組織面臨的常見問題是如何以多種格式從多個來源收集數據。 然後,您必須將它移至一或多個資料存放區。 目的地可能不是與來源相同的數據存放區類型。 格式通常不同,或者數據必須在載入其最終目的地之前加以成形或清理。
多年來已開發各種工具、服務和程式,以協助解決這些挑戰。 不論使用的程序為何,都需要協調工作,並在數據管線內套用某種層級的數據轉換。 下列各節會醒目提示用來執行這些工作的常見方法。
擷取、轉換、載入 (ETL) 程式
擷取、轉換、載入 (ETL) 是用來從各種來源收集數據的數據管線。 然後,它會根據商務規則轉換數據,並將數據載入目的地數據存放區。 ETL 中的轉換工作會在特製化引擎中進行,而且通常會牽涉到使用臨時表暫時保存數據,因為數據正在轉換,最後載入至目的地。
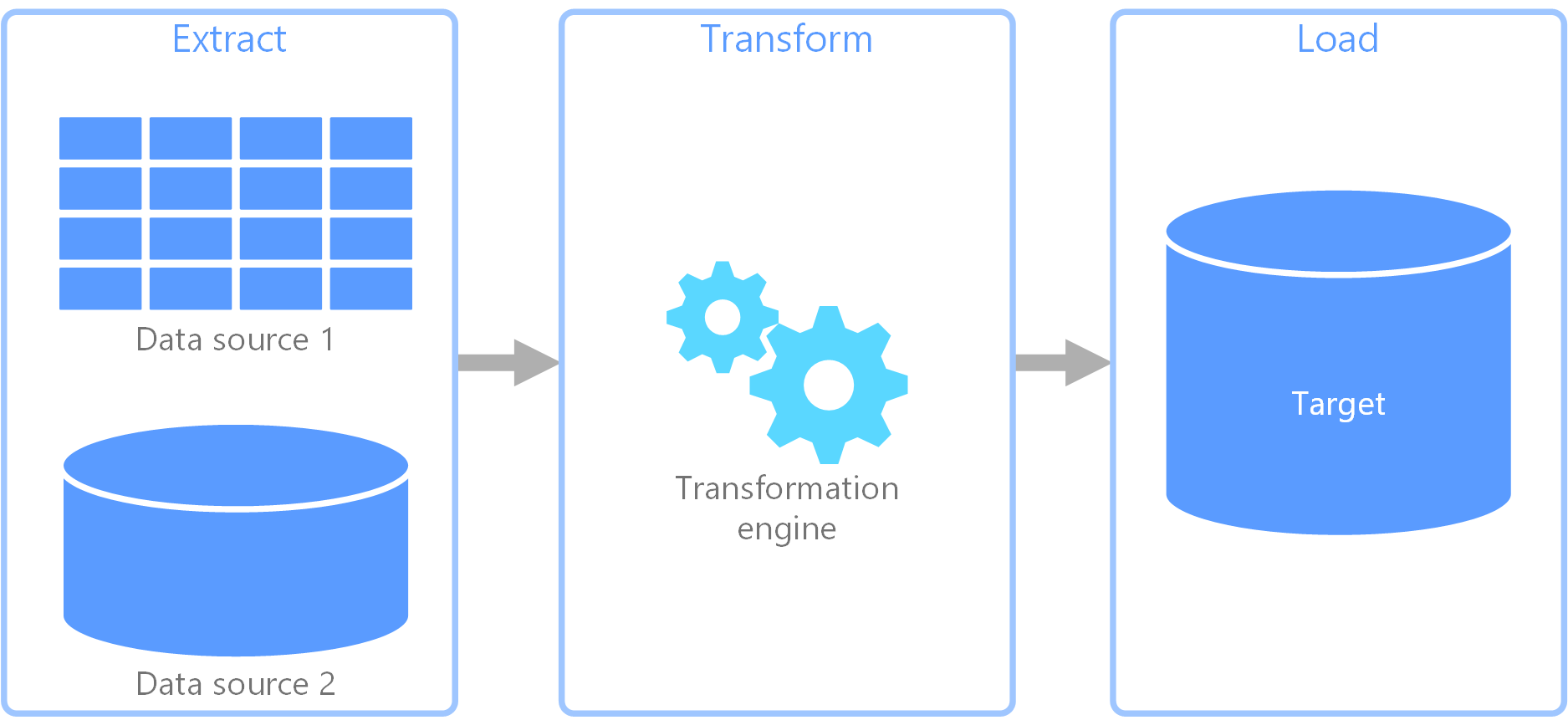
進行的數據轉換通常涉及各種作業,例如篩選、排序、匯總、聯結數據、清除數據、重複數據刪除和驗證數據。
這三個 ETL 階段通常會以平行方式執行,以節省時間。 例如,在擷取數據時,轉換程式可能會處理已接收的數據並準備載入,而載入程式可以開始處理備妥的數據,而不是等待整個擷取程式完成。
相關的 Azure 服務:
其他工具:
擷取、載入、轉換 (ELT)
擷取、載入、轉換 (ELT) 與 ETL 完全不同,只是在轉換發生的地方。 在 ELT 管線中,轉換會發生在目標資料存放區中。 而不是使用個別的轉換引擎,而是使用目標數據存放區的處理功能來轉換數據。 這可藉由從管線移除轉換引擎來簡化架構。 此方法的另一個優點是調整目標數據存放區也會調整 ELT 管線效能。 不過,只有在目標系統強大到足以有效率地轉換數據時,ELT 才能正常運作。
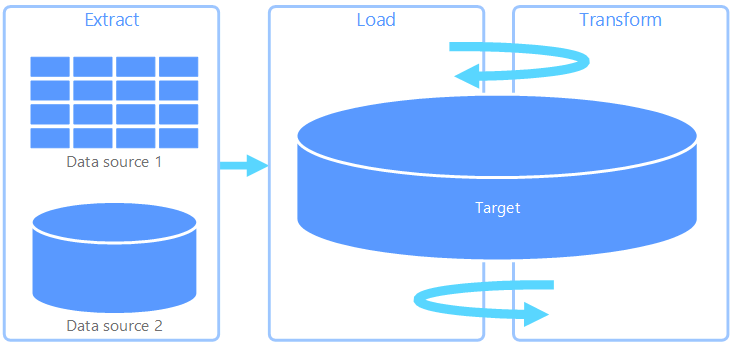
ELT 的典型使用案例落在巨量數據領域。 例如,您可以從將所有源數據擷取至可調整記憶體中的一般檔案,例如 Hadoop 分散式文件系統、Azure Blob 存放區或 Azure Data Lake Gen 2(或組合)。 接著,Spark、Hive 或 PolyBase 等技術可用來查詢源數據。 ELT 的關鍵點是,用來執行轉換的數據存放區與最終取用數據的數據存放區相同。 此數據存放區會直接從可調整的記憶體讀取,而不是將數據載入自己的專屬記憶體。 此方法會略過 ETL 中存在的數據複製步驟,這通常是大型數據集耗時的作業。
實際上,目標數據存放區是使用 Hadoop 叢集(使用 Hive 或 Spark)或 Azure Synapse Analytics 上的 SQL 專用集區,數據倉儲。 一般而言,架構會在查詢時覆寫在一般檔案數據上,並儲存為數據表,讓數據能夠像數據存放區中的其他數據表一樣進行查詢。 這些稱為外部數據表,因為數據不在數據存放區本身管理的記憶體中,而是位於某些外部可調整的記憶體上,例如 Azure Data Lake 存放區或 Azure Blob 記憶體。
數據存放區只會管理數據的架構,並在讀取時套用架構。 例如,使用Hive的Hadoop叢集會描述Hive數據表,其中數據源實際上是HDFS中一組檔案的路徑。 在 Azure Synapse 中,PolyBase 可以達到相同的結果,針對儲存在資料庫本身外部的數據建立數據表。 載入源數據之後,就可以使用數據存放區的功能來處理外部數據表中的數據。 在巨量數據案例中,這表示數據存放區必須能夠進行大量平行處理(MPP),這會將數據分成較小的區塊,並將區塊的處理平行分散到多個節點。
ELT 管線的最後階段通常是將源數據轉換成最終格式,對於需要支持的查詢類型更有效率。 例如,數據可能會分割。 此外,ELT 可能會使用已優化的儲存格式,例如 Parquet,其會以單欄方式儲存數據列導向數據,並提供優化的索引編製。
相關的 Azure 服務:
- Azure Synapse Analytics 上的 SQL 專用集區
- Azure Synapse Analytics 上的 SQL 無伺服器集區
- HDInsight 與Hive
- Azure Data Factory
- Power BI 中的數據超市
其他工具:
數據流和控制流程
在數據管線的內容中,控制流程可確保一組工作的有序處理。 若要強制執行這些工作的正確處理順序,會使用優先順序條件約束。 您可以將這些條件約束視為工作流程圖表中的連接器,如下圖所示。 每項工作都有結果,例如成功、失敗或完成。 在前置任務完成之前,任何後續工作都不會起始處理,並包含其中一個結果。
控制流程會以工作的形式執行數據流。 在數據流工作中,數據會從來源擷取、轉換或載入至數據存放區。 一個數據流工作的輸出可以是下一個數據流工作的輸入,而且數據流可以平行執行。 不同於控制流程,您無法在數據流中新增工作之間的條件約束。 不過,您可以新增數據查看器來觀察每個工作所處理的數據。
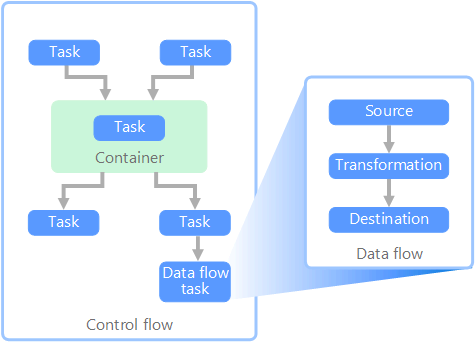
在上圖中,控制流程中有數個工作,其中一個是數據流工作。 其中一項工作是巢狀在容器內。 容器可用來提供工作的結構,並提供工作單位。 其中一個範例是重複集合內的元素,例如資料夾或資料庫語句中的檔案。
相關的 Azure 服務:
其他工具:
技術選擇
下一步
- 將數據與 Azure Data Factory 或 Azure Synapse Pipeline 整合
- Azure Synapse Analytics 簡介
- 在 Azure Data Factory 或 Azure Synapse Pipeline 中協調數據移動和轉換
相關資源
下列參考架構會顯示 Azure 上的端對端 ELT 管線: