你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 数据工厂和 Azure Synapse Analytics 中的数据集
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本文介绍了数据集的涵义,采用 JSON 格式定义数据集的方式以及数据集在 Azure Data Factory 和 Synapse 管道中的用法。
如果对数据工厂不熟悉,请参阅 Azure 数据工厂简介了解相关概述。 有关 Azure Synapse 的详细信息,请参阅什么是 Azure Synapse
概述
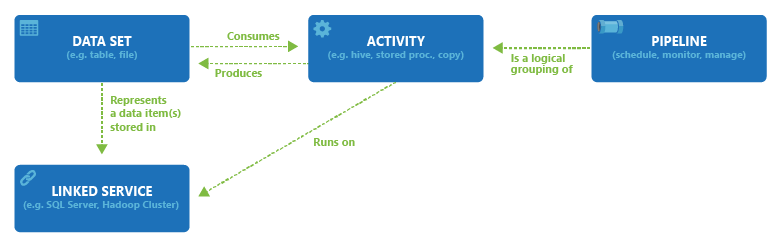
一个 Azure 数据工厂或 Synapse 工作区可以有一个或多个管道。 “管道”是共同执行一项任务的活动的逻辑分组。 管道中的活动定义对数据执行的操作。 现在,数据集这一名称的意义已经变为看待数据的一种方式,就是以输入和输出的形式指向或引用活动中要使用的数据 。 数据集可识别不同数据存储(如表、文件、文件夹和文档)中的数据。 例如,Azure Blob 数据集可在 Blob 存储中指定供活动读取数据的 Blob 容器和文件夹。
创建数据集之前,必须创建链接服务,将数据存储链接到服务。 链接的服务类似于连接字符串,它定义服务连接到外部资源时所需的连接信息。 不妨这样考虑:数据集代表链接的数据存储中的数据结构,而链接服务则定义到数据源的连接。 例如,Azure 存储链接服务可链接一个存储帐户。 Azure Blob 数据集表示该 Azure 存储帐户中包含要处理的输入 Blob 的 Blob 容器和文件夹。
下面是一个示例方案。 要将数据从 Blob 存储复制到 SQL 数据库,请创建以下两个链接服务:Azure Blob 存储和 Azure SQL 数据库。 然后创建两个数据集:带分隔符的文本数据集(假设将文本文件作为源,则它指的是 Azure Blob 存储链接服务)和 Azure SQL 表数据集(即 Azure SQL 数据库链接服务)。 Azure Blob 存储和 Azure SQL 数据库链接服务分别包含服务在运行时用于连接到 Azure 存储和 Azure SQL 数据库的连接字符串。 带分隔符的文本数据集指定 blob 容器和 blob 文件夹,该文件夹包含 Blob 存储中的输入 blob 以及与格式相关的设置。 Azure SQL 表数据集指定你的 SQL 数据库中要将数据复制到其中的 SQL 表。
下图显示了管道、活动、数据集和链接服务之间的关系:
使用 UI 创建数据集
若要使用 Azure 数据工厂工作室创建数据集,请选择“作者”选项卡(带有铅笔图标),然后选择加号图标,以选择“数据集”。
你将看到新的数据集窗口,可在其中选择 Azure 数据工厂中可用的任何连接器,以设置现有或新的链接服务。
接下来,系统将提示你选择数据集格式。

最后,可以选择为数据集选择类型的现有链接服务,或者创建一个新链接服务(如果尚未定义)。
创建数据集后,可以在 Azure 数据工厂的任何管道中使用。
数据集 JSON
采用以下 JSON 格式定义数据集:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
下表描述了上述 JSON 中的属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| name | 数据集名称。 请参见命名规则。 | 是 |
| type | 数据集的类型。 指定数据工厂支持的类型之一(例如:DelimitedText、AzureSqlTable)。 有关详细信息,请参阅数据集类型。 |
是 |
| 架构 | 数据集的架构表示物理数据类型和形状。 | 否 |
| typeProperties | 每种类型的类型属性各不相同。 若要详细了解受支持的类型及其属性,请参阅数据集类型。 | 是 |
导入数据集的架构时,请选择“导入架构”按钮,然后选择从源或本地文件导入。 在大多数情况下,将直接从源导入架构。 但是,如果已有本地架构文件(Parquet 文件或带标头的 CSV),则可以指示服务根据该文件定义架构。
在复制活动中,数据集用于源和接收器。 数据集中定义的架构可选作引用。 如果要在源和接收器之间应用列/字段映射,请参阅架构和类型映射。
在数据流中,数据集用于源和接收器转换。 数据集定义基本数据架构。 如果数据没有架构,则可以对源和接收器使用架构偏差。 来自数据集的元数据在源转换中显示为源投影。 源转换中的投影表示定义了名称和类型的数据流数据。
数据集类型
服务支持多种数据集类型,具体取决于使用的数据存储。 有关支持的数据存储列表,可参阅连接器概述一文。 选择数据存储,了解如何创建链接服务及其数据集。
例如,对于带分隔符的文本数据集,数据集类型设为“DelimitedText”,如下方的 JSON 示例所示:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
注意
架构值是使用 JSON 语法定义的。 有关架构映射和数据类型映射的更多详细信息,请参阅 Azure 数据工厂复制活动架构和类型映射文档。
创建数据集
可以使用以下任一工具或 SDK 创建数据集:.NET API、PowerShell、REST API、Azure 资源管理器模板和 Azure 门户
当前版本与版本 1 数据集的比较
以下是数据工厂当前版本(以及 Azure Synapse)中的数据集与旧版数据工厂版本 1 中的数据集之间的一些差异:
相关内容
快速入门
请参阅以下教程,了解使用下列某个工具或 SDK 创建管道和数据集的分步说明。