湖屋参考体系结构(下载)
本文从数据源、引入、转换、查询和处理、服务提供、分析和存储等方面提供了针对湖屋的体系结构指导。
每个参考体系结构都有一个 11 x 17 (A3) 格式的可下载 PDF。
虽然 Databricks 上的湖屋是一个与大型合作伙伴工具生态系统集成的开放平台,但参考体系结构仅关注 Azure 服务和 Databricks 湖屋。 显示的云提供商服务是为说明这些概念而选取的,并未详尽地涵盖所有服务。
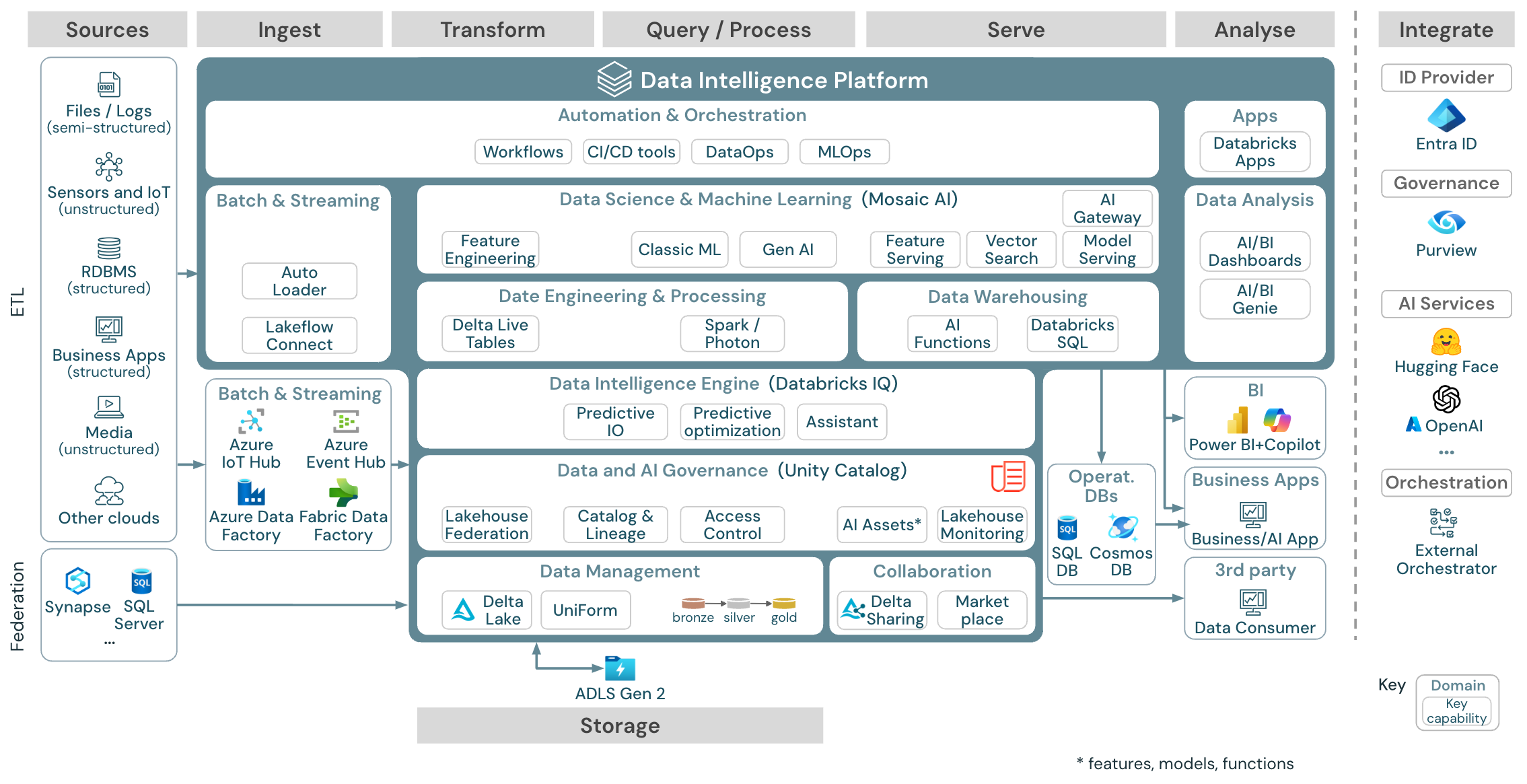
Azure 参考体系结构显示了以下针对引入、存储、服务提供以及分析的 Azure 特定服务:
- Azure Synapse 和 SQL Server,用作 Lakehouse Federation 的源系统
- Azure IoT 中心和 Azure 事件中心,用于流式处理引入
- Azure 数据工厂,用于批量引入
- Azure Data Lake Storage Gen 2 (ADLS),用作对象存储
- Azure SQL DB 和 Azure Cosmos DB,用作操作数据库
- Azure Purview,用作企业目录,UC 会将架构和世系信息导出到该目录中
- Power BI,用作 BI 工具
参考体系结构的组织
参考体系结构是沿以下“泳道”构造的:数据源、引入、转换、查询/处理、服务提供、分析和存储:
Source
该体系结构区分了半结构化和非结构化数据(传感器和物联网、媒体、文件/日志)以及结构化数据(RDBMS、业务应用程序)。 SQL 源 (RDBMS) 还可以通过湖屋联合集成到湖屋和 Unity Catalog 中,无需进行 ETL。 此外,还可能会从其他云提供商加载数据。
引入
可以通过批处理或流式处理将数据引入到湖屋中:
- Databricks LakeFlow Connect 提供了内置连接器,用于从企业应用程序和数据库进行数据导入。 最终的引入管道由 Unity Catalog 管理,并由无服务器计算和增量实时表提供支持。
- 可以使用 Databricks 自动加载程序直接加载传送到云存储的文件。
- 为了将企业应用程序中的数据批量引入到 Delta Lake,Databricks lakehouse 依赖于合作伙伴引入工具(其中提供了适用于这些记录系统的特定适配器)。
- 可以使用 Databricks 结构化流式处理直接从事件流式处理系统(例如 Kafka)引入流式处理事件。 流式处理源可以是传感器、物联网或变更数据捕获流程。
存储
数据通常存储在云存储系统中,其中的 ETL 管道使用奖章体系结构以精心策划的方式将数据存储为 Delta 文件/表。
“转换”与“查询/处理”
Databricks 湖屋使用其引擎 Apache Spark 和 Photon 执行所有转换和查询。
DLT(增量实时表)是一个声明性框架,用于简化和优化可靠、可维护且可测试的数据处理管道。
Databricks Data Intelligence Platform 由 Apache Spark 和 Photon 提供支持,支持两种类型的工作负载:通过 SQL 仓库的 SQL 查询,以及通过工作区群集的 SQL、Python 和 Scala 工作负载。
对于数据科学(ML 建模和生成式 AI),Databricks AI 和机器学习平台 提供了专门用于 AutoML 和为 ML 作业编写代码的 ML 运行时。 所有数据科学和 MLOps 工作流都得到 MLflow 的最佳支持。
服务提供
对于 DWH 和 BI 用例,Databricks 湖屋提供了 Databricks SQL,它是由 SQL 仓库和无服务器 SQL 仓库提供支持的数据仓库。
对于机器学习,模型服务是一种可缩放的实时企业级模型服务功能,托管在 Databricks 控制平面中。 马赛克 AI 网关 是 Databricks 解决方案,用于管理和监视对支持的生成 AI 模型及其关联的模型服务终结点的访问。
操作数据库:外部系统(例如操作数据库)可用于存储最终数据产品并将其交付给用户应用程序。
协作:业务合作伙伴通过 Delta Sharing 安全地访问所需的数据。 Databricks 市场是一个基于 Delta Sharing 来交换数据产品的开放论坛。
分析
最终的业务应用程序位于此泳道。 示例包括自定义客户端,例如连接到 Mosaic AI 模型服务进行实时推理的 AI 应用程序,或访问从湖屋推送到操作数据库的数据的应用程序。
对于 BI 用例,分析师通常使用 BI 工具访问数据仓库。 SQL 开发人员还可以使用 Databricks SQL 编辑器(示意图中未显示)进行查询和仪表板构建。
Data Intelligence Platform 还提供了仪表板来构建数据可视化效果并共享见解。
集成
Databricks 平台与标准标识提供者集成,用于用户管理和单一登录 (SSO)。
外部 AI 服务(如 OpenAI、LangChain 或 HuggingFace)可直接在 Databricks Intelligence Platform 内使用。
外部业务流程协调程序可以使用全面的 REST API 或专用连接器连接到外部业务流程工具,例如 Apache Airflow。
Unity Catalog 用于 Databricks 智能平台中的所有数据和 AI 治理,并且可以通过 Lakehouse Federation 将其他数据库集成到其治理中。
此外,Unity Catalog 可以集成到其他企业目录中,例如 Purview。 有关详细信息,请联系企业目录供应商。
所有工作负载的常见功能
此外,Databricks 湖屋还提供了支持所有工作负载的管理功能:
数据和 AI 治理
Databricks Data Intelligence Platform 中的中央数据和 AI 治理系统是 Unity Catalog。 Unity Catalog 提供了单一位置来管理适用于所有工作空间的数据访问策略,并支持在湖屋中创建或使用的所有资产,例如表、卷、功能(功能存储)和模型(模型注册表)。 Unity Catalog 还可以用来为 Databricks 上运行的查询捕获运行时数据世系。
使用 Databricks 湖屋监视,可以监视你的帐户中所有表的数据质量。 它还可以跟踪机器学习模型和模型服务终结点的性能。
系统表是帐户操作数据的 Azure Databricks 托管的分析存储,这是为了实现可观测性。 系统表可用于跨帐户观测历史记录。
数据智能引擎
Databricks Data Intelligence Platform 允许你的整个组织使用数据和 AI。 它由 DatabricksIQ 提供支持,并将生成式 AI 与湖屋的统一优势结合使用来理解数据的独特语义。
Databricks 助手是一个面向开发人员的上下文感知 AI 助手,可在 Databricks 笔记本、SQL 编辑器和文件编辑器中使用。
自动化和业务流程
Databricks 作业可协调 Databricks Data Intelligence 平台中的数据处理、机器学习和分析管道。 使用增量实时表,可以使用声明性语法生成可靠且可维护的 ETL 管道。 该平台还支持 CI/CD 和 MLOps
Azure 上 Data Intelligence 平台的高级用例
Databricks LakeFlow Connect 提供内置连接器用于从企业应用程序和数据库引入数据。 最终的引入管道由 Unity Catalog 管理,并由无服务器计算和增量实时表提供支持。 LakeFlow Connect 利用高效的增量读写来使数据引入变得更快、更具可伸缩性、更具经济效益,同时使数据保持新鲜以供下游使用。
用例:使用 Lakeflow Connect 引入数据:
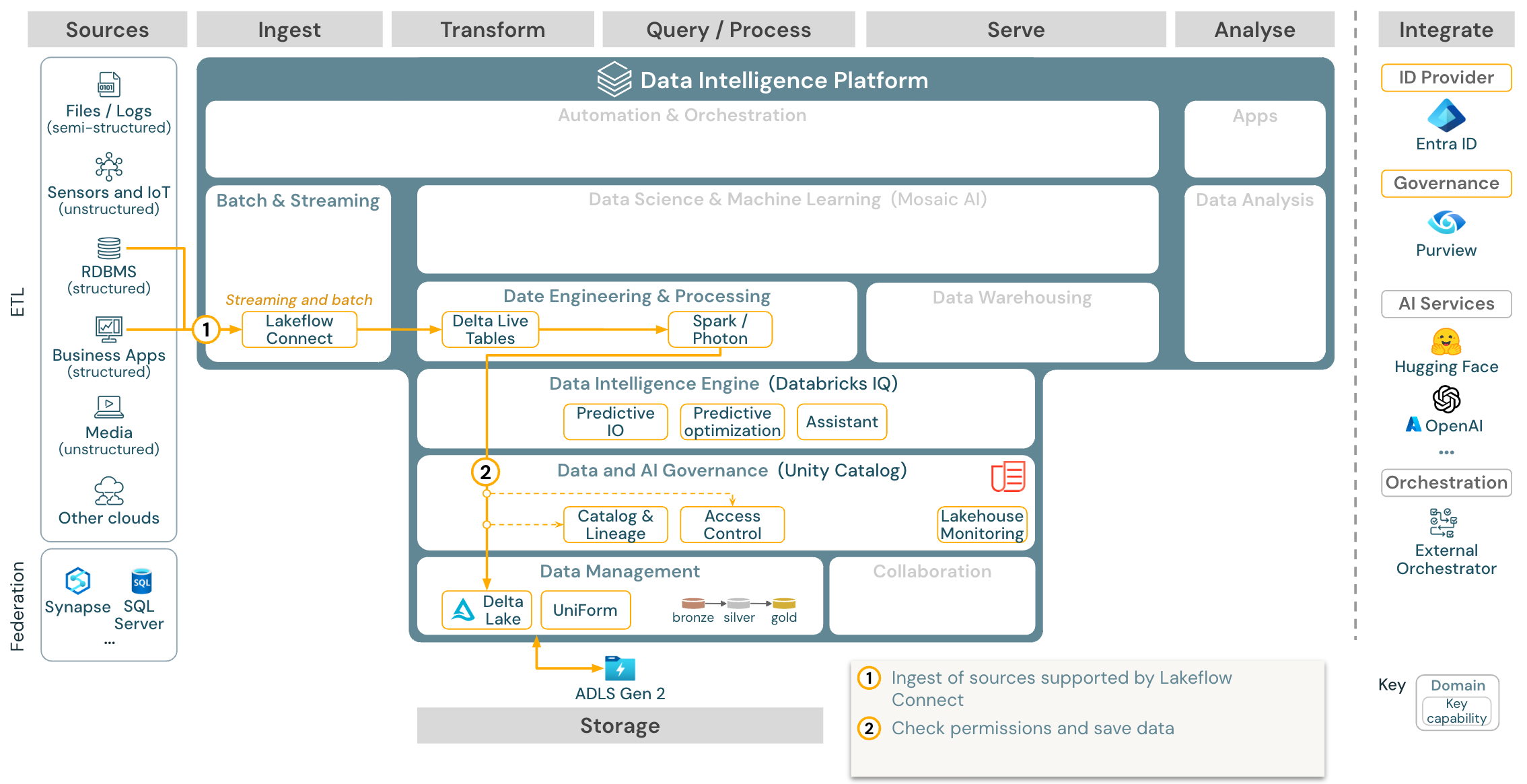
下载:Azure Databricks 的批处理 ETL 参考体系结构。
用例:批量 ETL
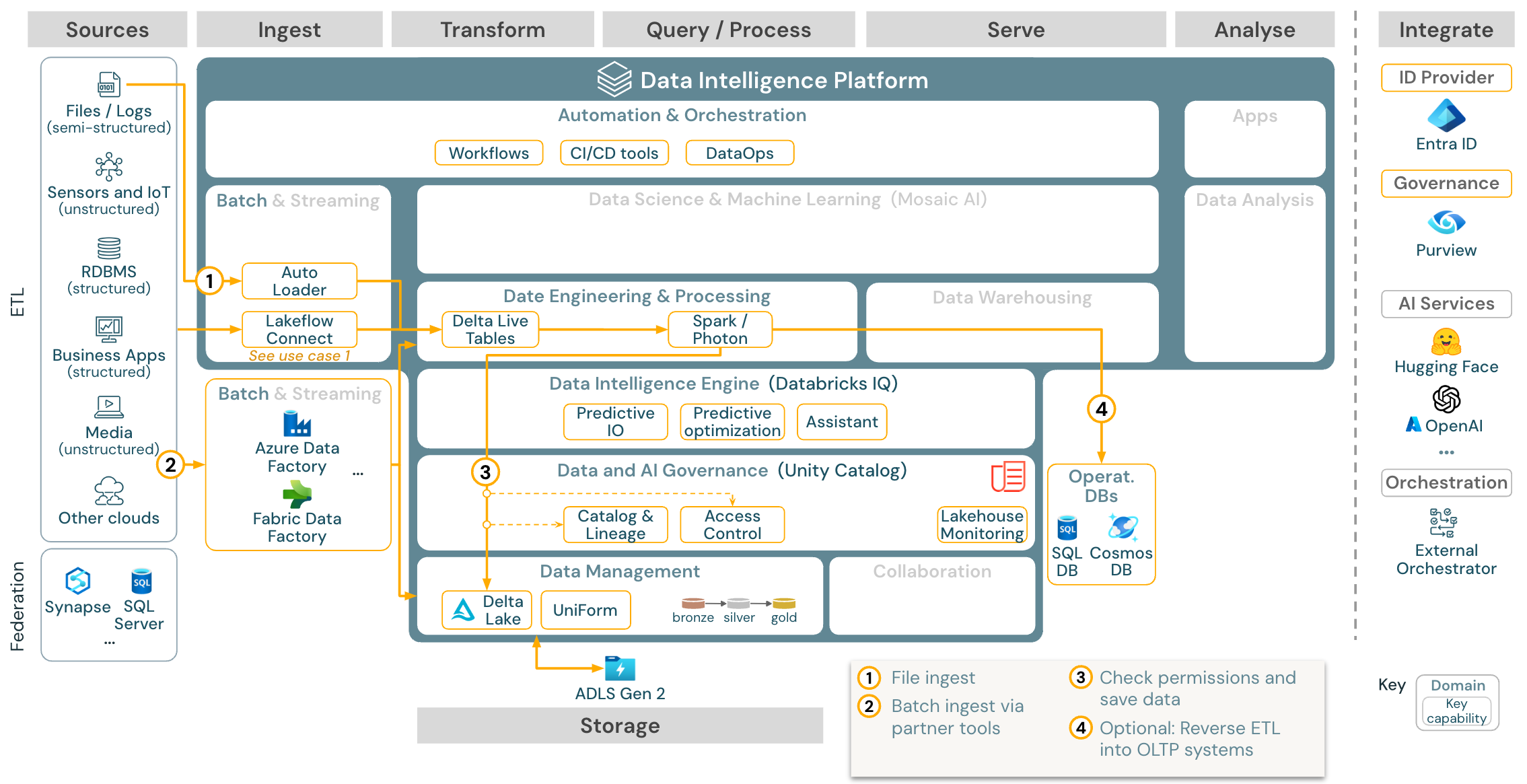
下载:适用于 Azure Databricks 的批量 ETL 参考体系结构
引入工具使用特定于源的适配器从源读取数据,然后将其存储在云存储中(自动加载程序可以从中读取数据),或直接调用 Databricks(例如,通过集成到 Databricks 湖屋中的合作伙伴引入工具)。 为了加载数据,Databricks ETL 和处理引擎将通过 DLT 运行查询。 单任务或多任务工作流可以由 Databricks 作业编排,并由 Unity Catalog 进行治理(访问控制、审计、世系,等等)。 如果低延迟操作系统需要访问特定的黄金表,则可以在 ETL 管道的末尾将这些表导出到某个操作数据库,例如 RDBMS 或键-值存储。
用例:流式处理和变更数据捕获 (CDC)
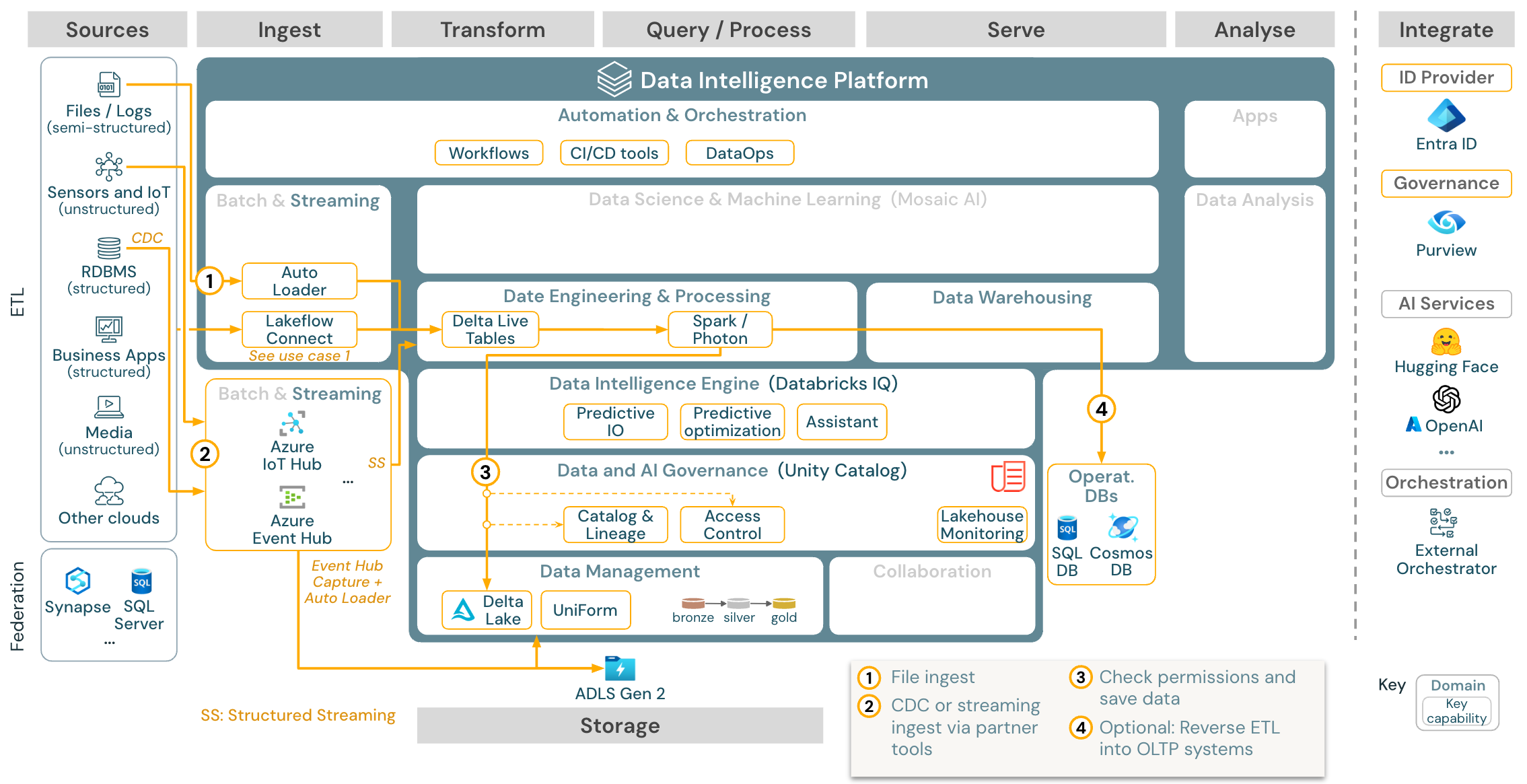
下载:适用于 Azure Databricks 的 Spark 结构化流式处理体系结构
Databricks ETL 引擎使用 Spark 结构化流式处理从事件队列(例如 Apache Kafka 或 Azure 事件中心)读取数据。 下游步骤遵循上面的“批量”用例的方法。
实时变更数据捕获 (CDC) 通常使用事件队列来存储提取的事件。 在那里,此用例遵循流式处理用例。
如果 CDC 是批量完成的,在这种情况下提取的记录首先存储在云存储中,然后 Databricks 自动加载程序可以读取它们,并且此用例遵循批量 ETL。
用例:机器学习和 AI
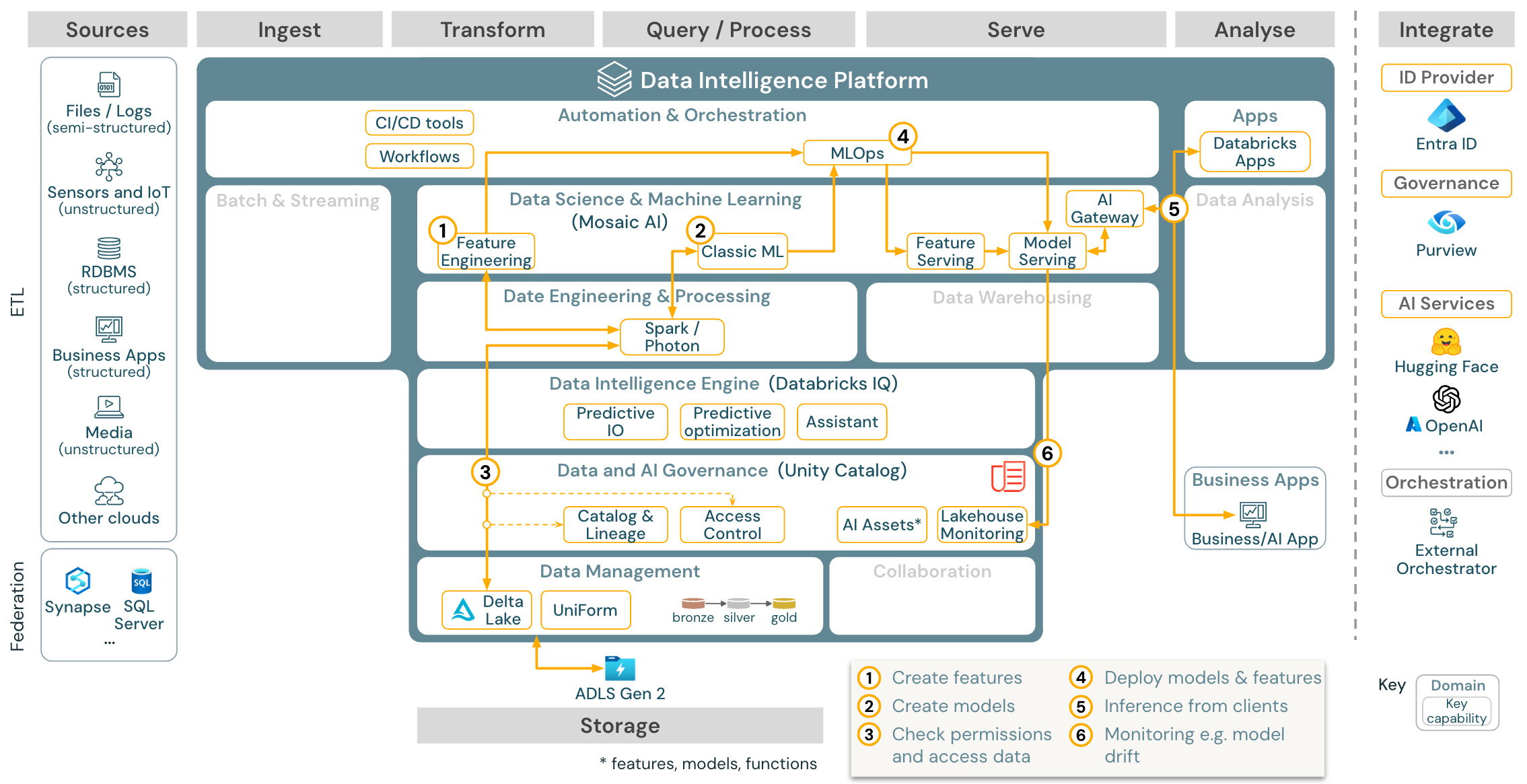
下载:适用于 Azure Databricks 的机器学习和 AI 参考体系结构
对于机器学习,Databricks Data Intelligence Platform 提供了 Mosaic AI,后者配备了最先进的机器和深度学习库。 它提供下述功能:“特征存储”和模型注册表(两者都已集成到 Unity Catalog 中)、采用 AutoML 的低代码功能,以及集成到数据科学生命周期的 MLflow。
所有与数据科学相关的资产(表、特征和模型)都由 Unity Catalog 治理,数据科学家可以使用 Databricks 作业来协调其作业。
为了以可缩放的企业级方式部署模型,请使用 MLOps 功能在模型服务中发布模型。
实例:生成式人工智能(Gen AI)代理应用程序
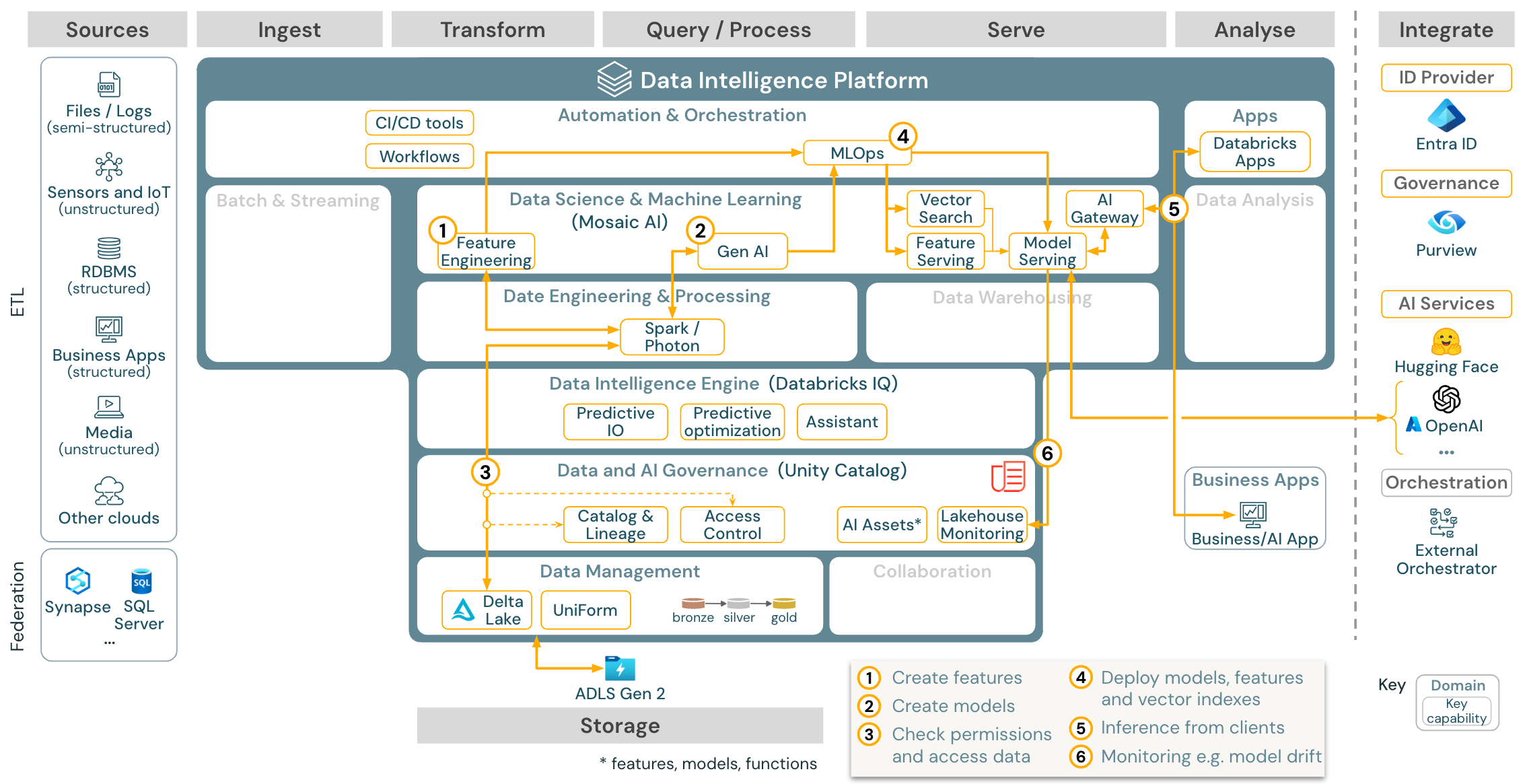
下载:适用于 Azure Databricks 的 Gen AI 应用程序参考体系结构
对于生成式 AI 用例,Mosaic AI 配备了最先进的库和特定的生成式 AI 功能,包括提示工程、对现有模型的微调,以及从头开始预训练。 上述体系结构演示了如何使用 RAG(检索扩充生成)集成矢量搜索来创建 gen AI 应用程序的示例。
为了以可缩放的企业级方式部署模型,请使用 MLOps 功能在模型服务中发布模型。
用例:BI 和 SQL 分析
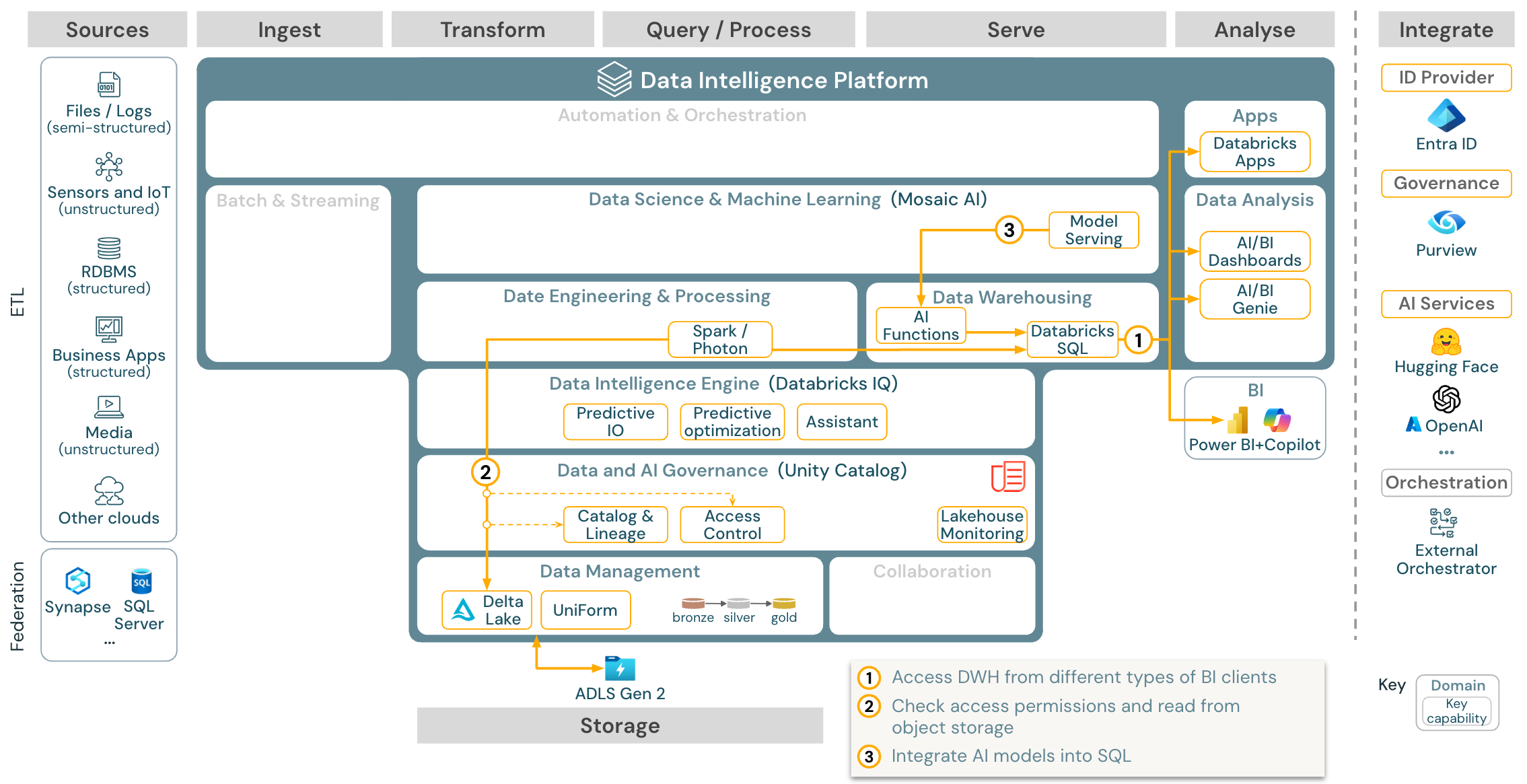
下载:适用于 Azure Databricks 的 BI 和 SQL 分析参考体系结构
对于 BI 用例,业务分析师可以使用仪表板、Databricks SQL 编辑器或特定的 BI 工具,例如 Tableau 或 Power BI。 在所有情况下,引擎都是 Databricks SQL(无服务器或非无服务器),数据发现、探索和访问控制由 Unity Catalog 提供。
用例:湖屋联合
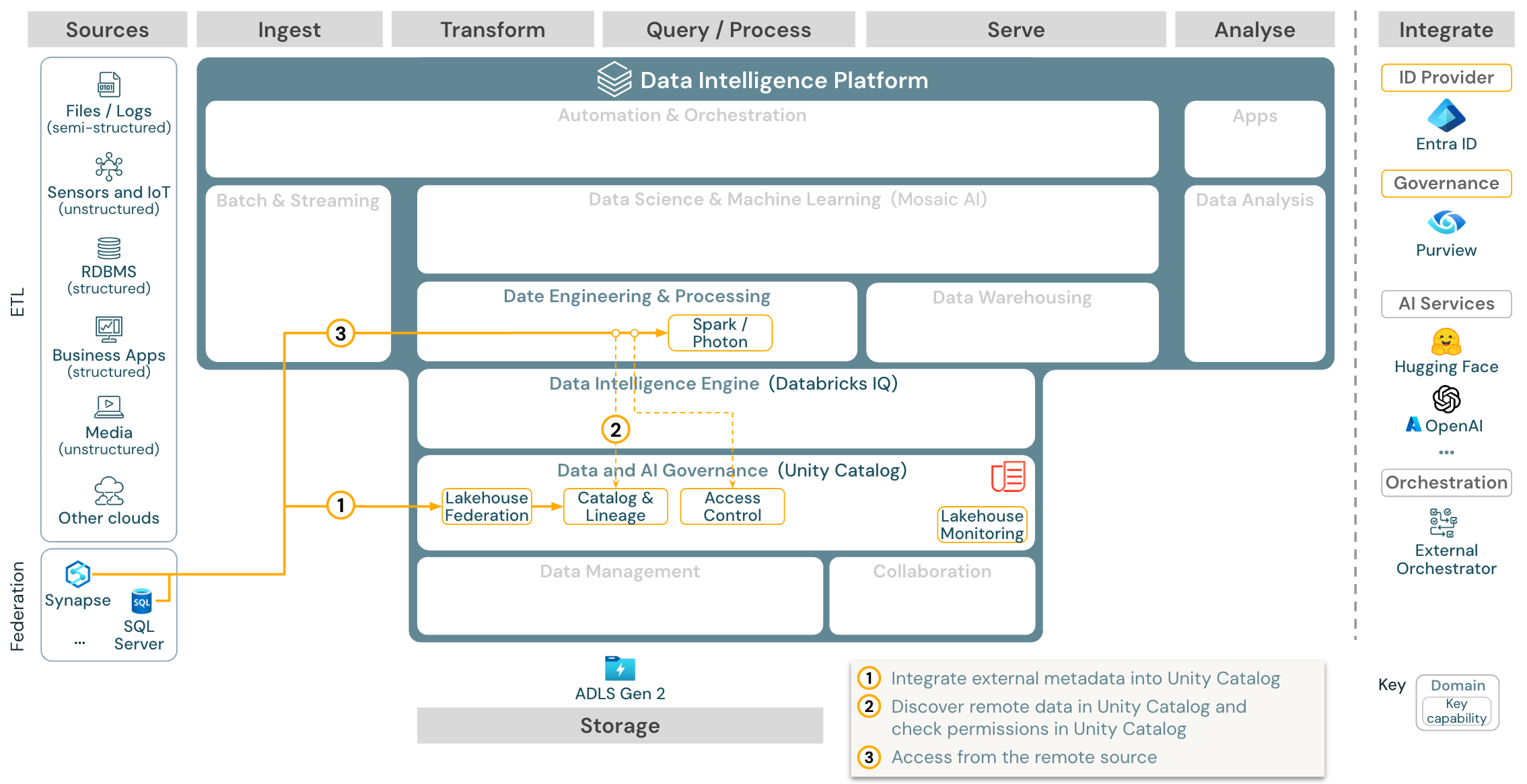
下载:适用于 Azure Databricks 的湖屋联合参考体系结构
湖屋联合允许将外部数据 SQL 数据库(例如 MySQL、Postgres、SQL Server 或 Azure Synapse)与 Databricks 集成。
所有工作负载(AI、DWH 和 BI)都可以从中受益,因为不需要首先提取、转换数据并将其加载到对象存储中。 外部源目录映射到 Unity Catalog,可以对通过 Databricks 平台进行的访问应用细粒度访问控制。
用例:企业数据共享
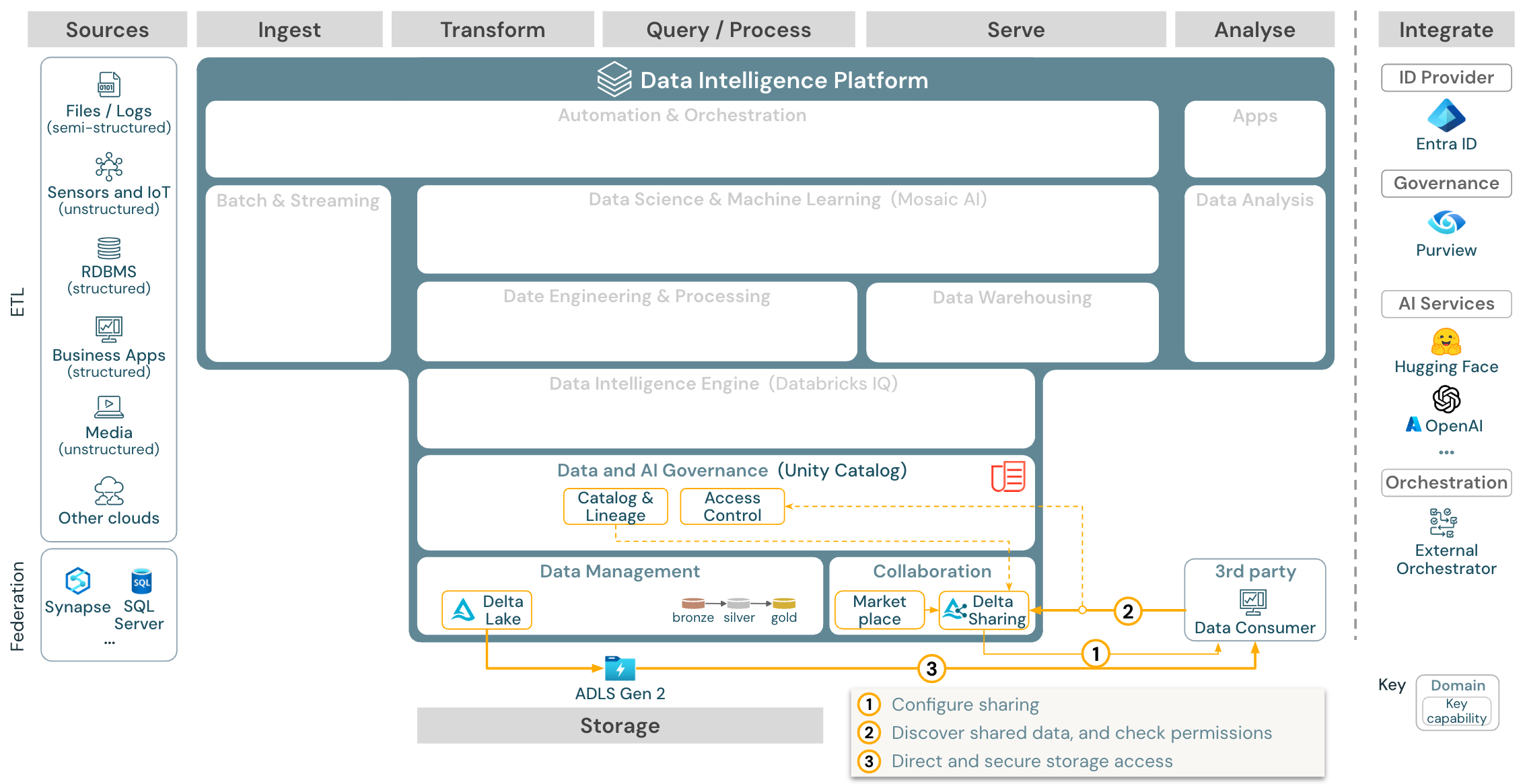
下载:适用于 Azure Databricks 的企业数据共享参考体系结构
企业级数据共享由 Delta Sharing 提供。 它对由 Unity Catalog 保护的对象存储中的数据提供直接访问,Databricks 市场是一个用于交换数据产品的开放论坛。