什么是奖牌 Lakehouse 体系结构?
奖牌体系结构描述了一系列数据层,这些数据层表示 Lakehouse 中存储的数据质量。 Azure Databricks 建议采用多层方法为企业数据产品生成单一事实源。
此体系结构保证了数据的原子性、一致性、隔离性和持久性,因为数据通过多层验证和转换,然后存储在针对高效分析而优化的布局中。 术语铜牌(原始)、银牌(已验证)和 金牌(已扩充)描述了每一层中的数据质量。
作为数据设计模式的奖牌体系结构
奖牌体系结构是一种数据设计模式,用于以逻辑方式组织数据。 其目标是在数据流经体系结构的每一层(铜牌层到银牌层再到金牌层)时,逐步改进数据的结构和质量。 奖牌体系结构有时也称为多跃点体系结构。
通过在这些层中处理数据,组织可以逐步提高数据的质量和可靠性,使其更适合商业智能和机器学习应用程序。
遵循奖牌体系结构是建议的最佳做法,但不是必需。
| 问题 | Bronze | Silver | Gold |
|---|---|---|---|
| 该层会发生什么情况? | 原始数据引入 | 数据清理和验证 | 维度建模和聚合 |
| 谁是目标用户? | - 数据工程师 - 数据操作 - 相容性和审核团队 |
- 数据工程师 - 数据分析师(使用银牌层获取更精细的数据集,该数据集仍保留深入分析所需的详细信息) - 数据科学家(构建模型并执行高级分析) |
- 业务分析师和 BI 开发人员 - 数据科学家和机器学习 (ML) 工程师 - 高管和决策者 - 运营团队 |
奖牌体系结构示例
这一奖牌体系结构的示例展示供业务运营团队使用的铜牌层、银牌层和金牌层。 每一层都存储在操作目录的不同架构中。
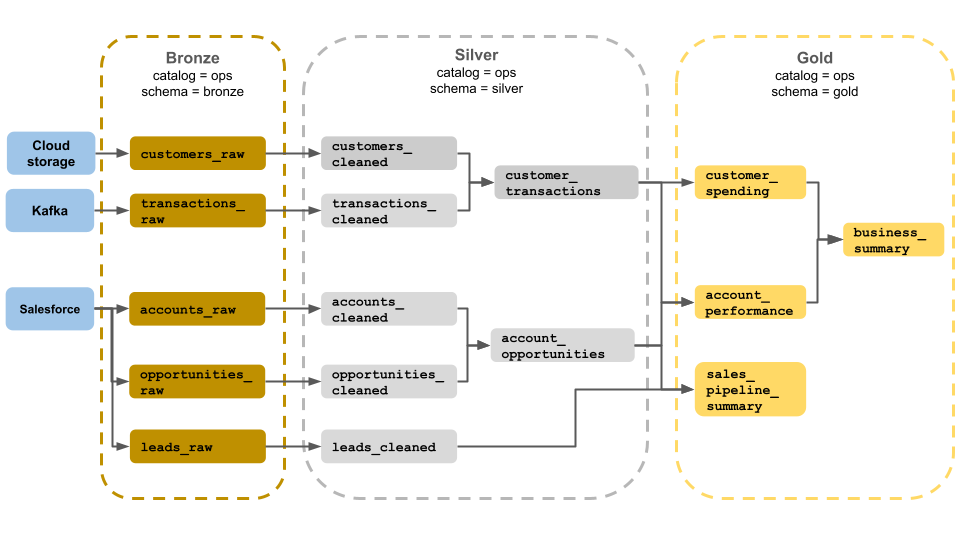
- 铜牌层 (
ops.bronze):从云存储、Kafka 和 Salesforce 引入原始数据。 此处不执行数据清理或验证。 - 银牌层 (
ops.silver):在此层中执行数据清理和验证。- 通过删除 Null 和隔离无效记录,清理有关客户和事务的数据。 这些数据集会联接到名为
customer_transactions的新数据集中。 数据科学家可使用此数据集进行预测分析。 - 同样,Salesforce 中的帐户和机会数据集也会进行联接,以创建
account_opportunities,其通过帐户信息得到增强。 - 清理
leads_raw数据集中的leads_cleaned数据。
- 通过删除 Null 和隔离无效记录,清理有关客户和事务的数据。 这些数据集会联接到名为
- 金牌层 (
ops.gold):此层专为商务用户设计。 其包含的数据集少于银牌层和金牌层。customer_spending:每位客户的平均支出和总支出。account_performance:每个帐户的每日性能。sales_pipeline_summary:有关端到端销售管道的信息。business_summary:为高管人员提供高度聚合的信息。
将原始数据引入铜牌层
铜牌层包含未经验证的原始数据。 引入铜牌层的数据通常具有以下特征:
- 以原始格式包含和维护数据源的原始状态。
- 以增量方式追加,并随时间推移而增长。
- 旨在供丰富银牌层表数据的工作负载使用,而不是供分析师和数据科学家访问。
- 充当单一事实来源,保留数据的保真度。
- 通过保留所有历史数据以启用重新处理和审核。
- 可以是来自源的流式处理和批处理事务的任意组合,包括云对象存储(例如 S3、GCS、ADLS)、消息总线(例如 Kafka、Kinesis 等)和联合系统(例如 Lakehouse Federation)。
限制数据清理或验证
在铜牌层中执行最少的数据验证。 为防止丢失数据,Azure Databricks 建议将大多数字段存储为字符串、VARIANT 或二进制字段,以防出现意外的架构更改。 可以添加元数据列,例如数据来源或数据源(例如 _metadata.file_name )。
对银牌层中的数据进行验证和删除重复
在银牌层中执行数据清理和验证。
在铜牌层中构建银牌表
若要构建银牌表,请从一个或多个铜牌表或银牌表读取数据,并将数据写入银牌表。
Azure Databricks 不建议直接将引入数据写入银牌表。 如果直接从引入进行写入,则由于架构更改或数据源中的记录损坏,将引入失败。 假设所有源都是仅追加源,请将大多数来自铜牌层的读取配置为流读取。 应为小型数据集保留批量读取(例如小维度表)。
银牌层展示经过验证、清理和扩充的数据版本。 银牌层:
- 应始终包含每个记录的至少一个经过验证的非聚合表示形式。 如果聚合表示形式驱动多个下游工作负载,则这些表示形式可能位于银牌层,但通常情况下位于金牌层。
- 执行数据清理、重复数据删除和数据规范化的位置。
- 通过更正错误和不一致以提高数据质量。
- 将数据结构为更易使用的格式,以便进行下游处理。
保证数据质量
以下操作在银牌表中执行:
- 架构实施
- Null 值和缺失值处理
- 重复数据删除
- 解决无序和延迟到达的数据问题
- 数据质量检查和执行
- 架构演变
- 类型强制转换
- 联接
开始对数据建模
通常在银牌层开始执行数据建模,包括选择如何表示大量嵌套或半结构化数据
- 使用
VARIANT数据类型 - 使用
JSON字符串。 - 创建结构、映射和数组。
- 平展架构或将数据规范化到多个表中。
使用金牌层进行分析
金牌层表示驱动下游分析、仪表板、ML 和应用程序的数据的高度优化视图。 金牌层数据通常高度聚合,并针对特定时间段或地理区域进行筛选。 其包含语义上有意义的数据集,这些数据集映射到业务功能和需求。
金牌层:
- 由专用于分析和报告的聚合数据组成。
- 与业务逻辑和要求保持一致。
- 针对查询和仪表板中的性能进行优化。
与业务逻辑和要求保持一致
黄金层是通过建立关系和定义度量值,使用维度模型为数据建模以报告和分析。 有权访问金牌层数据的分析师应该能够找到特定域的数据并回答问题。
由于金牌层对业务领域进行建模,因此某些客户会创建多个金牌层,以满足不同的业务需求,例如 HR、财务和 IT。
创建专用于分析和报告的聚合
组织通常需要针对平均值、计数、最大值和最小值等度量值创建聚合函数。 例如,如果企业需要回答有关每周总销售额的问题,则可以创建一个名为预聚合此数据的具体化视图 weekly_sales ,以便分析师和其他人员无需重新创建常用具体化视图。
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
优化查询和仪表板中的性能
优化金牌层表的性能是最佳做法,因为这些数据集经常被查询。 通常情况下,大量的历史数据是通过银牌层进行访问,而不是通过金牌层具体化。
调整数据引入的频率以控制成本
确定引入数据的频率以控制成本。
| 数据引入频率 | 成本 | 延迟 | 声明性示例 | 程序性示例 |
|---|---|---|---|---|
| 连续增量引入 | 更高 | 更低 | - 流式处理表使用 spark.readStream 从云存储或消息总线引入。- 更新此流式处理表的增量实时表管道会持续运行。 - 结构化流式处理代码使用笔记本中的 spark.readStream 从云存储或消息总线引入 Delta 表。- 将 Azure Databricks 作业与连续作业触发器配合使用,以编排笔记本。 |
|
| 触发的增量引入 | 更低 | 更高 | - 流式处理表使用 spark.readStream 从云存储或消息总线引入。- 更新此流式处理表的管道由作业的计划触发器或文件到达触发器触发。 - 具有 Trigger.Available 触发器的笔记本中的结构化流式处理代码。- 此笔记本由作业的计划触发器或文件到达触发器触发。 |
|
| 使用手动增量引入进行批量引入 | 更低 | 最高,因为运行不频繁。 | - 流式处理表使用 spark.read 从云存储引入。- 不使用结构化流式处理。 相反,使用分区覆盖等基元一次性更新整个分区。 - 需要广泛的上游体系结构以设置增量处理,从而产生类似于结构化流读取/写入的成本。 - 还需按 datetime 字段对源数据进行分区,然后将该分区中的所有记录处理到目标中。 |