Lakehouse 教程:在湖屋中准备和转换数据
在本教程中,将笔记本与 Spark 运行时配合使用来转换和准备湖屋中的原始数据。
先决条件
如果没有包含数据的湖屋,则必须:
准备数据
在前面的教程步骤中,我们已将原始数据从源引入湖屋的“文件”部分。 现在可以转换该数据,并为创建 Delta 表做好准备。
从 Lakehouse 教程源代码 文件夹下载笔记本。
在屏幕左下角的切换器中,选择“数据工程”。

从登陆页面顶部的“新建”部分选择“导入笔记本”。
从屏幕右侧打开的“导入状态”窗格中选择“上传”。
选择在本部分的第一步中下载的所有笔记本。
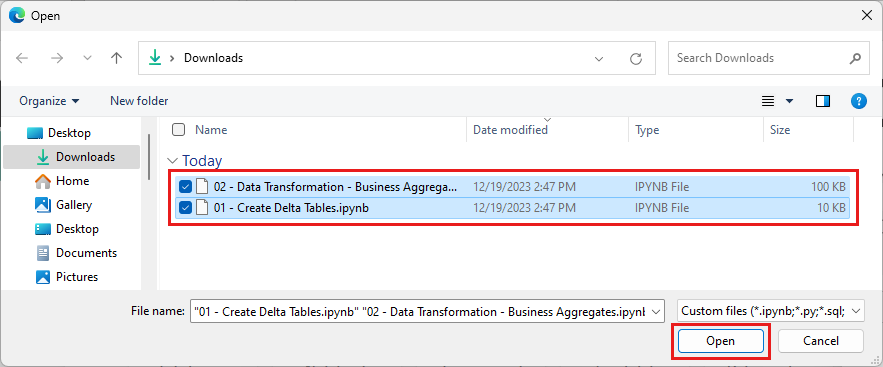
选择打开。 浏览器窗口右上角会显示一条指示导入状态的通知。
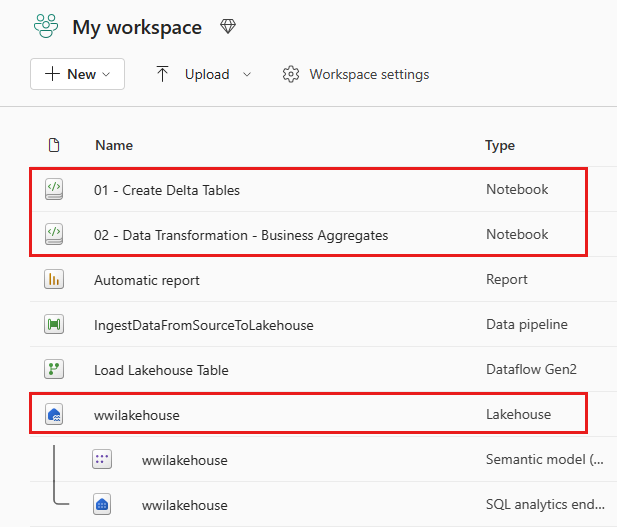
导入成功后,转到工作区的项目视图,查看新导入的笔记本。 选择 wwilakehouse 湖屋将其打开。
打开 wwilakehouse 湖屋后,从顶部导航菜单中选择“打开笔记本>现有笔记本”。
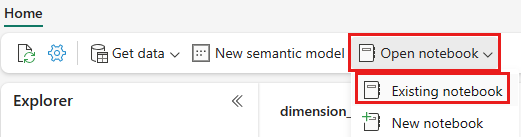
从现有笔记本列表中,选择“01 - 创建 Delta 表”笔记本,然后选择“打开”。
在 Lakehouse 资源管理器的打开笔记本中,可以看到该笔记本已链接到打开的湖屋。
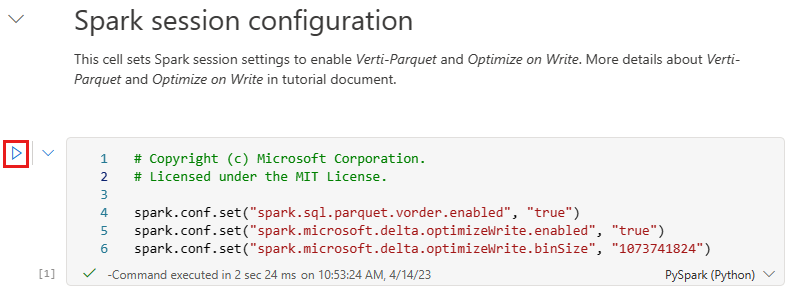
在将数据写入为湖屋的“表”部分中的 Delta 湖表之前,请使用两个 Fabric 功能(V-order 和优化写入)来优化数据写入并提高读取性能。 若要在会话中启用这些功能,请在笔记本的第一个单元格中设置这些配置。
要启动笔记本并依次执行所有单元格,请选择顶部功能区(“主页”下)中的“全部运行”。 或者,若要仅执行特定单元格中的代码,请选择悬停在单元格左侧显示的“运行”图标,或者在控件位于单元格中时按键盘上的 SHIFT + ENTER。
运行单元时,无需指定基础 Spark 池或群集详细信息,因为 Fabric 会通过实时池提供它们。 每个 Fabric 工作区都附带一个名为“实时池”的默认 Spark 池。 这意味着创建笔记本时,无需担心要指定任何 Spark 配置或群集详细信息。 执行第一个笔记本命令时,实时池在几秒钟内即可启动并运行。 且 Spark 会话已建立,并开始执行代码。 当 Spark 会话处于活动状态时,此笔记本中的后续代码执行几乎是即时的。
接下来,从湖屋的“文件”部分读取原始数据,并在转换过程中为不同日期部分添加更多列。 最后,使用 Partition By Spark API 将数据分区,然后根据新创建的数据部件列(“年”和“季度”)将其写入为 Delta 表。
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)加载事实数据表后,可以继续加载其余维度的数据。 以下单元格创建一个函数,用于从湖屋的“文件”部分读取作为参数传递的每个表名称的原始数据。 接下来,它将创建维度表的列表。 最后,它会循环访问表列表,并为从输入参数读取的每个表名称创建一个 Delta 表。 请注意,在此示例中,脚本将删除名为
Photo的列,因为未使用该列。from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)要验证创建的表,请在 wwilakehouse 湖屋上右键单击并选择“刷新”。 将显示这些表。
再次转到工作区的项目视图,然后选择 wwilakehouse 湖屋将其打开。
现在,打开第二个笔记本。 在湖屋视图中,从功能区中选择“打开笔记本>现有笔记本”。
从现有笔记本列表中,选择 02 - 数据转换 - 业务 笔记本以将其打开。
在 Lakehouse 资源管理器的打开笔记本中,可以看到该笔记本已链接到打开的湖屋。
组织可能有使用 Scala/Python 的数据工程师和其他数据工程师使用 SQL(Spark SQL 或 T-SQL),所有这些人员都处理相同的数据副本。 Fabric 使这些具有不同经验和偏好的不同组能够工作和协作。 这两种不同的方法可转换和生成业务聚合。 可以选择适合自己的方法,也可以根据自己的偏好混合和匹配这些方法,而不会影响性能:
方法 #1 - 使用 PySpark 联接和聚合数据以生成业务聚合。 此方法对于具有编程(Python 或 PySpark)背景的人更可取。
方法 #2 - 使用 Spark SQL 联接和聚合数据以生成业务聚合。 这种方法对具有 SQL 背景并在向 Spark 过渡的人更可取。
方法 #1 (sale_by_date_city) - 使用 PySpark 联接和聚合数据以生成业务聚合。 使用以下代码创建三个不同的 Spark 数据帧,每个数据帧引用一个现有的 Delta 表。 然后,使用数据帧联接这些表,按分组生成聚合,重命名一些列,最后将其写入湖屋的“表”部分中的 Delta 表,以便与数据保持一致。
在此单元格中,将创建三个不同的 Spark 数据帧,每个数据帧引用一个现有的 Delta 表。
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")将以下代码添加到同一单元格,以使用之前创建的数据帧联接这些表。 按分组生成聚合,重命名一些列,最后将其作为 Delta 表写入湖屋的“表”部分。
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")方法 #2 (sale_by_date_employee) - 使用 Spark SQL 联接和聚合数据以生成业务聚合。 使用以下代码,通过联接三个表来创建临时 Spark 视图,通过执行分组来生成聚合,并重命名一些列。 最后,从临时 Spark 视图进行读取,最后将其作为 Delta 表写入湖屋的“表”部分,以保留数据。
在此单元格中,通过联接三个表来创建临时 Spark 视图,通过执行分组来生成聚合,并重命名一些列。
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASC在此单元格中,从上一个单元格中创建的临时 Spark 视图进行读取,最后将其写入湖屋的“表”部分中的 Delta 表。
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")要验证创建的表,请在 wwilakehouse 湖屋上右键单击并选择“刷新”。 将显示聚合表。
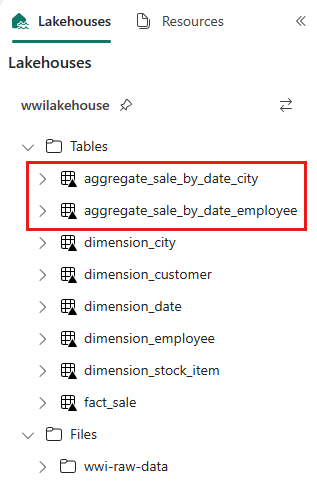
这两种方法会产生类似的结果。 要最大程度地减少学习新技术或在性能上妥协的需要,选择最适合你的背景和偏好的方法。
你可能会注意到,你正在将数据作为 Delta 湖文件写入。 Fabric 的自动表发现和注册功能会选取它们并将其注册到元存储中。 无需显式调用 CREATE TABLE 语句即可创建要与 SQL 一起使用的表。