在 Databricks 筆記本中開發程式碼
此頁面描述如何在 Databricks 筆記本中開發程式碼,包括自動完成、Python 和 SQL 的自動格式化、在筆記本中結合 Python 與 SQL,以及追蹤筆記本版本歷程記錄。
如需編輯器可用進階功能的詳細資訊,例如自動完成、變數選取、多重游標支援和並排比較,請參閱 流覽 Databricks 筆記本和檔案編輯器。
當您使用筆記本或檔案編輯器時,可以使用 Databricks Assistant 來協助您產生、說明和偵錯程式代碼。 如需詳細資訊,請參閱使用 Databricks Assistant。
Databricks 筆記本也包含適用於 Python 筆記本的內建互動式偵錯工具。 請參閱偵錯筆記本。
模組化程式碼
重要
這項功能處於公開預覽狀態。
使用 Databricks Runtime 11.3 LTS 和更高版本,您可以在 Azure Databricks 工作區中建立和管理原始程式碼檔案,然後視需要將這些檔案匯入筆記本。
如需使用原始程式碼檔案的詳細資訊,請參閱在 Databricks 筆記本之間共用程式碼和使用 Python 和 R 模組。
格式化程式碼儲存格
Azure Databricks 提供工具,可讓您快速且輕鬆地在筆記本儲存格中格式化 Python 和 SQL 程式碼。 這些工具可減少將程式碼格式化的工作,並協助在您的筆記本中強制執行相同的編碼標準。
Python 黑色格式器程式庫
重要
這項功能處於公開預覽狀態。
Azure Databricks 支援在筆記本中使用黑色來格式化 Python 程式碼。 筆記本必須附加至已安裝 black 和 tokenize-rt Python 套件的叢集。
在 Databricks Runtime 11.3 LTS 和更新版本上,Azure Databricks 會預安裝 black 和 tokenize-rt: 您可以直接使用格式器,不需要安裝這些程式庫。
在 Databricks Runtime 10.4 LTS 和以下版本上,您必須從 PyPI 安裝 black==22.3.0 和 tokenize-rt==4.2.1 到筆記本或叢集上,才能使用 Python 格式器。 您可以在筆記本中執行下列命令:
%pip install black==22.3.0 tokenize-rt==4.2.1
或者在叢集上安裝程式庫。
如需安裝程式庫的詳細資訊,請參閱 Python 環境管理。
對於 Databricks Git 資料夾中的檔案和筆記本,您可以根據 pyproject.toml 檔案設定 Python 格式器。 若要使用此功能,請在 Git 資料夾根目錄中建立 pyproject.toml 檔案,並根據黑色組態格式進行設定。 編輯檔案中的 [tool.black] 區段。 當您格式化該 Git 資料夾中的任何檔案和筆記本時,設定即會套用。
如何格式化 Python 和 SQL 儲存格
您必須擁有筆記本的 [可以編輯] 權限,才能格式化程式碼。
Azure Databricks 會使用 Gethue/sql-formatter 程式庫來格式化 SQL 和適用於 Python 的黑色程式碼格式器。
可以透過下列方式觸發格式器:
格式化單一儲存格
格式化多個儲存格
選取多個儲存格,然後選取 [編輯 > 格式儲存格]。 如果您選取多個語言的儲存格,則只會格式化 SQL 和 Python 數據格。 這包括使用
%sql與%python的儲存格。格式化筆記本中的所有 Python 和 SQL 儲存格
選取 編輯 > 格式筆記本。 如果您的筆記本包含一種以上的語言,則只會格式化 SQL 和 Python 儲存格。 這包括使用
%sql與%python的儲存格。
程式碼格式化限制
- Black 會強制執行 4 個空間縮排的 PEP 8 標準。 無法設定縮排。
- 不支援格式化 SQL UDF 內的內嵌 Python 字串。 同樣,不支援在 Python UDF 內格式化 SQL 字串。
筆記本中的程式碼語言
設定預設語言
筆記本的預設語言顯示在筆記本名稱旁邊。

若要變更默認語言,請按下語言按鈕,然後從下拉功能表中選取新語言。 為了確保現有的命令能夠繼續運作,先前預設語言的命令會自動加上語言魔術命令的前置詞。
混合語言
根據預設,儲存格會使用筆記本的預設語言。 您可以按下語言按鈕,然後從下拉式功能表中選取語言,以覆寫儲存格中的預設語言。
或者,您可以在儲存格開頭使用語言魔術命令 %<language>。 支援的魔術命令包括: %python、%r、%scala 和 %sql。
注意
當您叫用語言魔術命令時,命令會分派至筆記本執行內容中的 REPL。 以一種語言定義的變數 (因此在該語言的 REPL 中) 在另一種語言的 REPL 中不可用。 REPL 只能透過外部資源分享狀態,例如 DBFS 中的檔案或物件儲存體中的物件。
筆記本也支援一些輔助魔術命令:
-
%sh:可讓您在筆記本中執行 shell 程式碼。 如果 shell 命令具有非零離開狀態,則若要使儲存格失敗,請新增-e選項。 此命令只會在 Apache Spark 驅動程式上執行,而不是背景工作角色上。 若要在所有節點上執行 shell 命令,請使用 init 指令碼。 -
%fs:可讓您使用dbutils檔案系統命令。 例如,若要執行dbutils.fs.ls命令來列出檔案,您可以改為指定%fs ls。 如需詳細資訊,請參閱使用 Azure Databricks 上的檔案。 -
%md:可讓您包括各種類型的文件,包括文字、影像,以及數學公式和方程式。 請參閱下一節。
Python 命令中的 SQL 語法反白顯示與自動完成
當您在 Python 命令 (例如 命令) 中使用 SQL 時,可以使用語法醒目提示和 SQL spark.sql。
探索 SQL 數據格結果
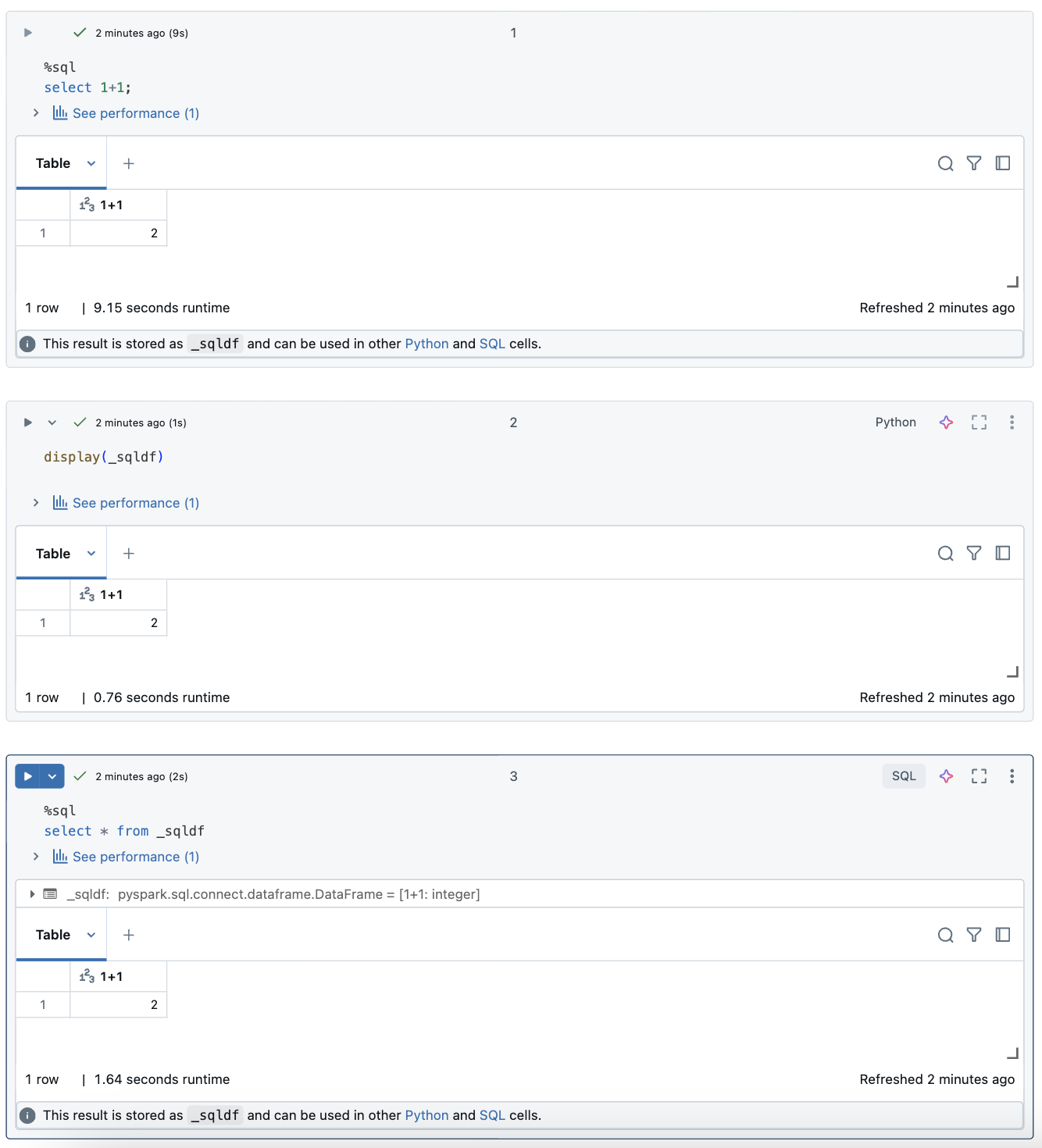
在 Databricks 筆記本中,SQL 語言數據格的結果會自動以指派給變數 _sqldf的隱含 DataFrame 形式提供。 然後,您可以在之後執行的任何 Python 和 SQL 數據格中使用此變數,不論其在筆記本中的位置為何。
注意
這項功能有下列限制:
- 變數
_sqldf不適用於使用 SQL 倉儲 進行計算的筆記本。 - Databricks Runtime 13.3 和更新版本支持在
_sqldf後續 Python 數據格中使用 。 - 只有 Databricks Runtime 14.3 和更新版本才支援在
_sqldf後續的 SQL 數據格中使用 。 - 如果查詢使用 關鍵詞
CACHE TABLE或UNCACHE TABLE,則_sqldf無法使用 變數。
下列螢幕快照顯示如何在 _sqldf 後續的 Python 和 SQL 數據格中使用:
重要
每次執行 SQL 數據格時,變數 _sqldf 都會重新指派。 若要避免遺失特定 DataFrame 結果的參考,請在執行下一個 SQL 數據格之前,將它指派給新的變數名稱:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
平行執行 SQL 儲存格
當命令正在執行,且筆記本已連結至互動式叢集時,可以使用目前的命令同時執行 SQL 儲存格。 SQL 儲存格在新的平行工作階段中執行。
若要平行執行儲存格:
按下 [立即執行]。 儲存格會立即執行。
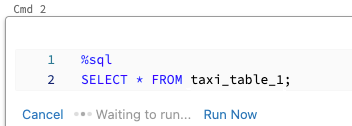
因為單元格是在新的會話中執行,因此對於平行執行的單元格,不支援暫時檢視、UDF 和 隱含的 Python DataFrame (_sqldf)。 此外,在平行執行期間會使用預設目錄和資料庫名稱。 如果您的程式代碼參考不同目錄或資料庫中的數據表,您必須使用三層命名空間來指定數據表名稱(catalog.schema.table)。
在 SQL 倉儲上執行 SQL 儲存格
您可以在 Databricks 筆記本中的 SQL 倉儲上執行 SQL 命令,SQL 倉儲是一種針對 SQL 分析進行最佳化的計算類型。 請參閱<將筆記本搭配 SQL 倉儲使用>。