将 Spark 作业定义从 Azure Synapse 迁移到 Fabric
若要将 Spark 作业定义 (SJD) 从 Azure Synapse 移动到 Fabric,有两个不同的选项:
- 选项 1:在 Fabric 中手动创建 Spark 作业定义。
- 选项 2:可以使用脚本从 Azure Synapse 导出 Spark 作业定义,然后使用 API 将其导入 Fabric。
有关 Spark 作业定义注意事项,请参阅 Azure Synapse Spark 和 Fabric 之间的差异。
先决条件
在租户中创建一个 Fabric 工作区(如果没有)。
选项 1:手动创建 Spark 作业定义
若要从 Azure Synapse 导出 Spark 作业定义,请执行以下操作:
- 打开 Synapse Studio:登录到 Azure。 导航到你的 Azure Synapse 工作区,打开 Synapse Studio。
- 找到 Python/Scala/R Spark 作业:查找并标识要迁移的 Python/Scala/R Spark 作业定义。
- 导出作业定义配置:
- 在 Synapse Studio 中,打开 Spark 作业定义。
- 导出或记下配置设置,包括脚本文件位置、依赖项、参数以及任何其他相关详细信息。
若要基于 Fabric 中导出的 SJD 信息创建新的 Spark 作业定义 (SJD):
- 访问 Fabric 工作区:登录到 Fabric 并访问你的工作区。
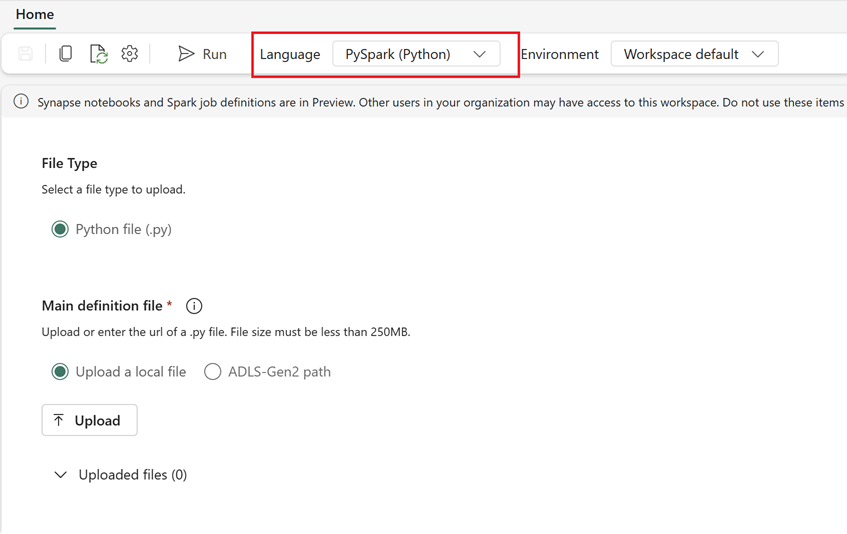
- 在 Fabric 中创建新的 Spark 作业定义:
- 在 Fabric 中,转到“数据工程主页”。
- 选择“Spar 作业定义”。
- 使用从 Synapse 导出的信息配置作业,包括脚本位置、依赖项、参数和群集设置。
- 适应和测试:根据 Fabric 环境对脚本或配置进行任何必要的适应。 在 Fabric 中测试作业,确保作业正常运行。
创建 Spark 作业定义后,验证依赖项:
- 确保使用相同的 Spark 版本。
- 验证主定义文件是否存在。
- 验证引用的文件、依赖项和资源是否存在。
- 链接服务、数据源连接和装入点。
详细了解如何在 Fabric 中创建 Apache Spark 作业定义。
选项 2:使用 Fabric API
按照以下关键步骤进行迁移:
- 先决条件。
- 步骤 1:将 Spark 作业定义从 Azure Synapse 导出到 OneLake (.json)。
- 步骤 2:使用 Fabric API 自动将 Spark 作业定义导入 Fabric。
先决条件
先决条件包括开始将 Spark 作业定义迁移到 Fabric 之前需要考虑的操作。
- 一个 Fabric 工作区。
- 在工作区中创建一个 Fabric 湖屋(如果没有)。
步骤 1:从 Azure Synapse 工作区导出 Spark 作业定义
步骤 1 的重点是以 json 格式将 Spark 作业定义从 Azure Synapse 工作区导出到 OneLake。 此过程如下所述:
- 1.1) 将 SJD 迁移笔记本导入到 Fabric 工作区。 此笔记本将所有 Spark 作业定义从给定的 Azure Synapse 工作区导出到 OneLake 中的中间目录。 Synapse API 用于导出 SJD。
- 1.2) 在第一个命令中配置参数,以将 Spark 作业定义导出到中间存储 (OneLake)。 这只会导出 json 元数据文件。 以下代码片段用于配置源和目标参数。 请确保将它们替换为你自己的值。
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
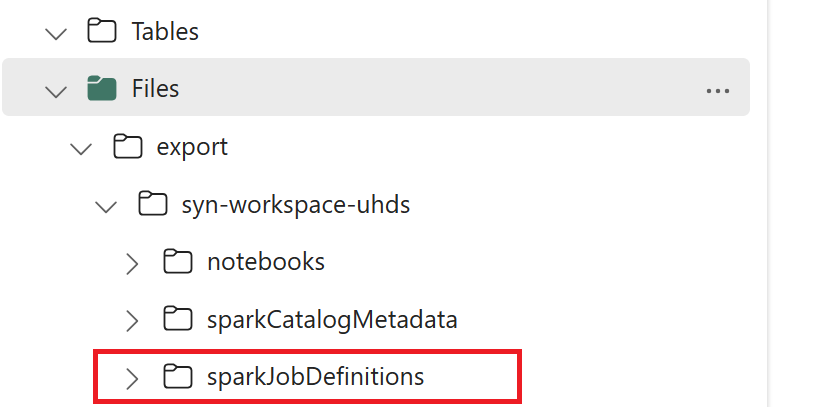
- 1.3) 运行导出/导入笔记本的前两个单元 ,将 Spark 作业定义元数据导出到 OneLake。 单元格完成后,将在中间输出目录下创建此文件夹结构。
步骤 2:将 Spark 作业定义导入 Fabric
步骤 2 将 Spark 作业定义从中间存储导入 Fabric 工作区。 此过程如下所述:
- 2.1) 验证 1.2 中的配置,以确保指示正确的工作区和前缀来导入 Spark 作业定义。
- 2.2) 运行导出/导入笔记本的第三个单元,以从中间位置导入所有笔记本。
注意
导出选项会输出一个 json 元数据文件。 确保可以从 Fabric 访问 Spark 作业定义可执行文件、引用文件和参数。