使用医疗保健数据解决方案中的非结构化临床笔记扩充(预览版)
[本文为预发布文档,可能会发生变化。]
备注
此内容目前正在更新。
非结构化临床笔记扩充(预览版)使用 Azure AI 语言的 Text Analytics for Health 服务,从非结构化临床笔记中提取关键的快速医疗保健互操作性资源 (FHIR) 实体。 它从这些临床笔记中创建结构化数据。 然后,您可以分析这些结构化数据,以获得旨在提高患者健康状况结果的见解、预测和质量度量值。
若要了解有关该功能的详细信息并了解如何部署和配置它,请参阅:
非结构化临床笔记扩充(预览版)直接依赖于医疗保健数据基础功能。 确保首先成功设置和执行医疗保健数据基础管道。
先决条件
- 部署 Microsoft Fabric 中的医疗保健数据解决方案
- 在部署医疗保健数据基础中安装基础笔记本和管道。
- 设置 Azure 语言服务,如设置 Azure 语言服务中所述。
- 部署和配置非结构化临床笔记扩充(预览版)
- 部署和配置 OMOP 转换。 此步骤是可选的。
NLP 引入服务
healthcare#_msft_ta4h_silver_ingestion 笔记本执行医疗保健数据解决方案库中的 NLPIngestionService 模块,以调用 Text Analytics for Health 服务。 此服务从 FHIR 资源 DocumentReference.Content 中提取非结构化临床笔记,以创建平展的输出。 若要了解详细信息,请参阅查看笔记本配置。
银牌层中的数据存储
在自然语言处理 (NLP) API 分析之后,结构化和平展的输出将存储在 healthcare#_msft_silver 湖屋内的以下本机表中:
- nlpentity:包含从非结构化临床笔记中提取的平展实体。 每行都是执行文本分析后从非结构化文本中提取的单个术语。
- nlprelationship:提供提取的实体之间的关系。
- nlpfhir:以 JSON 字符串形式包含 FHIR 输出捆绑包。
若要跟踪上次更新的时间戳,NLPIngestionService 在所有三个银牌湖屋表中使用 parent_meta_lastUpdated 字段。 此跟踪可确保首先存储作为父资源的源文档 DocumentReference,以保持引用完整性。 此流程有助于防止数据和孤立资源中出现不一致。
重要提示
目前,Text Analytics for Health 返回在 UMLS 超级叙词表词汇文档文档中列出的词汇。 有关这些词汇的指南,请参阅从 UMLS 导入数据。
对于预览版,我们使用 SNOMED-CT(医学系统命名法 - 临床术语)、LOINC(观测指标标识符逻辑命名与编码系统)和 RxNorm 术语,这些术语根据观察性健康医疗数据科学与信息学 (OHDSI) 中的指导包含在 OMOP 示例数据集中。
OMOP 转换
Microsoft Fabric 中的医疗保健数据解决方案还为观察性医疗结果伙伴关系 (OMOP) 转换提供了另一种功能。 当您执行此功能时,从银牌湖屋到 OMOP 金牌湖屋的基础转换也会转换非结构化临床笔记分析的结构化和平展输出。 从银牌湖屋的 nlpentity 表中读取转换,并将输出映射到 OMOP 金牌湖屋的 NOTE_NLP 表中。
有关详细信息,请参阅 OMOP 转换概述。
下面是结构化 NLP 输出的架构,其中包含映射到 OMOP Common Data Model 的相应 NOTE_NLP 列:
| 平展文档引用 | 描述 | Note_NLP 映射 | 抽样数据 |
|---|---|---|---|
| ID | 实体的唯一标识符。 parent_id、offset 和 length 的组合键。 |
note_nlp_id |
1380 |
| parent_id | 从中提取术语的平展 documentreferencecontent 文本的外键。 | note_id |
625 |
| text | 文档中显示的实体文本。 | lexical_variant |
否认过敏史 |
| 偏移 | 输入 documentreferencecontent 文本中提取的术语的字符偏移量。 | offset |
294 |
| data_source_entity_id | 给定源目录中的实体的 ID。 | note_nlp_concept_id 和 note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | documentreferencecontent 文本分析处理的日期。 | nlp_date_time 和 nlp_date |
2023-05-17T00:00:00.0000000 |
| 模型 | NLP 系统的名称和版本(Text Analytics for Health NLP 系统的名称和版本)。 | nlp_system |
MSFT TA4H |

Text Analytics for Health 的服务限制
- 每个文档的最大字符数限制为 125,000 个。
- 整个请求中包含的文档的最大大小限制为 1 MB。
- 每个请求的最大文档数限制为:
- 对于基于 Web 的 API,为 25 个。
- 对于容器,为 1000 个。
启用日志
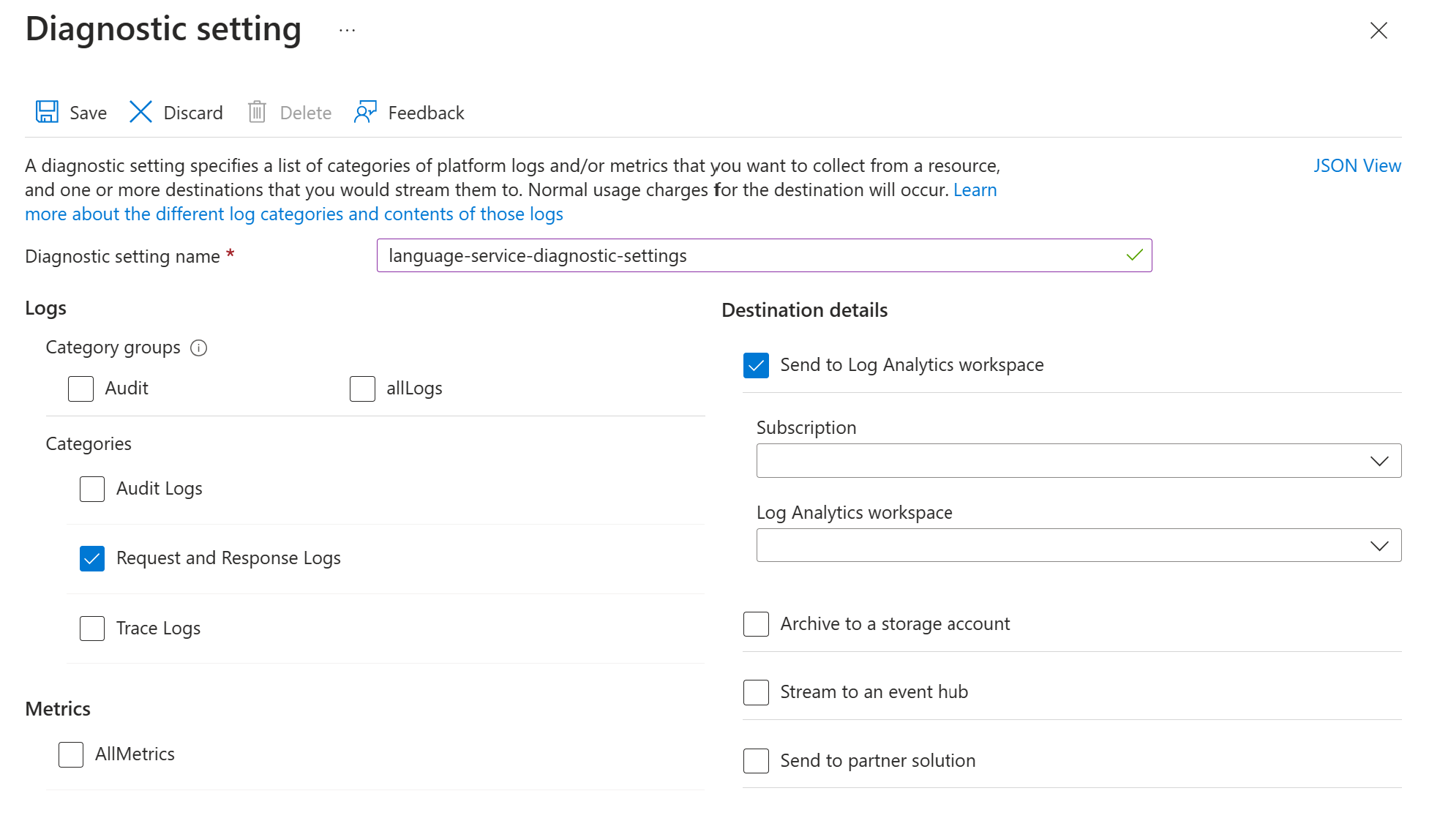
按照以下步骤启用 Text Analytics for Health API 的请求和响应日志记录:
使用启用 Azure AI 服务的诊断日志记录中的说明,启用 Azure 语言服务资源的诊断设置。 此资源与您在设置 Azure 语言服务部署步骤中创建的语言服务相同。
- 输入诊断设置名称。
- 将类别设置为请求和响应日志。
- 有关目标详细信息,请选择发送到 Log Analytics 工作区,然后选择所需的 Log Analytics 工作区。 如果没有工作区,请按照提示创建一个工作区。
- 保存设置。
转到 NLP 引入服务笔记本中的 NLP 配置部分。 将配置参数
enable_text_analytics_logs的值更新为True。 有关此笔记本的详细信息,请参阅查看笔记本配置。

在 Azure Log Analytics 中查看日志
若要探索日志分析数据,请按照以下步骤操作:
- 导航到 Log Analytics 工作区。
- 查找并选择日志。 从此页面中,您可以对日志运行查询。
示例查询
下面是一个基本的 Kusto 查询,可用于探索日志数据。 此示例查询检索前一天来自 Azure 认知服务资源提供程序的所有失败请求,并按错误类型分组:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature