部署和設定醫療保健資料解決方案中的非結構化臨床筆記擴充 (預覽版)
[本文章是發行前版本文件,隨時可能變更。]
注意
目前正在更新此內容。
非結構化臨床筆記擴充 (預覽版) 使用 Azure AI 語言的Text Analytics for health 服務來擷取並新增結構到非結構化臨床筆記以進行分析。 將醫療保健資料解決方案部署到您的 Fabric 工作區和醫療保健資料基礎功能後,就可以部署和設定該功能。
非結構化臨床筆記擴充 (預覽版) 是 Microsoft Fabric 中的醫療保健資料解決方案底下的一項選用功能。 您可以根據特定需求或情境靈活地決定是否使用它。
先決條件
- 在 Microsoft Fabric 中部署醫療保健資料解決方案。
- 在部署醫療保健資料基礎中安裝基礎筆記本和管線。
設定 Azure 語言服務
前往 Azure 入口網站。
在首頁上,選取建立資源,搜尋 資源群組,然後建立新的 Azure 資源群組。
請確認資源群組上具有 Azure 角色型存取控制 (RBAC) 擁有者或使用者存取管理員角色。 若要指派權限,請按照授予存取權中的步驟操作。
建立資源群組後,返回到首頁,選取建立資源,搜尋語言服務,並將新的 Azure 語言服務部署到資源群組。 使用預設安裝設定。
重要
部署語言服務要求你接受 Azure 入口網站中的負責任的 AI 通知條款。 請務必在將語言服務新增到您的資源群組時,檢閱這些條款。 如需詳細資訊,請參閱下列透明度資訊:
部署非結構化臨床筆記擴充 (預覽版)
您可以使用醫療保健資料解決方案:部署醫療保健資料基礎中所述的設定模組來部署該功能。 在設定頁面中,提供 Azure Key Vault 值以連結到金鑰保存庫中的資料。
如果您沒有使用設定模組來部署此功能,而是希望使用功能面板,請按照以下步驟操作:
前往 Fabric 上的醫療保健資料解決方案首頁。
選取非結構化臨床筆記擴充 (預覽版) 圖格。
在功能頁面上,選擇部署到工作區。
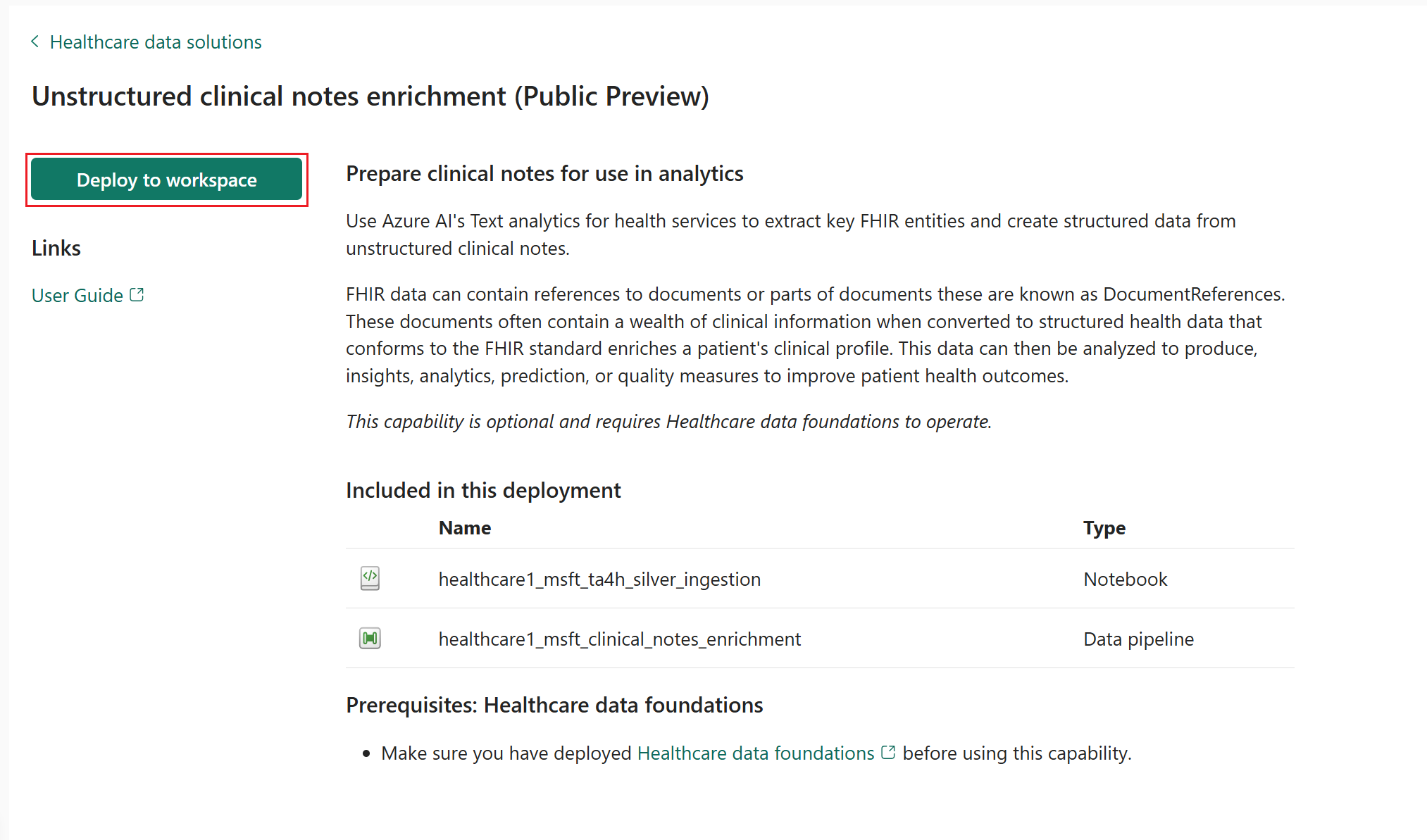
部署可能需要幾分鐘才能完成。 部署過程中請勿關閉索引標籤或瀏覽器。 等待期間,您可以在另一個索引標籤中工作。
部署完成後,您可以在訊息欄上看到一則通知。
在訊息列中選擇管理能力,進入能力管理頁面。
在這裡,您可以查看、設定和管理使用該功能部署的成品。


成品
該功能在您的醫療保健資料解決方案環境中安裝一個筆記本和一個資料管線。
| 成品 | 類型 | Description |
|---|---|---|
| healthcare#_msft_ta4h_silver_ingestion | 筆記本 | 使用 Azure Text Analytics for health NLP API 來處理和分析非結構化文字資料。 |
| healthcare#_msft_clinical_notes_enrichment | 資料準銷售案源 | 按順序執行一系列筆記本,從非結構化臨床筆記中擷取關鍵的快速健康照護互通資源 (FHIR) 實體,建構資料並將結果儲存在銀牌湖倉中。 |
檢閱筆記本設定
healthcare#_msft_ta4h_silver_ingestion 筆記本在醫療保健資料解決方案庫中執行 NLPIngestionService 模組,並使用 Azure Text Analytics for health 服務。 此服務是一個自然語言處理 (NLP) API,用於處理和分析非結構化文字資料。 結果儲存在 healthcare#_msft_silver 湖倉中。
以下是此筆記本的關鍵設定參數:
NLP Config:允許您自訂 NLP 設定以符合特定的使用者要求。
此筆記本利用所需的預設定值部署,以執行相關資料管線。 某些設定參數繼承自全域配置。 根據預設,不需要對筆記本設定檔進行任何變更。 如果需要,可以打開筆記本並檢閱設定。