部署和配置医疗保健数据解决方案中的非结构化临床笔记扩充(预览版)
[本文为预发布文档,可能会发生变化。]
备注
此内容目前正在更新。
非结构化临床笔记扩充(预览版)使用 Azure AI 语言的 Text Analytics for Health 服务,将结构提取并添加到非结构化临床笔记以进行分析。 在将医疗保健数据解决方案和医疗保健数据基础功能部署到 Fabric 工作区后,您可以部署和配置此功能。
非结构化临床笔记扩充(预览版)是 Microsoft Fabric 中医疗保健数据解决方案下的一项可选功能。 您可以根据具体需求或应用场景灵活地决定是否使用它。
先决条件
- 部署 Microsoft Fabric 中的医疗保健数据解决方案。
- 在部署医疗保健数据基础中安装基础笔记本和管道。
设置 Azure 语言服务
转到 Azure 门户。
在主页上,选择创建资源,搜索资源组,然后创建新的 Azure 资源组。
确保在资源组上具有 Azure 基于角色的访问控制 (RBAC) 负责人或用户访问管理员角色。 若要分配权限,请按照授予访问权限中的步骤操作。
创建资源组后,返回到主页,选择创建资源,搜索语言服务,然后将新的 Azure 语言服务部署到您的资源组。 使用默认设置。
重要提示
部署语言服务需要您接受 Azure 门户中的负责任 AI 通知条款。 将语言服务添加到资源组时,请务必查看这些条款。 有关详细信息,请参阅以下透明度说明。
部署非结构化临床笔记扩充(预览版)
您可以使用医疗保健数据解决方案:部署医疗保健数据基础中所述的设置模块部署该功能。 在设置页面中,提供 Azure Key Vault 值以链接密钥保管库中的数据。
如果未使用设置模块部署该功能,而是希望改用功能磁贴,请按照以下步骤操作:
转到 Fabric 上的“医疗保健数据解决方案”主页。
选择“非结构化临床笔记扩充(预览版)”磁贴。
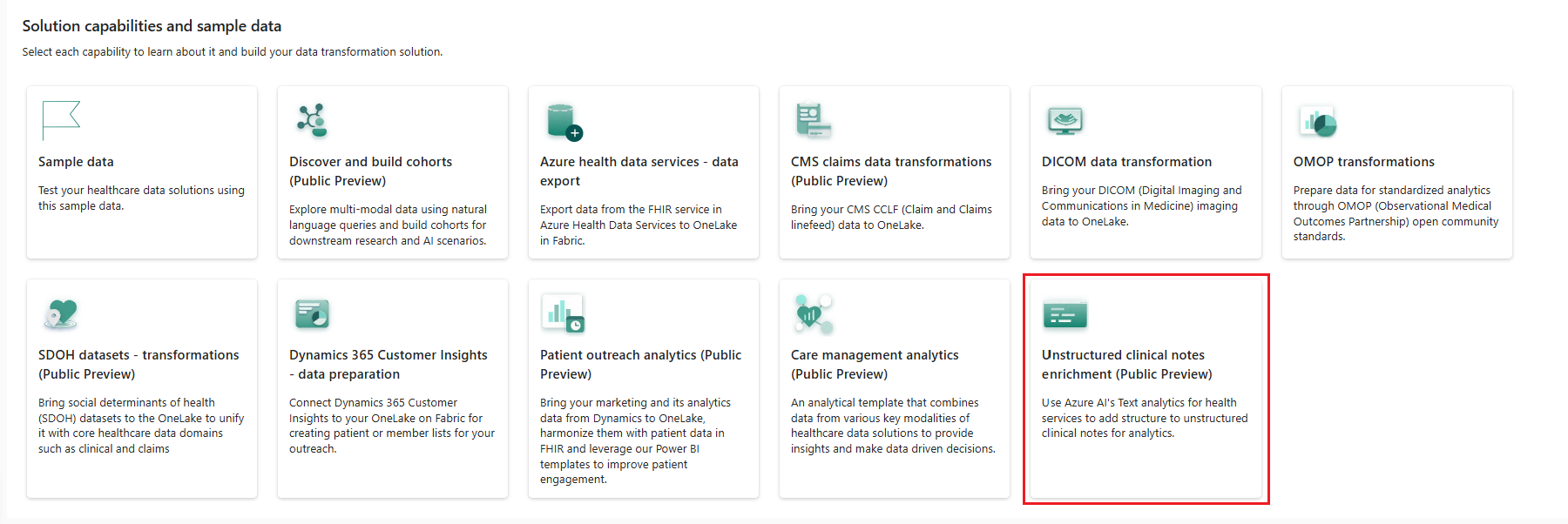
在“功能”页面上,选择部署到工作区。

完成部署可能需要几分钟时间。 部署过程中不要关闭选项卡或浏览器。 在等待期间,您可以在另一个选项卡中工作。
部署完成后,您可以在消息栏上看到一条通知。
从消息栏中选择管理功能,以转到功能管理页面。
在这里,您可以查看、配置和管理使用该功能部署的项目。


项目
该功能可在您的医疗保健数据解决方案环境中安装笔记本和数据管道。
| 项目 | 类型 | 描述 |
|---|---|---|
| healthcare#_msft_ta4h_silver_ingestion | 笔记本 | 使用 Azure Text Analytics for Health NLP API 处理和分析非结构化文本数据。 |
| healthcare#_msft_clinical_notes_enrichment | 数据管道 | 按顺序运行一系列笔记本,以从非结构化临床笔记中提取关键快速医疗保健互操作性资源 (FHIR) 实体,构建数据,并将结果存储在银牌湖屋中。 |
查看笔记本配置
healthcare#_msft_ta4h_silver_ingestion 笔记本运行医疗保健数据解决方案库中的 NLPIngestionService 模块,并使用 Azure Text Analytics for Health 服务。 此服务是一种自然语言处理 (NLP) API,用于处理和分析非结构化文本数据。 结果存储在 healthcare#_msft_silver 湖屋中。
以下是此笔记本的关键配置参数:
NLP Config:允许您自定义 NLP 设置以符合特定的用户要求。
此笔记本使用运行关联的数据管道所需的预配置值进行部署。 某些配置参数继承自全局配置。 默认情况下,您不需要对笔记本配置文件进行任何更改。 如果需要,可以打开笔记本并查看配置。