使用 Unity Catalog 捕获和查看数据世系
本文介绍如何使用目录资源管理器、数据世系系统表和 REST API 捕获和可视化数据世系。
可以使用 Unity Catalog 在对 Azure Databricks 运行的查询中捕获运行时数据世系。 所有语言都支持世系,世系捕获级别低至列。 世系数据包括与查询相关的笔记本、作业和仪表板。 可在目录资源管理器中近乎实时地可视化世系,还可使用世系系统表和 Databricks REST API 以编程方式检索世系。
将聚合附加到 Unity Catalog 元存储的所有工作区中的世系。 这意味着,在一个工作区中捕获的世系将在共享该元存储的任何其他工作区中可见。 具体而言,对于注册在元存储中的表及其他数据对象,只要用户对这些对象拥有至少 BROWSE 权限,那么在所有连接到该元存储的工作区中,这些用户都能看到这些对象。 但是,有关工作区级别对象(如其他工作区中的笔记本和仪表板)的详细信息将被屏蔽(请参阅 限制 和 世系权限)。
世系数据会保留一年。
下图是一个示例世系图。 本文稍后将介绍特定的数据世系功能和示例。
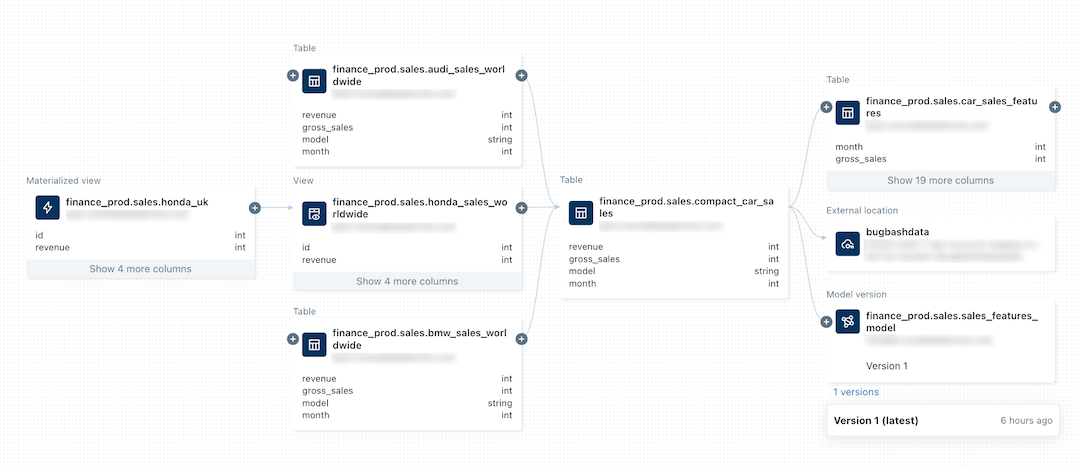
若要了解如何跟踪机器学习模型的世系,请参阅跟踪 Unity Catalog 中模型的数据世系。
要求
使用 Unity Catalog 捕获数据世系需要满足以下要求:
工作区必须已启用 Unity Catalog。
表必须已在 Unity Catalog 元存储中注册。
查询必须使用 Spark 数据帧(例如,返回数据帧的 Spark SQL 函数)或 Databricks SQL 接口。 有关 Databricks SQL 和 PySpark 查询的示例,请参阅示例。
要查看表或视图的世系,用户必须至少对表或视图的父目录具有
BROWSE特权。 此外还必须能够从工作区访问该父目录。 请参阅仅限特定工作区能访问目录。若要查看笔记本、作业或仪表板的世系信息,用户必须对这些对象拥有工作区中的访问控制设置所定义的权限。 请参阅世系权限。
若要查看 已启用 Unity Catalog 的管道的世系,必须对该管道具有
CAN_VIEW权限。增量表之间的流式传输进行世系跟踪需要 Databricks Runtime 11.3 LTS 或更高版本。
增量实时表工作负载的列世系跟踪需要 Databricks Runtime 13.3 LTS 或更高版本。
可能需要更新出站防火墙规则,才能在 Azure Databricks 控制平面中连接到事件中心终结点。 通常,这一点适用于 Azure Databricks 工作区部署在你自己的 VNet 中(也称为 VNet 注入)的情况。 若要获取适用于你的工作区区域的事件中心终结点,请参阅元存储、项目 Blob 存储、系统表存储、日志 Blob 存储和事件中心终结点 IP 地址。 有关为 Azure Databricks 设置用户定义的规则 (UDR) 的信息,请参阅 Azure Databricks 的用户定义的路由设置。
示例
注意
以下示例使用目录名称
lineage_data和架构名称lineagedemo。 若要使用不同的目录和架构,请更改示例中使用的名称。若要完成此示例,必须对架构拥有
CREATE和USE SCHEMA特权。 具有架构MANAGE权限的元存储管理员、目录所有者、架构所有者或用户可以授予这些权限。 例如,要为组“data_engineers”中的所有用户授予在lineagedemo目录中的lineage_data架构内创建表的权限,具有上述特权或角色之一的用户可以运行以下查询:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
捕获和浏览世系
捕获世系数据:
转到 Azure Databricks 登陆页,单击边栏中的
 “新建”,然后从菜单中选择“笔记本”。
“新建”,然后从菜单中选择“笔记本”。输入笔记本的名称,然后在“默认语言”中选择“SQL”。
在“群集”中,选择有权访问 Unity Catalog 的群集。
单击“创建”。
在第一个笔记本单元格中输入以下查询:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menu若要运行查询,请在该单元格中单击,然后按 Shift+Enter,或单击并选择“运行单元格”。
要使用目录资源管理器查看这些查询生成的世系,请:
在 Azure Databricks 工作区顶部栏中的“搜索”框中,搜索 表并选择它。
lineage_data.lineagedemo.dinner选择“世系”选项卡。此时会出现世系面板,其中会显示相关表(在本例中为
menu表)。若要查看数据世系的交互式图形,请单击“查看世系图形”。 默认情况下,图形中显示一个级别。 单击节点上的
 图标以显示更多连接(如果可用)。
图标以显示更多连接(如果可用)。单击连接世系图中节点的箭头,以打开“世系连接”面板。 “世系连接”面板显示有关连接的详细信息,包括源表和目标表、笔记本和作业。
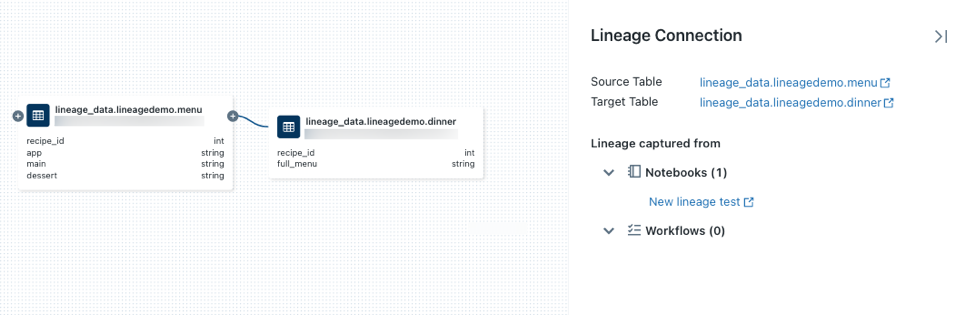
若要显示与
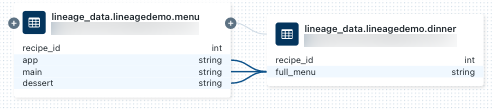
dinner表关联的笔记本,请在“世系连接”面板中选择该笔记本,或关闭世系图形并单击“笔记本”。 要在新选项卡中打开笔记本,请单击笔记本名称。要查看列级别世系,请单击图中的列以显示指向相关列的链接。 例如,单击“full_menu”列将显示该列派生自的上游列:
要使用其他语言(例如 Python)查看世系,请:
打开之前创建的笔记本,创建新单元格,然后输入以下 Python 代码:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")通过在单元格中单击并按 Shift+Enter,或者单击并选择“运行单元格”,来运行该单元格。
在 Azure Databricks 工作区顶部栏中的“搜索”框中,搜索 表并选择它。
lineage_data.lineagedemo.price转到“世系”选项卡并单击“查看世系图”。 单击
图标以浏览查询生成的数据世系。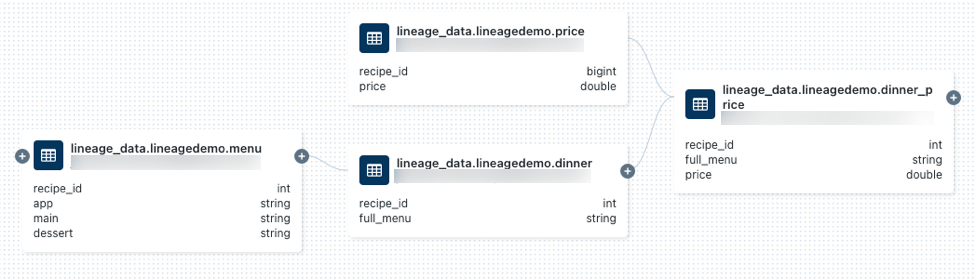
单击连接世系图中节点的箭头,以打开“世系连接”面板。 “世系连接”面板显示有关连接的详细信息,包括源表和目标表、笔记本和作业。
捕获和查看工作流世系
还会为读取或写入 Unity Catalog 的任何工作流捕获世系。 要查看 Azure Databricks 工作流的世系,请:
单击边栏中的
“新建”,然后从菜单中选择“笔记本”。输入笔记本的名称,然后在“默认语言”中选择“SQL”。
单击“创建”。
在第一个笔记本单元格中输入以下查询:
SELECT * FROM lineage_data.lineagedemo.menu单击顶部栏中的“计划”。 在计划对话中,选择“手动”,选择有权访问 Unity Catalog 的群集,然后单击“创建”。
单击“立即运行”。
在 Azure Databricks 工作区顶部栏中的“搜索”框中,搜索 表并选择它。
lineage_data.lineagedemo.menu在“世系”选项卡上,单击“工作流”,然后选择“下游”选项卡。作业名称将作为 表的使用者显示在“作业名称”下面。
menu
捕获和查看仪表板世系
要创建仪表板并查看其数据世系,请:
转到 Azure Databricks 登陆页,然后通过在边栏中单击“目录”打开目录资源管理器。
依次单击目录名称和“lineagedemo”,然后选择 表。
menu还可以使用顶部栏中的“搜索”框来搜索 表。menu单击“在仪表板中打开”。
选择要添加到仪表板的列,然后单击“创建”。
发布仪表板。
数据世系中仅跟踪已发布的仪表板。
在顶部栏中的“搜索”框中,搜索 表并选择它。
lineage_data.lineagedemo.menu在“世系”选项卡上,单击“仪表板”。 仪表板将作为菜单表的使用者显示在“仪表板名称”下。
世系权限
世系图形的权限模型与 Unity Catalog 相同。 在 Unity Catalog 元存储中注册的表和其他数据对象仅对至少具有对这些对象的 BROWSE 权限的用户可见。 如果用户对表没有 BROWSE 或 SELECT 特权,则无法浏览其世系。 世系图展示的是跨所有连接到元存储的工作区的 Unity Catalog 对象,前提是用户具备足够的对象权限。
例如,针对 userA运行以下命令:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
userA 查看 lineage_data.lineagedemo.menu 表的世系图时,将看到 menu 表。 他们将无法查看关联表(例如下游 lineage_data.lineagedemo.dinner 表)的相关信息。 dinner 表在 masked 看到的视图中显示为 userA 节点,并且 userA 无法展开图形以显示他们无权访问的表中的下游表。
如果运行以下命令来授予 userBBROWSE 权限,则用户可以查看 lineage_data 架构中的任何表的世系图。
GRANT BROWSE on lineage_data to `userB@company.com`;
同样,世系用户必须具有查看工作区对象(如笔记本、作业和仪表板)的特定权限。 此外,他们只能在登录到在其中创建这些对象的工作区时查看有关工作区对象的详细信息。 有关其他工作区中工作区级别对象的详细信息在世系图中被屏蔽。
若要详细了解如何在 Unity Catalog 中管理对安全对象的访问,请参阅管理 Unity Catalog 中的特权。 若要详细了解如何管理对工作区对象(例如笔记本、作业、仪表板)的访问,请参阅访问控制列表。
删除世系数据
警告
下面说明如何删除 Unity Catalog 中存储的所有对象。 请仅在必要时按这些说明操作。 例如,在需要满足合规性要求时。
若要删除世系数据,必须删除管理 Unity Catalog 对象的元存储。 有关删除元存储的详细信息,请参阅删除元存储。 数据将在 90 天内删除。
使用系统表查询世系数据
可使用世系系统表以编程方式查询世系数据。 有关详细说明,请参阅使用系统表和世系系统表引用监视帐户活动。
如果工作区位于不支持世系系统表的区域,你可使用数据世系 REST API 以编程方式检索世系数据。
使用数据世系 REST API 检索世系
使用数据世系 API 可以检索表和列世系。 但是,如果工作区位于支持世系系统表的区域,则应使用系统表查询而不是 REST API。 要以编程方式检索世系数据,系统表选项更适合。 大多数区域支持世系系统表。
重要
要访问 Databricks REST API,必须进行身份验证。
检索表世系
此示例检索 dinner 表的世系数据。
请求
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
替换 <workspace-instance>。
此示例使用 .netrc 文件。
响应
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
检索列世系
此示例检索 dinner 表的列数据。
请求
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
替换 <workspace-instance>。
此示例使用 .netrc 文件。
响应
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
限制
尽管世系信息是针对所有连接到同一 Unity Catalog 元存储的工作区进行汇总的,但诸如笔记本和仪表板等工作区对象的详细信息仅在其创建时所在的工作区中可见。
由于世系是在 1 年的滚动时段内计算的,因此不会显示超过 1 年前收集的世系数据。 例如,如果作业或查询从表 A 读取数据并写入表 B,则表 A 和表 B 之间的链接仅显示 1 年。 你可以在一年内按时间范围筛选世系数据。
查看世系时,使用作业 API
runs submit请求的作业不可用。 使用runs submit请求时仍会捕获表和列级别的世系,但不会捕获指向运行的链接。Unity Catalog 会尽可能将世系捕获到列级别。 但在某些情况下无法捕获列级世系。
仅当源和目标都由表名引用时,才支持列世系(示例:
select * from <catalog>.<schema>.<table>)。 如果源或目标按路径寻址(示例:select * from delta."s3://<bucket>/<path>"),则无法捕获列世系。如果重命名表或视图,则不会为重命名的表或视图捕获世系。
如果重命名架构或目录,则重命名的目录或架构下的表和视图不会捕获世系。
如果使用 Spark SQL 数据集检查点,则不会捕获世系。
在大多数情况下,Unity 目录从 Delta Live Tables 管道捕获世系。 但是,在某些情况下无法保证世系覆盖率完整,例如管道使用 APPLY CHANGES API 或 TEMPORARY 表时。
世系不会捕获堆栈函数。
全局临时视图不会在世系中捕获。
system.information_schema下的表不会在世系中捕获。默认情况下,不会为
MERGE操作捕获完整的列级世系。可以通过将 Spark 属性
MERGE设置为spark.databricks.dataLineage.mergeIntoV2Enabled来启用操作的世系捕获true。 启用此标志可能会降低查询性能,尤其是在涉及非常宽表的工作负荷中。