将 Hive 元存储元数据从 Azure Synapse Analytics 迁移到 Fabric
Hive 元存储(HMS) 迁移的第一步涉及到确定要转移的数据库、表和分区。 不必要迁移所有内容;你可以选择特定的数据库。 在确定要迁移的数据库时,请务必验证是否存在托管的或外部的 Spark 表。
有关 HMS 注意事项,请参阅 Azure Synapse Spark 和 Fabric 之间的差异。
注意
或者,如果 ADLS Gen2 包含 Delta 表,则可以在 ADLS Gen2 中创建 Delta 表的 OneLake 快捷方式。
先决条件
- 在租户中创建一个 Fabric 工作区(如果没有)。
- 在工作区中创建一个 Fabric 湖屋(如果没有)。
选项 1:将 HMS 导出和导入到湖屋元存储
按照以下关键步骤进行迁移:
- 步骤 1:从源 HMS 导出元数据
- 步骤 2:将元数据导入 Fabric 湖屋
- 迁移后步骤:验证内容
注意
脚本只会将 Spark 目录对象复制到 Fabric 湖屋。 假设数据已复制到 Fabric 湖屋(例如,已从仓库位置复制到 ADLS Gen2)或可用于托管表和外部表(例如,通过快捷方式 - 首选)。
步骤 1:从源 HMS 导出元数据
步骤 1 的重点是将元数据从源 HMS 导出到 Fabric 湖屋的“文件”部分。 此过程如下所述:
1.1) 将 HMS 元数据导出笔记本导入到 Azure Synapse 工作区。 此笔记本将查询数据库、表和分区的 HMS 元数据并将其导出到 OneLake 中的中间目录(尚不包括函数)。 此脚本使用 Spark 内部目录 API 来读取目录对象。
1.2) 在第一个命令中配置参数,以将元数据信息导出到中间存储 (OneLake)。 以下代码片段用于配置源和目标参数。 请确保将它们替换为你自己的值。
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) 运行所有笔记本命令以将目录对象导出到 OneLake。 单元格完成后,将在中间输出目录下创建此文件夹结构。
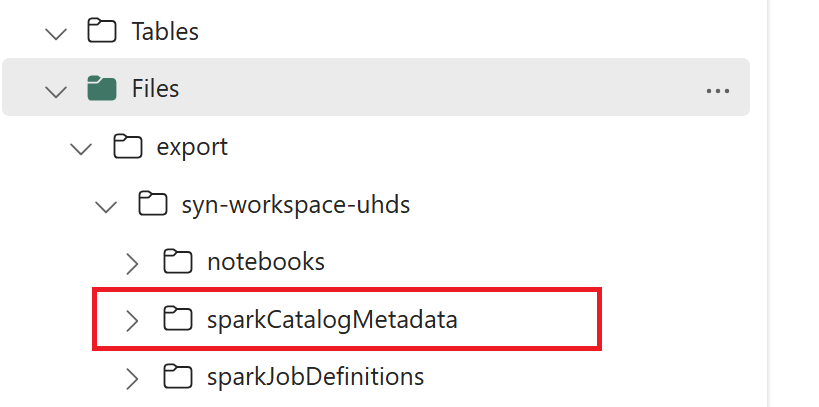
步骤 2:将元数据导入 Fabric 湖屋
步骤 2 将实际元数据从中间存储导入到 Fabric 湖屋中。 此步骤的输出用于迁移所有 HMS 元数据(数据库、表和分区)。 此过程如下所述:
2.1) 在湖屋的“文件”部分中创建快捷方式。 此快捷方式需要指向源 Spark 仓库目录,稍后用于替换 Spark 托管表。 查看指向 Spark 仓库目录的快捷方式示例:
- 指向 Azure Synapse Spark 仓库目录的快捷方式路径:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - 指向 Azure Databricks 仓库目录的快捷方式路径:
dbfs:/mnt/<warehouse_dir> - 指向 HDInsight Spark 仓库目录的快捷方式路径:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- 指向 Azure Synapse Spark 仓库目录的快捷方式路径:
2.2) 将 HMS 元数据导入笔记本导入 Fabric 工作区。 导入此笔记本,以从中间存储导入数据库、表和分区对象。 此脚本使用 Spark 内部目录 API 在 Fabric 中创建目录对象。
2.3) 在第一个命令中配置参数。 在 Apache Spark 中,当你创建托管表时,该表的数据将存储在 Spark 本身管理的位置,通常位于 Spark 的仓库目录中。 确切的位置由 Spark 决定。 这与外部表形成了鲜明对比,在外部表中,你需要指定位置并管理基础数据。 当你迁移托管表的元数据(不移动实际数据)时,元数据仍然包含指向旧 Spark 仓库目录的原始位置信息。 因此,对于托管表,
WarehouseMappings用于通过步骤 2.1 中创建的快捷方式进行替换。 所有源托管表将通过此脚本转换为外部表。LakehouseId引用在步骤 2.1 中创建的包含快捷方式的湖屋。// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) 运行所有笔记本命令以从中间路径导入目录对象。
注意
导入多个数据库时,可以 (i) 为每个数据库创建一个湖屋(此处使用的方法),或 (ii) 将所有表从不同数据库移动到单个湖屋。 对于后一种方法,所有迁移的表可能是 <lakehouse>.<db_name>_<table_name>,并且你需要相应地调整导入笔记本。
步骤 3:验证内容
步骤 3 验证元数据是否已成功迁移。 请查看不同的示例。
可以通过运行以下命令来查看导入的数据库:
%%sql
SHOW DATABASES
可以通过运行以下命令来检查湖屋(数据库)中的所有表:
%%sql
SHOW TABLES IN <lakehouse_name>
可以通过运行以下命令来查看特定表的详细信息:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
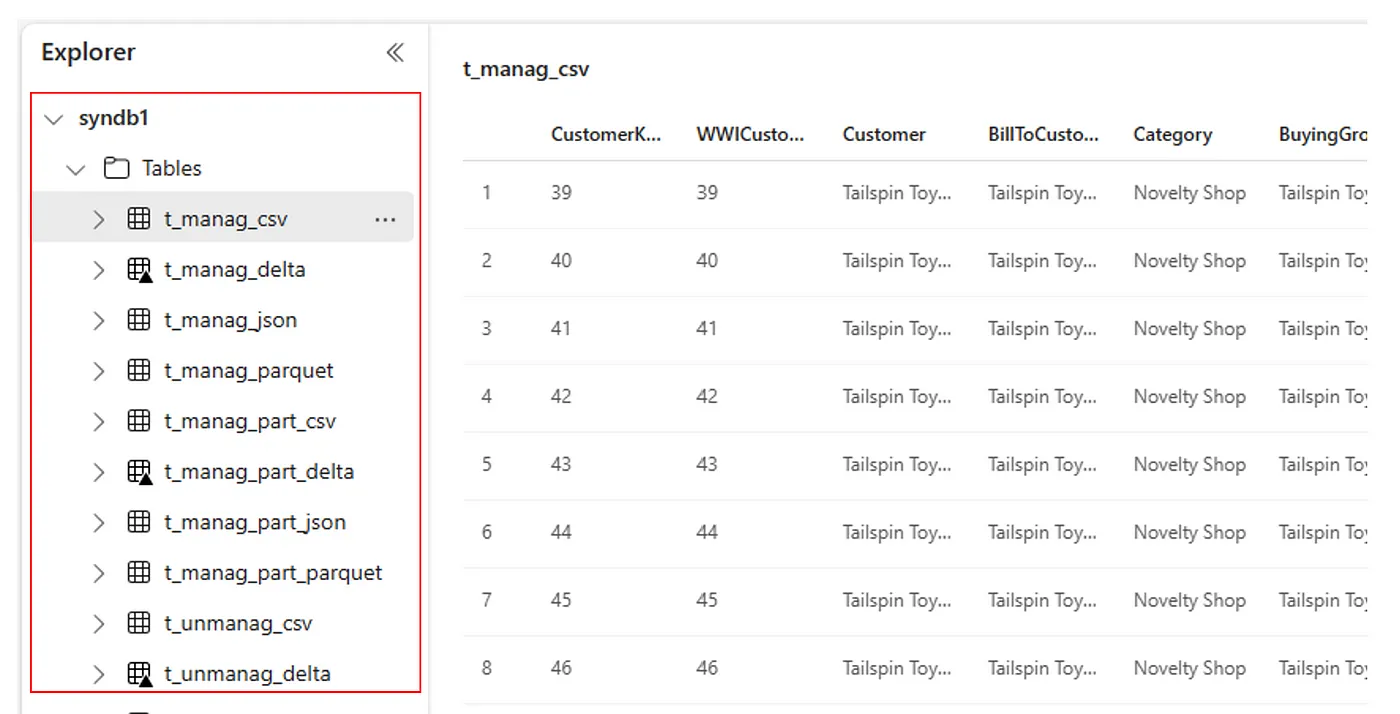
或者,可以在每个湖屋的 Lakehouse 资源管理器 UI 中的“表”部分查看所有导入的表。
其他注意事项
- 可伸缩性:此处的解决方案使用内部 Spark 目录 API 执行导入/导出,但它不是直接连接到 HMS 来获取目录对象,因此如果目录很大,该解决方案不能很好地缩放。 需要使用 HMS DB 更改导出逻辑。
- 数据准确性:不提供隔离保证,这意味着,如果 Spark 计算引擎在迁移笔记本正在运行时对元存储进行并发修改,则可能会在 Fabric 湖屋中造成数据不一致的情况。