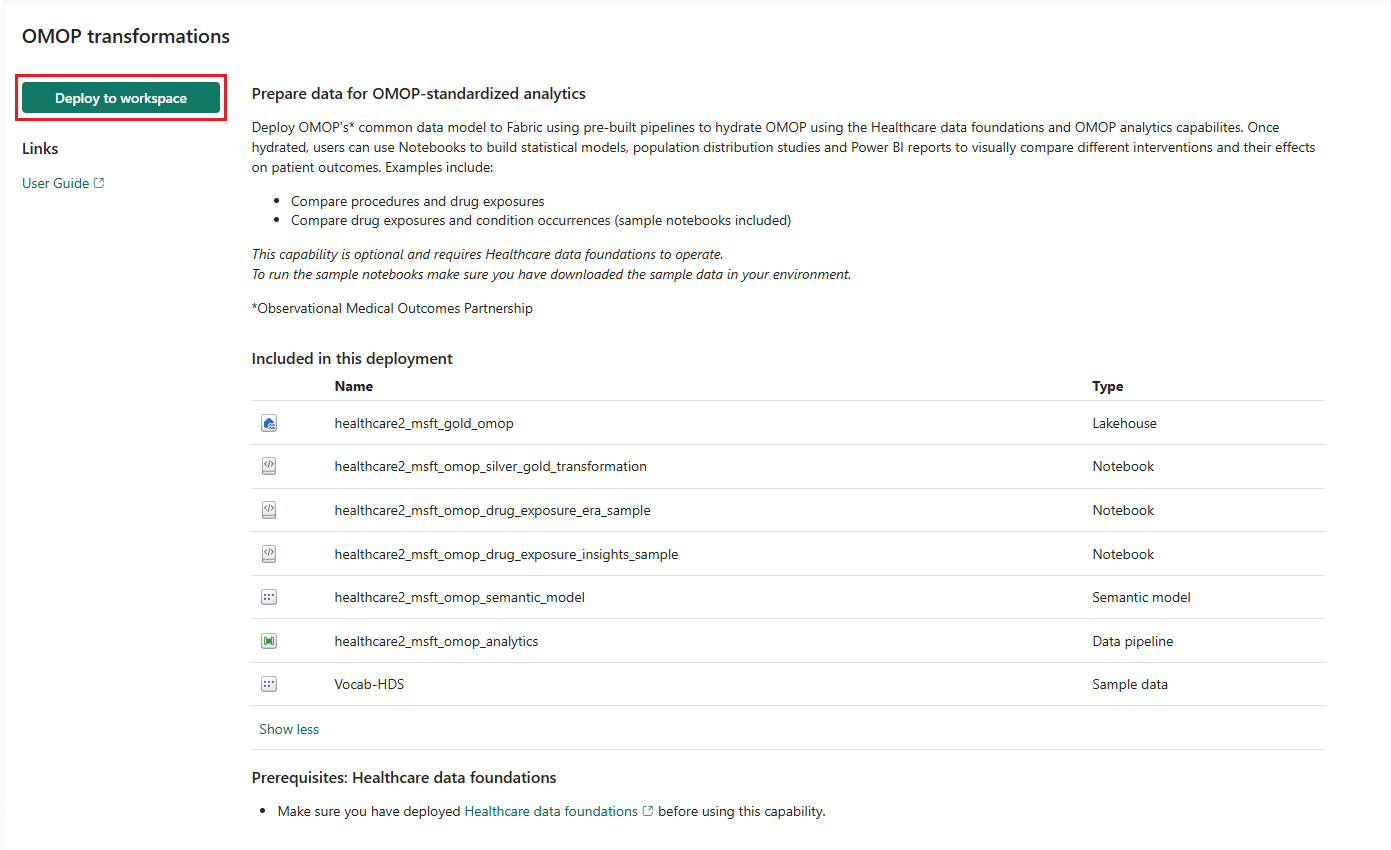
在功能頁面上,選擇部署到工作區。
部署可能需要幾分鐘才能完成。 部署過程中請勿關閉索引標籤或瀏覽器。 等待期間,您可以在另一個索引標籤中工作。
部署完成後,您可以在訊息欄上看到一則通知。
在訊息列中選擇管理能力,進入能力管理頁面。
在這裡,您可以查看、設定和管理使用該功能部署的成品。


成品
該功能在醫療保健資料解決方案環境中安裝以下成品:
| 成品 | 類型 |
|---|---|
| healthcare#_msft_gold_omop | 湖倉 |
| healthcare#_msft_omop_silver_gold_transformation | 筆記本 |
| healthcare#_msft_omop_drug_exposure_era_sample | 筆記本 |
| healthcare#_msft_omop_drug_exposure_insights_sample | 筆記本 |
| healthcare#_msft_omop_analytics | 資料準銷售案源 |
| healthcare#_msft_omop_semantic_model | 語意模型 |
| Vocab-HDS | 範例資料 |
檢閱 OMOP 銀牌筆記本
healthcare#_msft_omop_silver_gold_transformation 筆記本使用作為醫療保健資料解決方案庫的一部分提供的 OMOP API 進行資料轉換。 該筆記本將 healthcare#_msft_silver 湖倉中資源轉換成 OMOP common data model。 然後將轉換後的資料插入到 OMOP 湖倉中。
筆記本利用所需的預設定值部署,以執行 OMOP 轉換資料管線。 某些設定參數繼承自全域設定,且可以在筆記本等級覆寫。 根據預設,不需要對筆記本設定檔進行任何變更。 如果需要,可以透過選取環境中的相應筆記本和設定檔來查看或修改設定。
若要了解有關筆記本執行的詳細資訊,請參閱使用 OMOP 轉換。
檢閱 OMOP 語意模型
OMOP 語意模型 healthcare#_msft_omop_semantic_model 是基於 OMOP 金牌湖倉的訂製語意模型。 它包括下面 OMOP 表格之間的一些關鍵 OMOP CDM 版本 5.4 關係:
- 位置
- 人員
- 觀測
- Procedure_Occurrence
- Condition_Occurrence
- 注意
- Drug_Exposure
- Visit_Ocurrence
- Image_Occurrence
- 量值
這些關係形成在醫療保健資料解決方案的發現和建置同類群組 (預覽版) 功能中,產生 Power BI報告所需的最小集合。 您可以使用此語意模型作為基礎,從 OMOP 湖倉新增更多 OMOP 表格和關係,以根據您的 OMOP 標準湖倉資料建立自訂 Power BI 報告。
設定藥物暴露時代樣本筆記本
healthcare#_msft_omop_drug_exposure_era_sample 樣本筆記本示範如何在 Azure Synapse Analytics 筆記本中的使用 PySpark (Python) 語言的 OMOP 中產生 drug_era 表格記錄,主要用於探索目的。 drug_era 表格記錄產生遵循 OHDSI 藥物時代樣本指令碼,該指令碼適用於在 Azure Synapse Analytics 中使用 PySpark。 藥物時代產生器指令碼包含在自訂 Python 庫中,該庫打包為 wheel (WHL) 檔案並上傳到 Apache Spark 集區以便於存取。
在執行筆記本之前,請記住以下先決條件:
確定 OMOP 資料庫在下表中具有有效資料:
- drug_exposure
- 概念
- concept_ancestor
您可以使用樣本資料或你自己的資料,透過執行 FHIR 到 OMOP 資料管線來產生此資料。
請確認自訂庫 wheel 套件已附加到用於執行此筆記本的 Spark 集區。
此筆記本的關鍵設定參數為 omop_database_name。 此參數會識別包含用於產生 drug_era 表格的資料的 OMOP 資料庫名稱 。 僅當您的 OMOP 資料庫與全域設定檔中的預設值不同時,才更新此值。
如果 OMOP drug_exposure 表格填入有效資料,則此筆記本將叫用 DrugEraGenerator 模組,該模組會將一個人接觸到活性藥物成分的時間段串在一起,允許 30 天間隔。 DrugEraGenerator 模組會刪除所有現有的 drug_era 記錄,並根據最新 OMOP 資料產生新記錄。
若要了解有關筆記本執行的詳細資訊,請參閱使用 OMOP 轉換樣本筆記本。
設定藥物暴露深入解析樣本筆記本
healthcare#_msft_omop_drug_exposure_insights_sample 樣本筆記本展示對在 Azure Synapse Analytics 筆記本中使用 PySpark 的drug_era 表格的探索性分析。 該分析產生一個長條圖,顯示病患對活性成分的二次藥物暴露,按特定年份的性別和年齡分層。 drug_era 表格是使用上一個筆記本 healthcare#_msft_omop_drug_exposure_era_sample 叫用的自訂庫 DrugEraGenerator 產生的。 該分析透過合併基於性別和年齡的分層擴充了藥物暴露查詢 DEX03:年齡分佈,按藥物分層。
在執行筆記本之前,請記住以下先決條件:
- 如果要編輯筆記本設定,請務必複製此筆記本。 不要直接更新筆記本。
- 請透過執行藥物暴露時代筆記本來確認 drug_era 表格包含資料。 執行此筆記本會根據最新 OMOP 資料,將任何現有 drug_era 記錄替換為新記錄。
- 按原樣使用此筆記本以進行探索性分析,並建立副本以執行自訂分析。
以下關鍵筆記本設定參數。 您可以修改這些參數,以便對病患藥物暴露進行替代探索性分析:
primary_drug_concept_id:病患接觸的主要活性成分。secondary_drug_concept_id:病患接觸的次要活性成分。year:病患積極接觸主要和次要藥物的目標年份。
若要了解有關筆記本執行的詳細資訊,請參閱使用 OMOP 轉換樣本筆記本。