你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure 数据工厂或 Azure Synapse Analytics 向/从文件系统复制数据
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本文概述了如何向/从文件系统复制数据。 有关详细信息,请阅读 Azure 数据工厂或 Azure Synapse Analytics 的简介文章。
支持的功能
此文件系统连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| 复制活动(源/接收器) | ① ② |
| Lookup 活动 | ① ② |
| GetMetadata 活动 | ① ② |
| Delete 活动 | ① ② |
① Azure 集成运行时 ② 自承载集成运行时
具体而言,此文件系统连接器支持:
- 从/向网络文件共享复制文件。 若要使用 Linux 文件共享,请在 Linux 服务器上安装 Samba。
- 使用 Windows 身份验证复制文件。
- 按原样复制文件,或者使用支持的文件格式和压缩编解码器分析/生成文件。
先决条件
如果数据存储位于本地网络、Azure 虚拟网络或 Amazon Virtual Private Cloud 内部,则需要配置自承载集成运行时才能连接到该数据存储。
如果数据存储是托管的云数据服务,则可以使用 Azure Integration Runtime。 如果访问范围限制为防火墙规则中允许的 IP,你可以选择将 Azure Integration Runtime IP 添加到允许列表。
此外,还可以使用 Azure 数据工厂中的托管虚拟网络集成运行时功能访问本地网络,而无需安装和配置自承载集成运行时。
要详细了解网络安全机制和数据工厂支持的选项,请参阅数据访问策略。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建文件系统链接服务
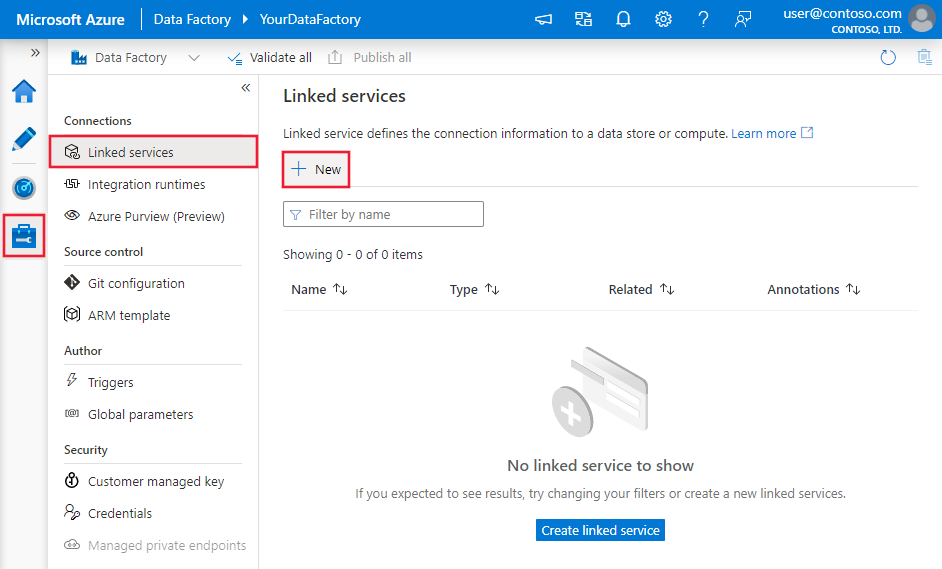
使用以下步骤在 Azure 门户 UI 中创建文件系统链接服务。
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡,并选择“链接服务”,然后单击“新建”:
搜索“文件”并选择“文件系统连接器”。
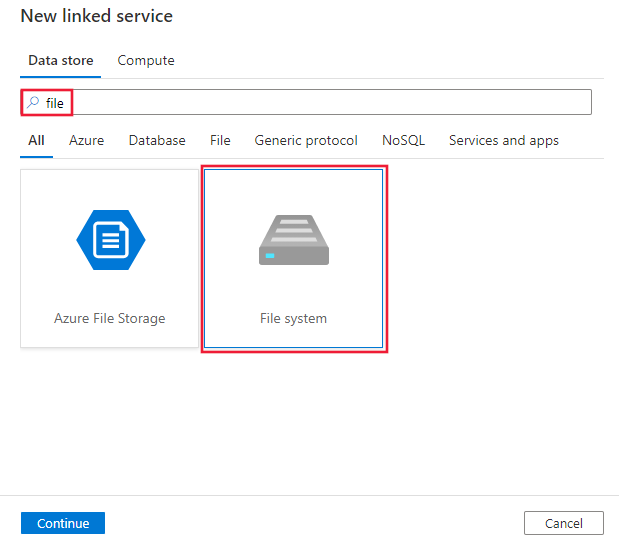
配置服务详细信息、测试连接并创建新的链接服务。
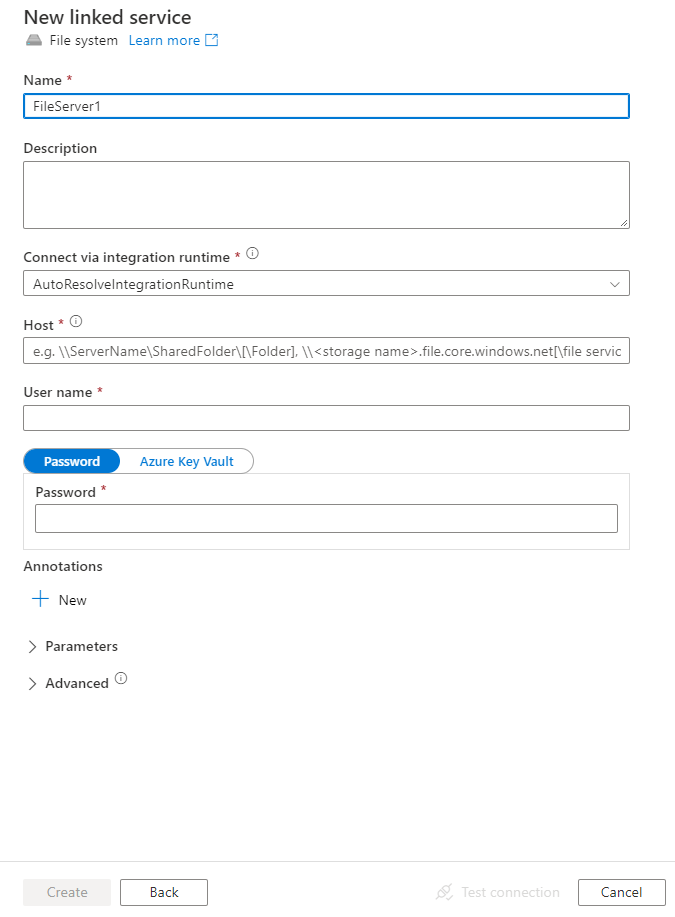
连接器配置详细信息
对于特定于文件系统的数据工厂和 Synapse 管道实体,以下部分提供了有关用于定义这些实体的属性的详细信息。
链接服务属性
文件系统链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为:FileServer。 | 是 |
| host | 指定要复制的文件夹的根路径。 请对字符串中的特殊字符使用转义符“”。 有关示例,请参阅 Sample linked service and dataset definitions(链接服务和数据集定义示例)。 | 是 |
| userId | 指定有权访问服务器的用户的 ID。 | 是 |
| password | 指定用户的密码 (userId)。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 | 是 |
| connectVia | 用于连接到数据存储的集成运行时。 在先决条件部分了解更多信息。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
链接服务和数据集定义示例
| 方案 | 链接服务定义中的“主机” | 数据集定义中的“folderPath” |
|---|---|---|
| 远程共享文件夹: 示例:\\myserver\share\* 或 \\myserver\share\folder\subfolder\* |
在 JSON 中:\\\\myserver\\share在 UI 上: \\myserver\share |
在 JSON 中:.\\ 或 folder\\subfolder在 UI 上: .\ 或 folder\subfolder |
注意
通过 UI 创作时,无需输入双反斜杠 (\\) 即可转义就像通过 JSON 操作一样,请指定单个反斜杠。
备注
Azure Integration Runtime 不支持从本地计算机复制文件。
请参阅此处的命令行,以启用对自承载集成运行时下本地计算机的访问。 默认禁用此功能。
示例:
{
"name": "FileLinkedService",
"properties": {
"type": "FileServer",
"typeProperties": {
"host": "<host>",
"userId": "<domain>\\<user>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
在基于格式的数据集中的 location 设置下,文件系统支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 数据集中 location 下的 type 属性必须设置为 FileServerLocation。 |
是 |
| folderPath | 文件夹的路径。 如果要使用通配符筛选文件夹,请跳过此设置并在活动源设置中指定。 需要在 Windows 或 Linux 环境中设置文件共享位置,以公开要共享的文件夹。 | 否 |
| fileName | 给定 folderPath 下的文件名。 如果要使用通配符筛选文件,请跳过此设置并在活动源设置中指定。 | 否 |
示例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<File system linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "FileServerLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
复制活动属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供文件系统源和接收器支持的属性列表。
文件系统作为源
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
在基于格式的复制源中的 storeSettings 设置下,文件系统支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | storeSettings 下的 type 属性必须设置为 FileServerReadSettings。 |
是 |
| 找到要复制的文件: | ||
| 选项 1:静态路径 |
从数据集中指定的给定文件夹/文件路径复制。 若要复制文件夹中的所有文件,请另外将 wildcardFileName 指定为 *。 |
|
| 选项 2:服务器端筛选器 - fileFilter |
文件服务器端原生筛选器,与选项 3 通配符筛选器相比,该筛选器可提供更好的性能。 使用 * 匹配零个或零个以上的字符,使用 ? 匹配零个或单个字符。 若要详细了解语法和说明,请参阅此部分下的“备注”。 |
否 |
| 选项 3:客户端筛选器 - wildcardFolderPath |
带有通配符的文件夹路径,用于筛选源文件夹。 此类筛选在服务内进行,该服务枚举给定路径下的文件夹/文件,然后应用通配符筛选器。 允许的通配符为: *(匹配零个或更多个字符)和 ?(匹配零个或单个字符);如果实际文件夹名称中包含通配符或此转义字符,请使用 ^ 进行转义。 请参阅文件夹和文件筛选器示例中的更多示例。 |
否 |
| 选项 3:客户端筛选器 - wildcardFileName |
给定 folderPath/wildcardFolderPath 下带有通配符的文件名,用于筛选源文件。 此类筛选在服务内部进行,此操作会枚举给定路径下的文件,然后应用通配符筛选器。 允许的通配符为: *(匹配零个或更多个字符)和 ?(匹配零个或单个字符);如果实际文件名中包含通配符或此转义字符,请使用 ^ 进行转义。请参阅文件夹和文件筛选器示例中的更多示例。 |
是 |
| 选项 3:文件列表 - fileListPath |
指明复制给定文件集。 指向包含要复制的文件列表的文本文件,每行一个文件(即数据集中所配置路径的相对路径)。 使用此选项时,请不要在数据集中指定文件名。 请参阅文件列表示例中的更多示例。 |
否 |
| 其他设置: | ||
| recursive | 指示是要从子文件夹中以递归方式读取数据,还是只从指定的文件夹中读取数据。 当 recursive 设置为 true 且接收器是基于文件的存储时,将不会在接收器上复制或创建空的文件夹或子文件夹。 允许的值为 true(默认值)和 false。 如果配置 fileListPath,则此属性不适用。 |
否 |
| deleteFilesAfterCompletion | 指示是否会在二进制文件成功移动到目标存储后将其从源存储中删除。 文件删除以每文件为单位。 这意味着,当活动失败后,你会看到一些文件已复制到目标并从源中删除,而其他文件仍保留在源存储中。 此属性仅在二进制文件复制方案中有效。 默认值:false。 |
否 |
| modifiedDatetimeStart | 基于属性“上次修改时间”的文件筛选器。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间将以 YYYY-MM-DDTHH:mm:ssZ 格式应用于 UTC 时区。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。如果配置 fileListPath,则此属性不适用。 |
否 |
| modifiedDatetimeEnd | 与 modifiedDateTimeStart 相同。 | 否 |
| enablePartitionDiscovery | 对于已分区的文件,请指定是否从文件路径分析分区,并将它们添加为附加的源列。 允许的值为 false(默认)和 true 。 |
否 |
| partitionRootPath | 启用分区发现时,请指定绝对根路径,以便将已分区文件夹读取为数据列。 如果未指定,则默认为 - 在数据集或源的文件列表中使用文件路径时,分区根路径是在数据集中配置的路径。 - 使用通配符文件夹筛选器时,分区根路径是第一个通配符前面的子路径。 例如,假设你将数据集中的路径配置为“root/folder/year=2020/month=08/day=27”: - 如果将分区根路径指定为“root/folder/year=2020”,则除了文件内的列外,复制活动还会生成另外两列 month 和 day,其值分别为“08”和“27”。- 如果未指定分区根路径,不会生成额外的列。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "FileServerReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
文件系统作为接收器
Azure 数据工厂支持以下文件格式。 请参阅每一篇介绍基于格式的设置的文章。
注意
MergeFiles copyBehavior 选项仅在 Azure 数据工厂管道中提供,Synapse Analytics 管道不提供。
在基于格式的复制接收器中的 storeSettings 设置下,文件系统支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | storeSettings 下的 type 属性必须设置为 FileServerWriteSettings。 |
是 |
| copyBehavior | 定义以基于文件的数据存储中的文件为源时的复制行为。 允许值包括: - PreserveHierarchy(默认):将文件层次结构保留到目标文件夹中。 从源文件到源文件夹的相对路径与从目标文件到目标文件夹的相对路径相同。 - FlattenHierarchy:源文件夹中的所有文件都位于目标文件夹的第一级中。 目标文件具有自动生成的名称。 - MergeFiles:将源文件夹中的所有文件合并到一个文件中。 如果指定了文件名,则合并文件的名称为指定名称。 否则,它是自动生成的文件名。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "FileServerWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
文件夹和文件筛选器示例
本部分介绍使用通配符筛选器生成文件夹路径和文件名的行为。
| folderPath | fileName | recursive | 源文件夹结构和筛选器结果(用粗体表示的文件已检索) |
|---|---|---|---|
Folder* |
(为空,使用默认值) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(为空,使用默认值) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
是 | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
文件列表示例
本部分介绍了在复制活动源中使用文件列表路径时的结果行为。
假设有以下源文件夹结构,并且要复制加粗显示的文件:
| 示例源结构 | FileListToCopy.txt 中的内容 | 管道配置 |
|---|---|---|
| root FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv 元数据 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
在数据集中: - 文件夹路径: root/FolderA在复制活动源中: - 文件列表路径: root/Metadata/FileListToCopy.txt 文件列表路径指向同一数据存储中的文本文件。 它包含要复制的文件的列表。 每行都包含基于数据集中所配置根路径的文件的相对路径。 |
recursive 和 copyBehavior 示例
本节介绍了将 recursive 和 copyBehavior 值进行不同组合所产生的复制操作行为。
| recursive | copyBehavior | 源文件夹结构 | 生成目标 |
|---|---|---|---|
| true | preserveHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用与源相同的结构创建目标文件夹 Folder1: Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5。 |
| 是 | flattenHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标 Folder1: Folder1 File1 的自动生成的名称 File2 的自动生成的名称 File3 的自动生成的名称 File4 的自动生成的名称 File5 的自动生成的名称 |
| 是 | mergeFiles | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标 Folder1: Folder1 File1 + File2 + File3 + File4 + File 5 的内容将合并到一个文件中,且自动生成文件名 |
| false | preserveHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标文件夹 Folder1 Folder1 文件 1 文件 2 没有选取包含 File3、File4 和 File5 的 Subfolder1。 |
| false | flattenHierarchy | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标文件夹 Folder1 Folder1 File1 的自动生成的名称 File2 的自动生成的名称 不会选取包含 File3、File4 和 File5 的 Subfolder1。 |
| false | mergeFiles | Folder1 文件 1 文件 2 Subfolder1 File3 File4 File5 |
使用以下结构创建目标文件夹 Folder1 Folder1 File1 + File2 的内容将合并到一个文件中,且自动生成文件名。 File1 的自动生成的名称 没有选取包含 File3、File4 和 File5 的 Subfolder1。 |
查找活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
GetMetadata 活动属性
若要了解有关属性的详细信息,请查看 GetMetadata 活动。
Delete 活动属性
若要了解有关属性的详细信息,请查看删除活动。
旧模型
注意
仍按原样支持以下模型,以实现向后兼容性。 建议使用上面几个部分中提到的新模型,并且创作 UI 已切换为生成新模型。
旧数据集模型
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 数据集的 type 属性必须设置为:FileShare | 是 |
| folderPath | 文件夹路径。 支持通配符筛选器。 允许的通配符为:*(匹配零个或更多个字符)和 ?(匹配零个或单个字符);如果实际文件夹名称中包含通配符或此转义字符,请使用 ^ 进行转义。 示例:“rootfolder/subfolder/”,请参阅示例链接服务和数据集定义和文件夹和文件筛选器示例中的更多示例。 |
否 |
| fileName | 指定的“folderPath”下的文件的“名称或通配符筛选器”。 如果没有为此属性指定任何值,则数据集会指向文件夹中的所有文件。 对于筛选器,允许的通配符为: *(匹配零个或更多字符)和 ?(匹配零个或单个字符)。- 示例 1: "fileName": "*.csv"- 示例 2: "fileName": "???20180427.txt"如果实际文件名内具有通配符或此转义符,请使用 ^ 进行转义。如果没有为输出数据集指定 fileName,并且没有在活动接收器中指定 preserveHierarchy,则复制活动会自动生成采用以下模式的文件名称:“Data.[活动运行 ID GUID].[GUID (如果为 FlattenHierarchy)].[格式(如果已配置)].[压缩(如果已配置)]”,例如“Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz”;如果使用表名(而不是查询)从表格源进行复制,则名称模式为“[表名].[格式].[压缩(如果已配置)]”,例如“MyTable.csv”。 |
否 |
| modifiedDatetimeStart | 基于属性“上次修改时间”的文件筛选器。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间将以 YYYY-MM-DDTHH:mm:ssZ 格式应用于 UTC 时区。 请注意,当你要从大量文件中进行文件筛选时,启用此设置将影响数据移动的整体性能。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。 |
否 |
| modifiedDatetimeEnd | 基于属性“上次修改时间”的文件筛选器。 如果文件的上次修改时间大于或等于 modifiedDatetimeStart 并且小于 modifiedDatetimeEnd,则会选择这些文件。 该时间应用于 UTC 时区,格式为“2018-12-01T05:00:00Z”。 请注意,当你要从大量文件中进行文件筛选时,启用此设置将影响数据移动的整体性能。 属性可以为 NULL,这意味着不向数据集应用任何文件特性筛选器。 如果 modifiedDatetimeStart 具有日期/时间值,但 modifiedDatetimeEnd 为 NULL,则意味着将选中“上次修改时间”属性大于或等于该日期/时间值的文件。 如果 modifiedDatetimeEnd 具有日期/时间值,但 modifiedDatetimeStart 为 NULL,则意味着将选中“上次修改时间”属性小于该日期/时间值的文件。 |
否 |
| format | 如果想要在基于文件的存储之间按原样复制文件(二进制副本),可以在输入和输出数据集定义中跳过格式节。 若要分析或生成具有特定格式的文件,以下是受支持的文件格式类型:TextFormat、JsonFormat、AvroFormat、OrcFormat、ParquetFormat 。 请将格式中的“type”属性设置为上述值之一。 有关详细信息,请参阅文本格式、Json 格式、Avro 格式、Orc 格式和 Parquet 格式部分。 |
否(仅适用于二进制复制方案) |
| compression | 指定数据的压缩类型和级别。 有关详细信息,请参阅受支持的文件格式和压缩编解码器。 支持的类型包括:GZip、Deflate、BZip2 和 ZipDeflate。 支持的级别为:“最佳”和“最快” 。 |
否 |
提示
如需复制文件夹下的所有文件,请仅指定 folderPath。
如需复制具有给定名称的单个文件,请使用文件夹部分指定 folderPath 并使用文件名指定 fileName。
如需复制文件夹下的文件子集,请指定文件夹部分的 folderPath 和通配符筛选器部分的 fileName。
注意
如果文件筛选器使用“fileFilter”属性,则在建议你今后使用添加到“fileName”的新筛选器功能时,仍按原样支持该属性。
示例:
{
"name": "FileSystemDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<file system linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
旧复制活动源模型
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动 source 的 type 属性必须设置为:FileSystemSource | 是 |
| recursive | 指示是要从子文件夹中以递归方式读取数据,还是只从指定的文件夹中读取数据。 请注意,如果将递归设置为 true,并且接收器是基于文件的存储,则不会在接收器上复制/创建空文件夹/子文件夹。 允许的值为:true(默认)、false |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<file system input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
旧复制活动接收器模型
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动接收器的 type 属性必须设置为:FileSystemSink | 是 |
| copyBehavior | 定义以基于文件的数据存储中的文件为源时的复制行为。 允许值包括: - PreserveHierarchy(默认值):保留目标文件夹中的文件层次结构。 从源文件到源文件夹的相对路径与从目标文件到目标文件夹的相对路径相同。 - FlattenHierarchy:源文件夹中的所有文件都位于目标文件夹的第一级。 目标文件名是自动生成的。 - MergeFiles:将源文件夹中的所有文件合并到一个文件中。 合并过程中不执行记录重复数据删除。 如果指定文件名,则合并的文件名将为指定的名称;否则,会自动生成文件名。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
示例:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<file system output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储。