Fabric 中的 Apache Spark 运行时
Microsoft Fabric 运行时是基于 Apache Spark 的 Azure 集成平台,可实现数据工程和数据科学体验的执行和管理。 它结合了来自内部源和开源源的关键组件,为客户提供全面的解决方案。 为简单起见,我们将 Apache Spark 支持的 Microsoft Fabric 运行时称为 Fabric 运行时。
Fabric 运行时的主要组件:
Apache Spark - 一个功能强大的开源分布式计算库,可实现大规模数据处理和分析任务。 Apache Spark 为数据工程和数据科学体验提供了通用且高性能的平台。
Delta Lake - 一个开源存储层,可将 ACID 事务和其他数据可靠性功能引入 Apache Spark。 Delta Lake 集成在 Microsoft Fabric 运行时中,增强了数据处理功能,并确保跨多个并发操作的数据一致性。
本机执行引擎 - 是 Apache Spark 工作负载的转换性增强功能,通过直接在 lakehouse 基础结构上执行 Spark 查询来提供显著的性能提升。 无缝集成,无需更改代码,并避免供应商锁定,在运行时 1.3 (Spark 3.5) 中跨 Apache Spark API 支持 Parquet 和 Delta 格式。 此引擎可提升查询速度,速度比传统 OSS Spark 快四倍,如 TPC-DS 1TB 基准所示,降低了运营成本,提高了各种数据任务(包括数据引入、ETL、分析和交互式查询)的效率。 它基于 Meta 的 Velox 和 Intel 的 Apache Gluten 构建,可优化资源使用,同时处理各种数据处理方案。
适用于 Java/Scala、Python 和 R 的默认级别包,支持不同的编程语言和环境。 这些包会自动安装和配置,使开发人员能够应用其首选编程语言来处理数据处理任务。
Microsoft Fabric Runtime 基于可靠的开源操作系统构建,可确保与各种硬件配置和系统要求兼容。
下面将全面比较关键组件,包括 Apache Spark 版本、支持的操作系统、Java、Scala、Python、Delta Lake 和 R,适用于 Microsoft Fabric 平台中基于 Apache Spark 的运行时。
| Runtime 1.1 | Runtime 1.2 | 运行时 1.3 | |
|---|---|---|---|
| 发布阶段 | EOSA | GA | GA |
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| 操作系统 | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
访问 Runtime 1.1、Runtime 1.2 或 Runtime 1.3,了解特定运行时版本的详细信息、新功能、改进和迁移方案。
Fabric 优化
在 Microsoft Fabric 中,Spark 引擎和 Delta Lake 实现都包含特定于平台的优化和功能。 这些功能旨在使用平台内的本机集成。 请务必注意,这些功能全部可以禁用,以实现标准的 Spark 和 Delta Lake 功能。 Apache Spark 的 Fabric 运行时包括:
- 完整的 Apache Spark 开源版本。
- 包含近 100 个不同的内置查询性能增强。 这些增强包括分区缓存(启用文件系统分区缓存以减少元存储调用)和交叉联接到标量子查询投影等功能。
- 内置的智能缓存。
在 Apache Spark 和 Delta Lake 的 Fabric 运行时中,本机编写器功能有两个关键用途:
- 它们为写入工作负载提供不同的性能,从而优化写入过程。
- 它们默认为 Delta Parquet 文件的 V 顺序优化。 为了在所有 Fabric 引擎中提供卓越的读取性能,Delta Lake V 顺序优化至关重要。 若要深入了解其操作方式和管理方式,请参阅有关 Delta Lake 表优化和 V 顺序的专题文章。
多个运行时支持
Fabric 支持多个运行时,使用户能够灵活地在它们之间无缝切换,最大限度地减少不兼容或中断的风险。
默认情况下,所有新工作区都使用最新的运行时版本,当前为运行时 1.3。
若要在工作区级别更改运行时版本,请转到“工作区设置”>“数据工程/科学”>“Spark 设置”。 在“环境”选项卡中,从可用选项中选择所需的运行时版本。 单击“保存”以确认您的选择。
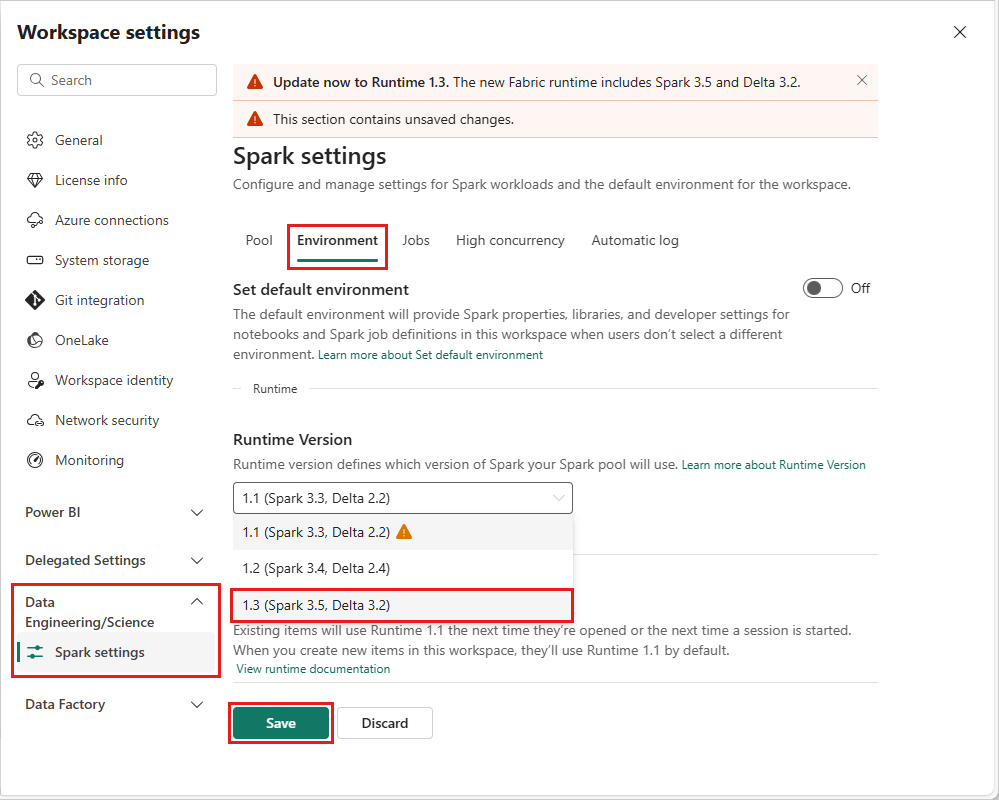
进行此更改后,从下一个 Spark 会话开始,工作区中的所有系统创建项(包括湖屋、SJD 和 Notebook)都将使用新选择的工作区级运行时版本运行。 如果你正在使用已有会话的笔记本进行作业或任何与湖屋相关的活动,则 Spark 会话会按原样继续。 但是,从下一个会话或作业开始,将应用所选的运行时版本。
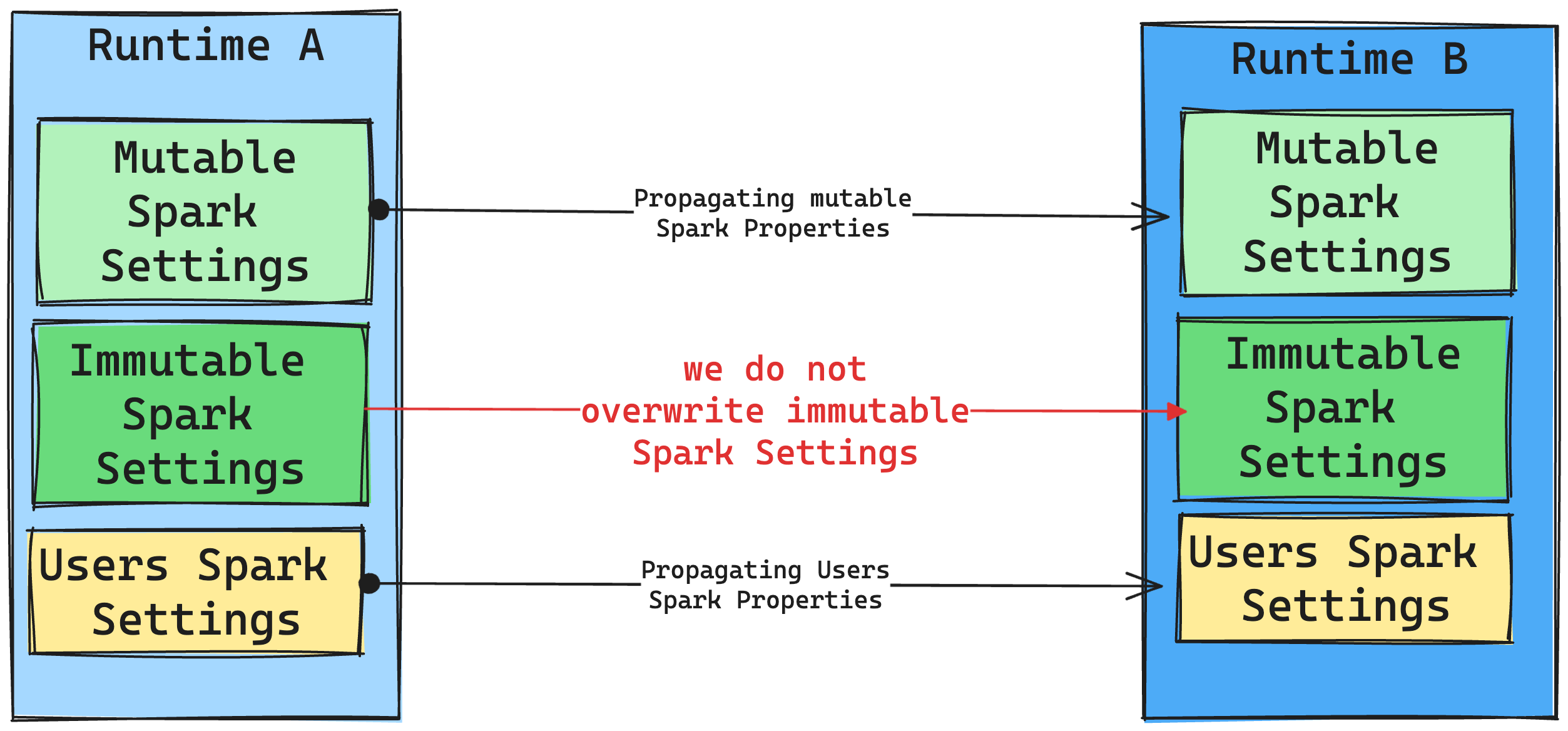
运行时更改对 Spark 设置的影响
一般而言,我们的目标是迁移所有 Spark 设置。 但是,如果我们确定 Spark 设置与运行时 B 不兼容,我们将发出警告消息,并避免实施该设置。
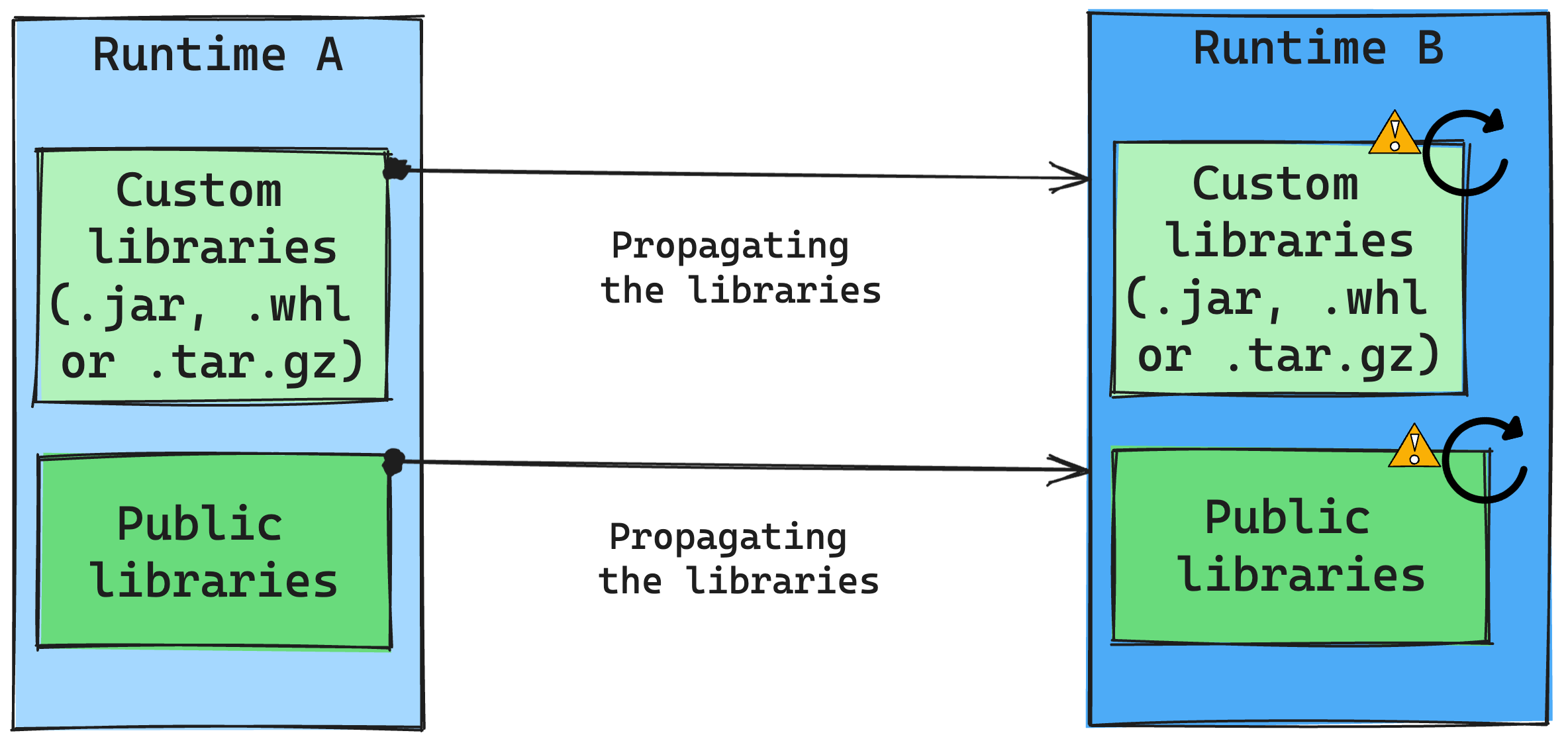
运行时更改对库管理的影响
通常,我们的方法是将所有库从运行时 A 迁移到运行时 B,包括公共运行时和自定义运行时。 如果 Python 和 R 版本保持不变,则库应正常运行。 但是,对于 Jars 而言,由于依赖项的更改以及 Scala、Java、Spark 和操作系统中的更改等其他因素,它们可能无法正常工作。
用户负责更新或替换任何不适用于运行时 B 的库。如果存在冲突,这意味着运行时 B 包含最初在运行时 A 中定义的库,我们的库管理系统将尝试根据用户的设置为运行时 B 创建必要的依赖项。 但如果发生冲突,生成过程将失败。 在错误日志中,用户可以查看导致冲突的库,并调整其版本或规范。
升级 Delta Lake 协议
Delta Lake 功能始终向后兼容,确保在较低的 Delta Lake 版本中创建的表可以与更高版本无缝交互。 但是,启用某些功能时(例如,通过使用 delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) 方法,与较低 Delta Lake 版本的向前兼容性可能会受到影响。 在这种情况下,必须修改引用升级表的工作负载,以便与保持兼容性的 Delta Lake 版本保持一致。
每个 Delta 表都与协议规范相关联,定义其支持的功能。 与表交互的应用程序(无论是用于读取或写入)依赖此协议规范来确定它们是否与表的功能集兼容。 如果应用程序无法处理表协议中列举为支持的功能,则无法读取或写入该表。
协议规范由两个部分组成:读取协议和写入协议。 请访问页面“Delta Lake 如何管理功能兼容性?”,阅读相关详细信息。

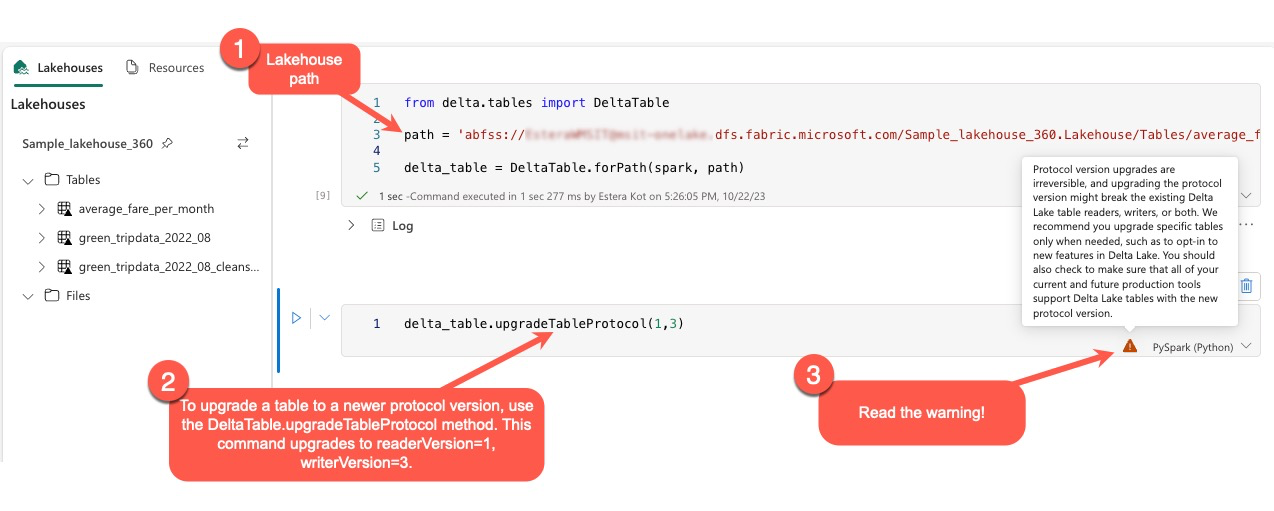
用户可以在 PySpark 环境中以及 Spark SQL 和 Scala 中执行命令 delta.upgradeTableProtocol(minReaderVersion, minWriterVersion)。 此命令允许他们启动 Delta 表的更新。
请务必注意,在执行此升级时,用户会收到一条警告,提示升级 Delta 协议版本的过程不可逆。 这意味着一旦执行更新,就无法撤消。
协议版本升级可能会影响现有 Delta Lake 表读取器、编写器或二者的兼容性。 因此建议谨慎行事,仅在必要时(例如在 Delta Lake 中采用新功能时)升级协议版本。
此外,用户还应验证所有当前和将来的生产工作负载和进程是否与使用新协议版本的 Delta Lake 表兼容,以确保无缝转换并防止任何潜在的中断。
Delta 2.2 与 Delta 2.4 更改
在最新的 Fabric Runtime,版本 1.3 和 Fabric Runtime 版本 1.2 中,默认表格式 (spark.sql.sources.default) 现在为 delta。 在之前版本的 Fabric 运行时版本 1.1 和所有包含 Spark 3.3 或更低版本的 Synapse Runtime for Apache Spark 中,默认的表格式定义为 parquet。 检查包含 Apache Spark 配置详细信息的表,了解 Azure Synapse Analytics 与 Microsoft Fabric 之间的差异。
每当表类型被省略时,使用 Spark SQL、PySpark、Scala Spark 和 Spark R 创建的所有表都会默认将该表创建为 delta。 如果脚本显式设置表格式,则将遵循该格式。 Spark 创建表命令中的命令 USING DELTA 变得冗余。
应修改预期或假定 parquet 表格式的脚本。 Delta 表中不支持以下命令:
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE