Azure Databricks 上的 MLOps 工作流
本文介绍如何在 Databricks 平台上使用 MLOps 来优化机器学习 (ML) 系统的性能和长期效率。 它包括针对 MLOps 体系结构的一般建议,还描述了使用 Databricks 平台的通用工作流,你可将该工作流用作 ML 开发到生产过程的模型。 有关此 LLMOps 应用程序工作流的修改,请参阅 LLMOps 工作流。
有关详细信息,请参阅 MLOps 全书。
什么是 MLOps?
MLOps 是一组流程和自动化步骤,用于管理代码、数据和模型,以提高 ML 系统的性能、稳定性和长期效率。 它结合了 DevOps、DataOps 和 ModelOps。
代码、数据和模型等 ML 资产的开发依次经过以下阶段:早期开发阶段(没有严格的访问限制且未经过严格测试)、中期测试阶段和最终生产阶段(受到严格控制)。 通过 Databricks 平台,你可以使用统一访问控制在单个平台上管理这些资产。 可以在同一平台上开发数据应用程序和 ML 应用程序,从而降低与移动数据相关的风险和延迟。
有关 MLOps 的一般建议
本部分包括一些关于 Databricks 上的 MLOps 的一般建议,以及有关详细信息的链接。
为每个阶段创建单独的环境
执行环境是代码创建或使用模型和数据的地方。 每个执行环境都由计算实例、其运行时和库以及自动化作业组成。
Databricks 建议为 ML 代码和模型开发的不同阶段创建单独的环境,并在阶段之间明确定义转换。 本文中介绍的工作流遵循此过程,使用阶段的通用名称:
其他配置也可用于满足组织的特定需求。
访问控制和版本控制
访问控制和版本控制是任何软件操作过程的关键组件。 Databricks 建议如下:
- 使用 Git 进行版本控制。 管道和代码应存储在 Git 中以进行版本控制。 然后,在阶段之间移动 ML 逻辑可以解释为将代码从开发分支移动到过渡分支,再到发布分支。 使用 Databricks Git 文件夹与 Git 提供程序集成,并将笔记本和源代码与 Databricks 工作区同步。 Databricks 还提供用于 Git 集成和版本控制的其他工具;请参阅 本地开发工具。
- 使用 Delta 表将数据存储在湖屋体系结构中。 数据应存储在云帐户中的湖屋体系结构中。 原始数据和特征表都应存储为具有访问控制的 Delta 表,以确定谁可以读取和修改它们。
- 使用 MLflow 管理模型开发。 可以使用 MLflow 跟踪模型开发过程并保存代码快照、模型参数、指标和其他元数据。
- 使用 Unity 目录中的模型来管理模型生命周期。 使用 Unity 目录中的模型来管理模型版本控制、治理和部署状态。
部署代码,而不是模型
在大多数情况下,Databricks 建议在 ML 开发过程中,将代码(而不是模型)从一个环境提升到下一个环境。 以这种方式移动项目资产可确保 ML 开发过程中的所有代码都经过相同的代码评审和集成测试过程。 它还确保模型的生产版本在生产代码上进行训练。 有关选项和权衡的更详细讨论,请参阅模型部署模式。
建议的 MLOps 工作流
以下部分介绍典型的 MLOps 工作流,涵盖三个阶段:开发、过渡和生产。
此部分使用术语“数据科学家”和“ML 工程师”作为原型角色;MLOps 工作流中的特定角色和职责因团队和组织而异。
开发阶段
开发阶段的重点是试验。 数据科学家开发功能和模型,并运行试验以优化模型性能。 开发过程的输出是 ML 管道代码,其中可以包括特征计算、模型训练、推理和监视。
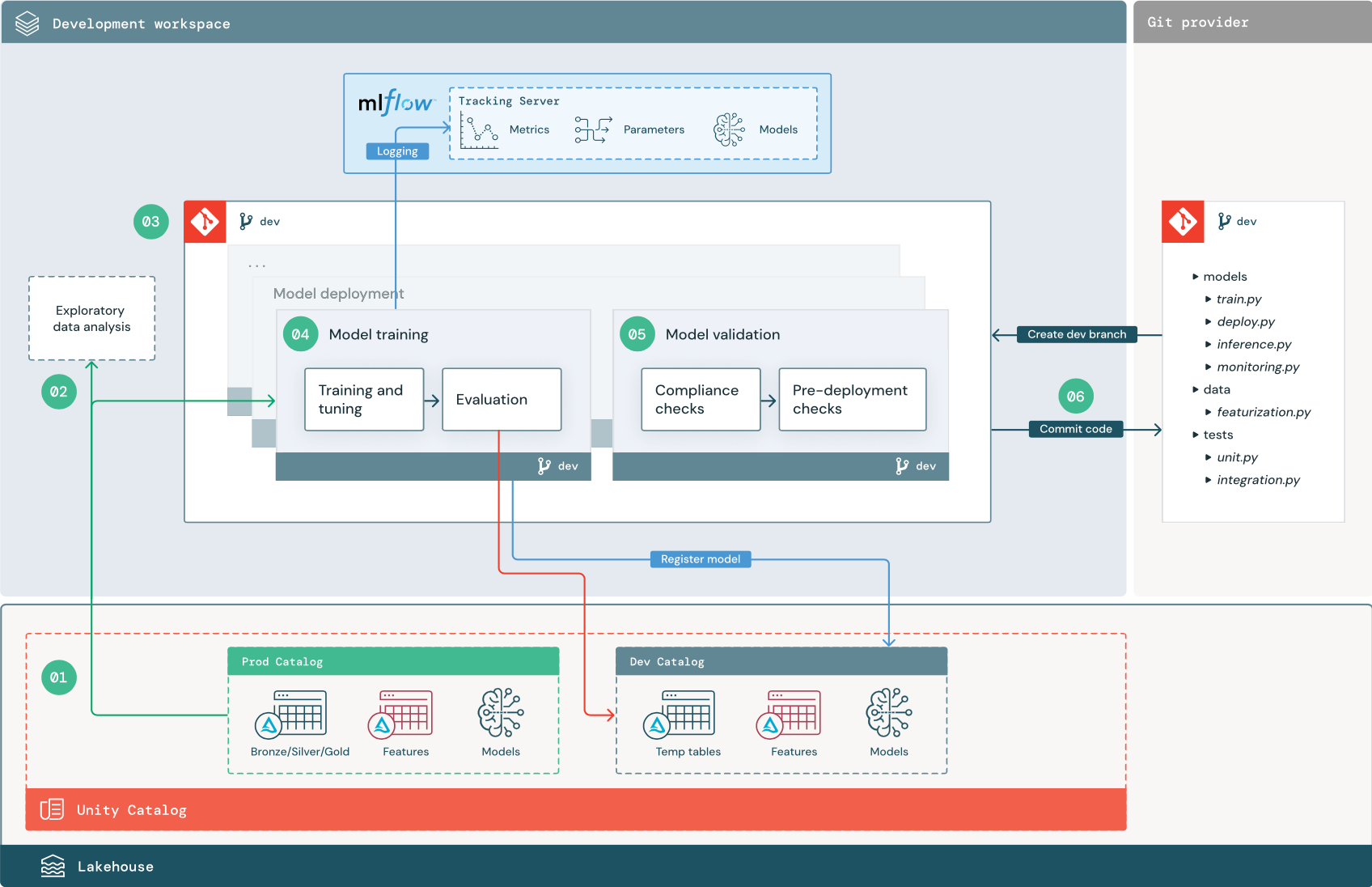
编号的步骤与图中显示的数字相对应。
1. 数据源
开发环境由 Unity 目录中的开发目录表示。 数据科学家在开发工作区中创建临时数据和功能表时,对开发目录具有读写访问权限。 在开发阶段创建的模型会注册到开发目录。
理想情况下,在开发工作区中工作的数据科学家还可以对生产目录中的生产数据具有只读访问权限。 允许数据科学家读取访问生产目录中的生产数据、推理表和指标表,这使他们能够分析当前的生产模型预测和性能。 数据科学家应该也能够加载生产模型进行试验和分析。
如果无法授予对生产目录的只读访问权限,则可以将生产数据的快照写入开发目录,使数据科学家能够开发和评估项目代码。
2. 探索性数据分析 (EDA)
数据科学家使用笔记本在交互式迭代过程中探索和分析数据。 目标是评估可用数据是否有可能解决业务问题。 在此步骤中,数据科学家开始识别用于模型训练的数据准备和特征化步骤。 此临时过程通常不属于将要部署在其他执行环境中的管道。
AutoML 通过为数据集生成基线模型来加速此过程。 AutoML 执行并记录一组试用,并为每次试用运行提供一个包含源代码的 Python 笔记本,以便查看、重现和修改代码。 AutoML 还会计算数据集的汇总统计信息,并将此信息保存在可查看的笔记本中。
3. 代码
代码存储库包含 ML 项目的所有管道、模块和其他项目文件。 数据科学家可在项目存储库的开发 ("dev") 分支中创建新的或已更新的管道。 从 EDA 和项目的初始阶段开始,数据科学家应在存储库中工作,以共享代码和跟踪更改。
4.训练模型(开发)
数据科学家使用开发或生产目录中的表在开发环境中开发模型训练管道。
此管道包括 2 个任务:
训练和优化。 训练过程会将模型参数、指标和项目记录到 MLflow 跟踪服务器。 训练并优化超参数后,最终模型项目将记录到跟踪服务器,以记录模型、训练依据的输入数据以及用于生成它的代码之间的联系。
评估。 通过测试保留的数据来评估模型质量。 这些测试的结果将记录到 MLflow 跟踪服务器。 评估的目的是确定新开发的模型的性能是否优于当前生产模型。 如果权限足够,可以将任何注册到生产目录的生产模型加载到开发工作区中,并与新训练的模型进行比较。
如果组织的治理要求包括有关模型的其他信息,则可以使用 MLflow 跟踪进行保存。 典型项目是纯文本描述和模型解释,例如由 SHAP 生产的绘图。 具体的治理要求可能来自数据治理官员或业务利益干系人。
模型训练管道会输出存储在 MLflow 跟踪服务器的 ML 模型项目,用于开发环境。 如果在过渡或生产工作区中执行管道,模型项目将存储在该工作区的 MLflow 跟踪服务器中。
模型训练完成后,将模型注册到 Unity 目录。 设置管道代码,将模型注册到与模型管道的执行环境对应的目录(在本示例中是开发目录)。
使用建议的体系结构,可以部署一个多任务 Databricks 工作流,其中第一个任务是模型训练管道,然后是模型验证和模型部署任务。 模型训练任务会生成模型验证任务可以使用的模型 URI。 可以使用任务值将此 URI 传递给模型。
5.验证和部署模型(开发)
除了模型训练管道,其他管道(如模型验证和模型部署管道)也在开发环境中开发。
模型验证。 模型验证管道从模型训练管道获取模型 URI,从 Unity 目录加载模型,并运行验证检查。
验证检查取决于上下文。 它们可以包括基本检查,如确认格式和所需的元数据,以及高度监管行业可能需要的更复杂的检查,如预定义的合规性检查和确认所选数据切片上的模型性能。
模型验证管道的主要功能是确定模型是否应继续执行部署步骤。 如果模型通过了预部署检查,则可以在 Unity 目录中为其分配“挑战者”别名。 如果检查失败,此过程将结束。 可以将工作流配置为通知用户验证失败。 请参阅在作业上添加通知。
模型部署。 模型部署管道一般通过更新别名将新训练的“挑战者”模型直接提升为“冠军”状态,或者将现有“冠军”模型与新的“挑战者”模型进行比较。 此管道还可以设置任何必需的推理基础结构,例如模型服务终结点。 有关模型部署管道中涉及的步骤的详细讨论,请参阅 “生产”。
6. 提交代码
在开发训练、验证、部署和其他管道的代码后,数据科学家或 ML 工程师会将开发分支更改提交到源代码管理中。
过渡阶段
此阶段的重点是测试 ML 管道代码,以确保其已为生产环境做好准备。 在此阶段测试所有 ML 管道代码,包括用于模型训练的代码以及特征工程管道、推理代码等。
ML 工程师创建一个 CI 管道来实现在此阶段运行的单元和集成测试。 过渡过程的输出是一个发布分支,它触发 CI/CD 系统以启动生产阶段。
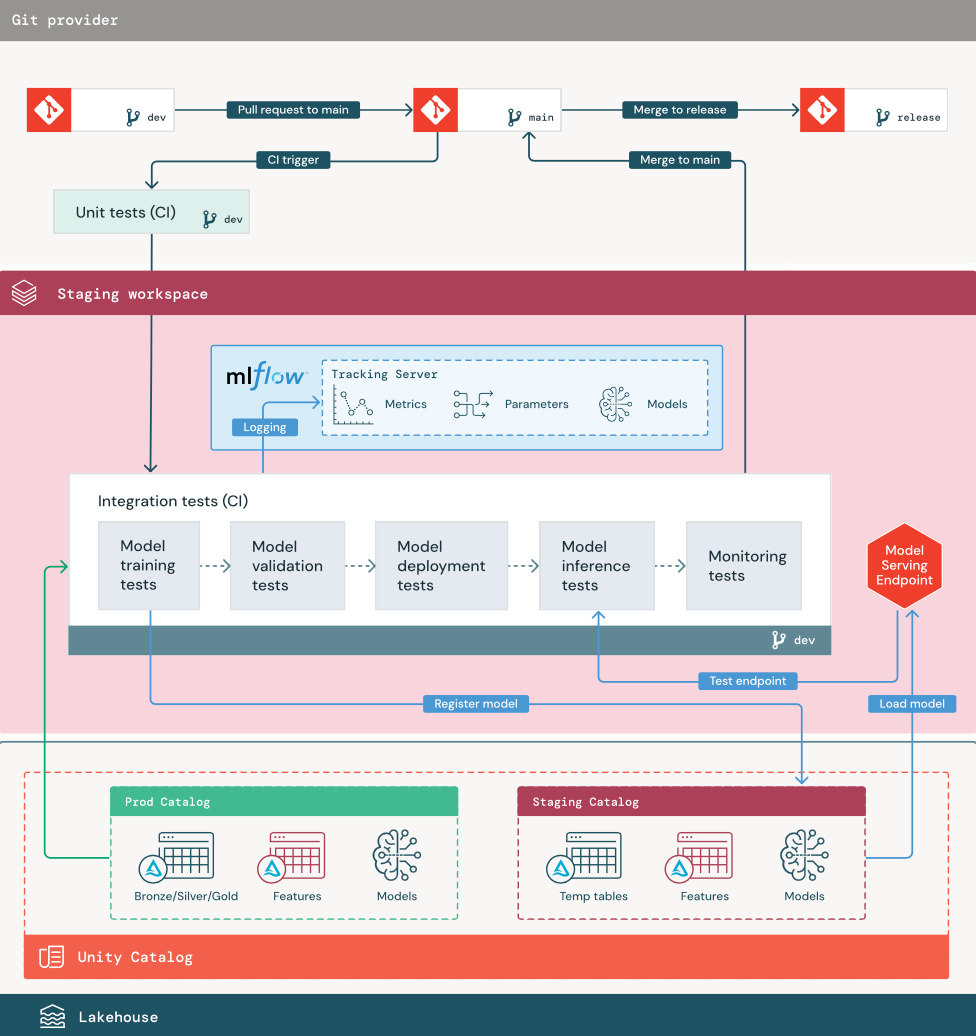
1.数据
过渡环境应在 Unity 目录中有自己的目录,用于测试 ML 管道和将模型注册到 Unity 目录。 此目录在关系图中显示为“过渡”目录。 写入此目录的资产通常是临时的,仅保留到测试完成时。 开发环境可能还需要访问此过渡目录以进行调试。
2.合并代码
数据科学家使用开发或生产目录中的表在开发环境中开发模型训练管道。
拉取请求。 在源代码管理中针对项目的主分支创建拉取请求时,部署过程开始。
单元测试 (CI)。 拉取请求会自动生成源代码并触发单元测试。 如果单元测试失败,拉取请求将被拒绝。
单元测试是软件开发过程的一部分,在开发任何代码的过程中持续执行并添加到代码库。 将单元测试作为 CI 管道的一部分运行,可确保在开发分支中所做的更改不会破坏现有功能。
3. 集成测试 (CI)
然后,CI 过程运行集成测试。 集成测试运行所有管道(包括特征工程、模型训练、推理和监视),以确保它们一起正确工作。 过渡环境应尽可能与生产环境紧密匹配。
如果要部署具有实时推理的 ML 应用程序,则应在过渡环境中创建并测试服务基础结构。 这涉及到触发模型部署管道,它会在过渡环境中创建服务终结点并加载模型。
为了减少运行集成测试所需的时间,一些步骤可以在测试的保真度、速度和成本之间进行权衡。 例如,如果模型训练很昂贵或耗时,则可以使用较小的数据子集或运行较少的训练迭代。 对于模型服务,根据生产要求,可以在集成测试中执行全面负载测试,或者只测试小型批处理作业或对临时终结点的请求。
4. 合并到临时分支
如果所有测试都通过,新代码将合并到项目的主分支中。 如果测试失败,CI/CD 系统应通知用户并在拉取请求上发布结果。
可以在主分支上计划定期集成测试。 如果该分支经常使用来自多个用户的并发拉取请求进行更新,那么这是一个好主意。
5. 创建版本分支
通过 CI 测试且将开发分支合并到主分支后,ML 工程师会创建一个发布分支,这会触发 CI/CD 系统更新生产作业。
生产阶段
ML 工程师拥有部署和执行 ML 管道的生产环境。 这些管道出发模型训练,验证并部署新的模型版本,将预测发布到下游表或应用程序,并监视整个过程,以避免性能降低和不稳定。
数据科学家在生产环境中通常没有写入或计算访问权限。 但是,他们必须能够查看测试结果、日志、模型项目、生产管道状态和监视表。 这使他们能够识别和诊断生产中的问题,并将新模型的性能与当前生产中的模型进行比较。 可以授予数据科学家对生产目录中资产的只读访问权限,以实现这些目的。
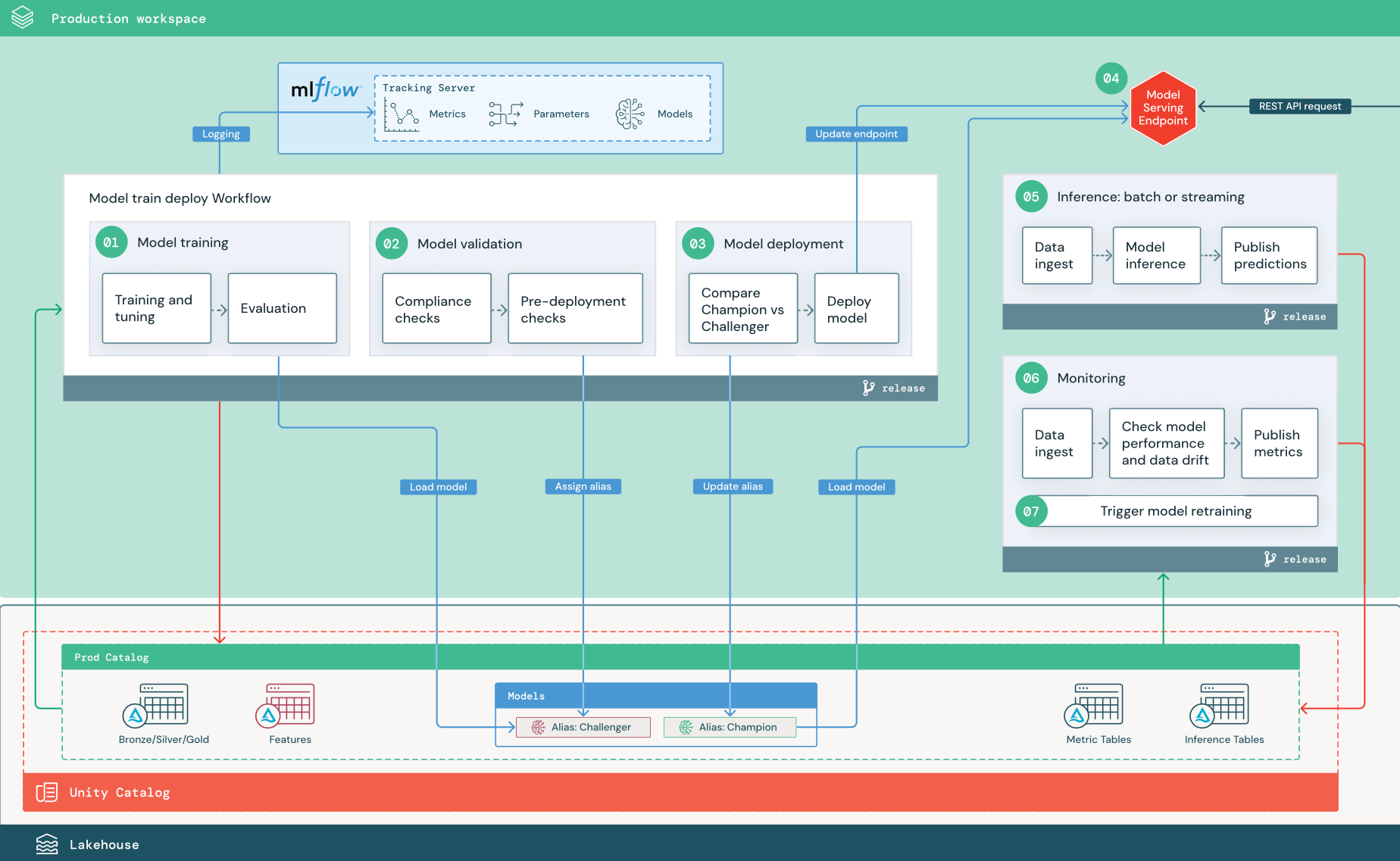
编号的步骤与图中显示的数字相对应。
1.定型模型
此管道可以由代码更改或自动重新训练作业触发。 在此步骤中,生产目录中的表用于以下步骤。
训练和优化。 在训练过程中,日志将记录到生产环境 MLflow 跟踪服务器。 这些日志包括模型指标、参数、标记和模型本身。 如果使用功能表,则会通过 Databricks 功能存储客户端将模型记录到 MLflow,该客户端使用推理时使用的功能查找信息来打包模型。
在开发过程中,数据科学家可能会测试许多算法和超参数。 在生产训练代码中,通常只考虑性能最佳的选项。 以这种方式限制优化可以节省时间,并且可以减少与自动重新训练中优化的差异。
如果数据科学家可以只读访问生产目录,他们也许能确定模型的最佳超参数集。 在这种情况下,可以使用所选的超参数集(通常作为配置文件包含在管道中)执行部署在生产中的模型训练管道。
评估。 通过对保留生产数据的测试来评估模型质量。 这些测试的结果将记录到 MLflow 跟踪服务器。 此步骤使用数据科学家在开发阶段指定的评估指标。 这些指标可能包括自定义代码。
注册模型。 模型训练完成后,模型项目将保存为 Unity 目录的生产目录中指定模型路径的已注册模型版本。 模型训练任务会生成模型验证任务可以使用的模型 URI。 可以使用任务值将此 URI 传递给模型。
2.验证模型
此管道使用步骤 1 中的模型 URI,并从 Unity 目录加载该模型。 然后,它会执行一系列验证检查。 这些检查取决于你的组织和用例,可以包括基本格式和元数据验证、所选数据切片的性能评估以及符合组织要求(例如标记或文档的合规性检查)。
如果模型成功通过所有验证检查,则可以将“挑战者”别名分配给 Unity 目录中的模型版本。 如果模型未通过所有验证检查,进程将退出,并自动通知用户。 可以根据这些验证检查的结果,使用标记添加键值属性。 例如,可以创建标记“model_validation_status”,并在测试执行时将值设置为“PENDING”,然后在管道完成后将其更新为“PASSED”或“FAILED”。
由于模型已注册到 Unity 目录,因此在开发环境中工作的数据科学家可以从生产目录加载此模型版本,调查模型是否未通过验证。 无论验证结果如何,都会使用模型版本的注释将结果记录到生产目录中的已注册模型。
3.部署模型
与验证管道一样,模型部署管道取决于组织和用例。 本部分假定你已为新验证的模型分配了“挑战者”别名,并且已为现有生产模型分配了“冠军”别名。 在部署新模型之前,首先要确认它的表现至少和当前生产模型相当。
将“挑战者”与“冠军”模型进行比较。 可以脱机或联机执行此比较。 脱机比较可针对保留数据集评估这两个模型,并使用 MLflow 跟踪服务器跟踪结果。 对于实时模型服务,可能需要执行长期的联机比较,例如 A/B 测试或逐步推出新模型。 如果“挑战者”模型版本在比较中表现更好,它将替换当前的“冠军”别名。
使用 Mosaic AI 模型服务和 Databricks Lakehouse 监视,可以自动收集和监视包含终结点请求和响应数据的推理表。
如果没有现有的“冠军”模型,可以将“挑战者”模型与业务启发或其他阈值进行比较作为基线。
此处所述的过程是完全自动化的。 如果需要手动审批步骤,可以使用模型部署管道中的工作流通知或 CI/CD 回调来设置这些步骤。
部署模型。 可以设置批处理或流式推理管道,将使用具有“冠军”别名的模型。 对于实时用例,必须设置基础结构以将模型部署为 REST API 终结点。 可以使用 Mosaic AI 模型服务创建和管理此终结点。 如果已有终结点用于当前模型,则可以使用新模型更新终结点。 Mosaic AI 模型服务通过使现有配置保持运行到新配置准备就绪,从而执行零停机时间更新。
4.模型服务
配置模型服务终结点时,需要指定 Unity 目录中模型的名称和要服务的版本。 如果模型版本是使用 Unity 目录中表的特征训练的,则模型会存储特性和函数的依赖关系。 模型服务会自动使用此依赖项关系图,在推理时从适当的在线商店查找功能。 此方法还可用于应用函数进行数据预处理,或在模型评分期间计算按需特征。
可以创建具有多个模型的单个终结点,并指定这些模型之间的终结点流量拆分,使你可以在线比较“冠军”与“挑战者”。
5. 推理:批处理或流式传输
推理管道从生产目录读取最新数据,执行函数来计算按需特征,加载“冠军”模型,对数据评分,并返回预测。 对于更高吞吐量、更高延迟的用例,批处理或流式推理通常是最具成本效益的选项。 对于需要低延迟预测,但可以脱机计算预测的情况,可以将这些批预测发布到联机键值存储(如 DynamoDB 或 Cosmos DB)。
Unity 目录中的注册模型由其别名引用。 推理管道配置为加载并应用“冠军”模型版本。 如果“冠军”版本更新为新的模型版本,推理管道会自动使用新版本进行下一次执行。 这样,模型部署步骤就与推理管道分离了。
批处理作业通常将预测发布到生产目录中的表、平面文件,或通过 JDBC 连接发布。 流式处理作业通常将预测发布到 Unity 目录表或消息队列(例如 Apache Kafka)。
6.Lakehouse Monitoring
Lakehouse Monitoring 可监视输入数据和模型预测的统计属性,例如数据偏移和模型性能。 可以根据这些指标创建警报,也可以在仪表板中发布警报。
- 数据引入。 此管道从批处理、流式处理或联机推理中读取日志。
- 检查准确性和数据偏移。 管道计算有关输入数据、模型预测和基础结构性能的指标。 数据科学家在开发过程中指定数据和模型指标,ML 工程师指定基础结构指标。 还可以使用 Lakehouse Monitoring 定义自定义指标。
- 发布指标并设置警报。 管道会写入生产目录中的表,以供分析和报告。 应将这些表配置为可从开发环境读取,以便数据科学家能够访问这些表进行分析。 可以使用 Databricks SQL 创建监视仪表板以跟踪模型性能,并设置监视作业或仪表板工具以在指标超过指定阈值时发出通知。
- 触发器模型重新训练。 当监视指标显示输入数据存在性能问题或更改时,数据科学家可能需要开发新的模型版本。 可以设置 SQL 警报,在发生这种情况时通知数据科学家。
7.重新训练
此体系结构支持使用上述相同模型训练管道来自动重新训练。 Databricks 建议从计划的定期重新训练开始,在需要时再转到触发的重新训练。
- 计划。 如果定期有新数据可用,则可以创建计划作业以对最新的可用数据运行模型训练代码。 请参阅使用计划和触发器自动执行作业
- 触发。 如果监视管道可以识别模型性能问题并发送警报,那么它也可以触发重新训练。 例如,如果传入数据的分布发生显著变化或者模型性能下降,则自动重新训练和重新部署可以通过最少人工干预提高模型性能。 这可以通过 SQL 警报来实现,检查指标是否异常(例如,根据阈值检查数据偏移或模型质量)。 警报可配置为使用 Webhook 目标,该目标随后可以触发训练工作流。
如果重新训练管道或其他管道出现性能问题,数据科学家可能需要返回到开发环境,进行其他试验来解决这些问题。