資料湖是什麼?
Data Lake 是記憶體存放庫,其原生原始格式會保存大量數據。 Data Lake 存放區已優化,可將其大小調整為 TB 和 PB 的數據。 數據通常來自多個不同的來源,而且可以包含結構化、半結構化或非結構化數據。 Data Lake 可協助您將所有項目儲存在其原始且未轉換的狀態。 此方法與傳統 的數據倉儲不同,它會在擷取時轉換和處理數據。
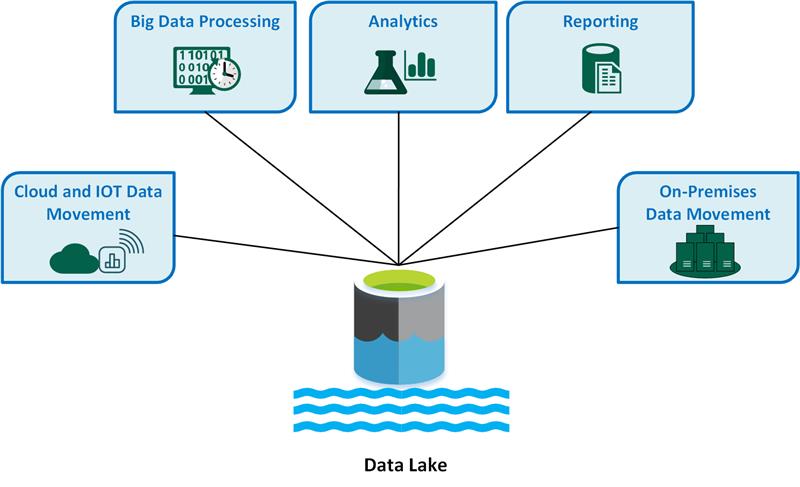
主要 Data Lake 使用案例包括:
- 雲端和物聯網 (IoT) 資料移動。
- 巨量數據處理。
- 分析。
- 報告。
- 內部部署數據移動。
請考慮 Data Lake 的下列優點:
數據湖永遠不會刪除數據,因為它會以原始格式儲存數據。 這項功能在巨量數據環境中特別有用,因為您可能事先不知道您可以從數據取得哪些見解。
使用者可以探索數據並建立自己的查詢。
數據湖可能比傳統擷取、轉換、載入 (ETL) 工具快。
數據湖比數據倉儲更有彈性,因為它可以儲存非結構化和半結構化數據。
完整的 Data Lake 解決方案包含記憶體和處理。 Data Lake Storage 是針對容錯、無限延展性和高輸送量擷取各種圖形和大小所設計。 Data Lake Processing 牽涉到一或多個可納入這些目標的處理引擎,並可大規模操作儲存在 Data Lake 中的數據。
當您應該使用 Data Lake 時
建議您使用 Data Lake 進行數據探索、數據分析和機器學習。
Data Lake 可以做為數據倉儲的數據源。 當您使用此方法時,Data Lake 會擷取原始數據,然後將它轉換成結構化的可查詢格式。 此轉換通常會使用 擷取、載入、轉換 (ELT) 管線,在其中內嵌和轉換數據。 關係型源數據可能會透過 ETL 程式直接進入數據倉儲,並略過數據湖。
您可以在事件串流或IoT案例中使用Data Lake存放區,因為數據湖可以保存大量的關係型和非關係型數據,而不需要轉換或架構定義。 Data Lake 可以在低延遲時處理大量的小型寫入,並針對大量輸送量進行優化。
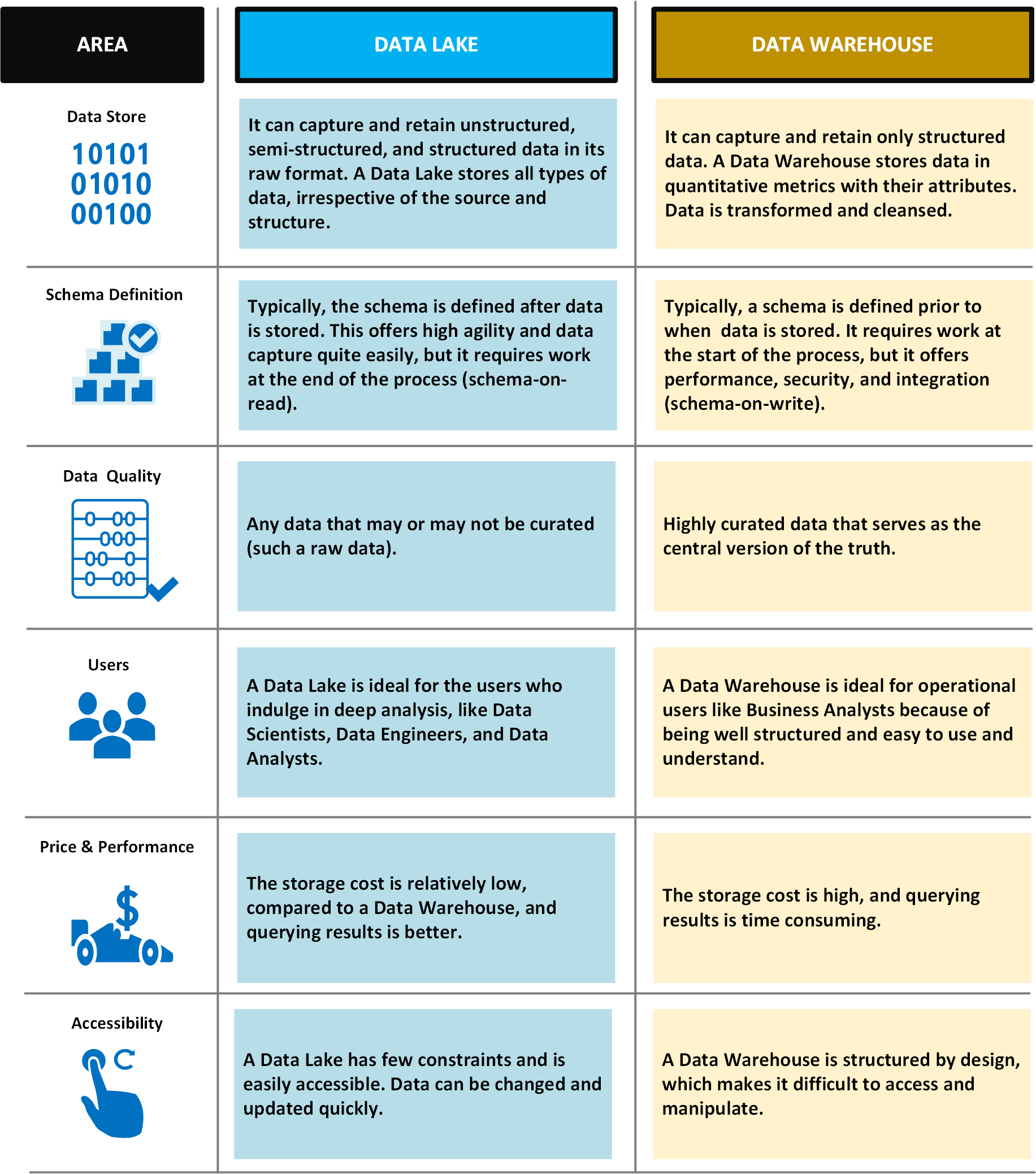
下表比較數據湖和數據倉儲。
挑戰
大量數據: 大量原始和非結構化數據的管理可能會複雜且需要大量資源,因此您需要強大的基礎結構和工具。
潛在的瓶頸: 數據處理可能會造成延遲和效率低下,特別是當您擁有大量數據和各種數據類型時。
數據損毀風險: 不正確的數據驗證和監視會造成數據損毀的風險,這可能會危害數據湖的完整性。
品質控制問題: 由於各種數據源和格式,適當的數據品質是一項挑戰。 您必須實作嚴格的數據控管做法。
效能問題: 查詢效能隨著數據湖成長而降低,因此您必須優化記憶體和處理策略。
技術選擇
當您在 Azure 上建置完整的 Data Lake 解決方案時,請考慮下列技術:
Azure Data Lake Storage 結合了 Azure Blob 儲存體 與 Data Lake 功能,可提供 Apache Hadoop 相容存取、階層命名空間功能,以及增強的安全性,以有效率地進行巨量數據分析。
Azure Databricks 是一個統一的平臺,可用來處理、儲存、分析及獲利數據。 它支援 ETL 程式、儀錶板、安全性、數據探索、機器學習和產生 AI。
Azure Synapse Analytics 是一項統一的服務,可用來內嵌、探索、準備、管理和提供數據,以滿足立即的商業智慧和機器學習需求。 它會與 Azure Data Lake 深入整合,讓您可以有效率地查詢和分析大型數據集。
Azure Data Factory 是雲端式數據整合服務,可讓您用來建立數據驅動工作流程,然後協調及自動化數據移動和轉換。
Microsoft Fabric 是一個全面的數據平臺,可將數據工程、數據科學、數據倉儲、即時分析和商業智慧整合成單一解決方案。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主要作者:
- Avijit Prasad |雲端顧問
若要查看非公開的 LinkedIn 設定檔,請登入 LinkedIn。
下一步
- 什麼是 OneLake?
- Data Lake Storage 簡介
- Azure Data Lake Analytics 檔
- 訓練:Data Lake Storage 簡介
- Hadoop 和 Azure Data Lake Storage 整合
- 線上到 Data Lake Storage 和 Blob 記憶體
- 使用 Azure Data Factory 將數據載入 Data Lake Storage