你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 数据工厂和 Synapse Analytics 中支持的文件格式和压缩编解码器(旧版)
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本文适用于以下连接器:Amazon S3、Azure Blob、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure 文件存储、文件系统、FTP、Google 云存储、HDFS、HTTP 和 SFTP。
重要
服务引入了基于新格式的数据集模型,有关详细信息,请参阅对应格式的文章:
-
Avro 格式
-
二进制格式
-
带分隔符的文本格式
-
JSON 格式
-
ORC 格式
-
Parquet 格式
依旧按原样支持本文中提到的其余配置,以实现后向兼容性。 建议你今后使用新模型。
文本格式(旧版)
注意
从带分隔符的文本格式一文中了解新模型。 依旧按原样支持基于文件的数据存储数据集的以下配置,以实现后向兼容性。 建议你今后使用新模型。
如果想要读取或写入某个文本文件,请将数据集的 format 节中的 type 属性设置为 TextFormat。 也可在 format 节指定以下可选属性。 请参阅 TextFormat 示例部分,了解如何进行配置。
| 属性 | 说明 | 允许的值 | 必须 |
|---|---|---|---|
| columnDelimiter | 用于分隔文件中的列的字符。 可以考虑使用数据中可能不存在的极少见的不可打印字符。 例如,指定“\u0001”表示标题开头 (SOH)。 | 只能使用一个字符。
默认值为逗号(“,”) 。 若要使用 Unicode 字符,请参阅 Unicode 字符获取相应的代码。 |
否 |
| rowDelimiter | 用于分隔文件中的行的字符。 | 只能使用一个字符。 默认值为以下任何一项: [“\r\n”、“\r”、“\n”] (读取时)和 “\r\n” (写入时)。 | 否 |
| escapeChar | 用于转义输入文件内容中的列分隔符的特殊字符。 不能同时指定表的 escapeChar 和 quoteChar。 |
只能使用一个字符。 没有默认值。 示例:如果使用逗号 (',') 作为列分隔符,但希望在文本中包含逗号字符(例如:“Hello, world”),可以将“$”定义为转义字符,并在源代码中使用字符串“Hello$, world”。 |
否 |
| quoteChar | 将字符串值用引号括起来的字符。 引号字符内的列和行分隔符将被视为字符串值的一部分。 此属性适用于输入和输出数据集。 不能同时指定表的 escapeChar 和 quoteChar。 |
只能使用一个字符。 没有默认值。 例如,如果以逗号(“,”)作为列分隔符,但想要在文本中使用逗号字符(例如:<Hello, world>),可以将 "(双引号)定义为引号字符,在源中使用字符串“Hello, world”。 |
否 |
| nullValue | 用于表示 null 值的一个或多个字符。 | 一个或多个字符。 默认值为 “\N”和“NULL” (读取时)及 “\N” (写入时)。 | 否 |
| encodingName | 指定编码名称。 | 有效的编码名称。 请参阅 Encoding.EncodingName 属性。 例如:windows-1250 或 shift_jis。 默认值为 UTF-8。 | 否 |
| firstRowAsHeader | 指定是否将第一行视为标头。 对于输入数据集,服务将读取第一行作为标头。 对于输出数据集,服务将写入第一行作为标头。 有关示例方案,请参阅 firstRowAsHeader 和 skipLineCount 使用方案。 |
True False(默认值) |
否 |
| skipLineCount | 指示从输入文件读取数据时要跳过的非空行数 。 如果同时指定了 skipLineCount 和 firstRowAsHeader,则先跳过行,然后从输入文件读取标头信息。 有关示例方案,请参阅 firstRowAsHeader 和 skipLineCount 使用方案。 |
Integer | 否 |
| treatEmptyAsNull | 指定是否在从输入文件读取数据时将 null 或空字符串视为 null 值。 |
True(默认值) False |
否 |
TextFormat 示例
在某个数据集的以下 JSON 定义中,指定了一些可选属性。
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
要使用 escapeChar 而非 quoteChar,请将 quoteChar 所在的行替换为以下 escapeChar:
"escapeChar": "$",
firstRowAsHeader 和 skipLineCount 的使用方案
- 要从非文件源复制到文本文件,并想要添加包含架构元数据的标头行(例如:SQL 架构)。 对于此方案,请在输出数据集中将
firstRowAsHeader指定为 true。 - 要从包含标头行的文本文件复制到非文件接收器,并想要删除该行。 请在输入数据集中将
firstRowAsHeader指定为 true。 - 要从文本文件复制,并想跳过不包含数据或标头信息的开头几行。 通过指定
skipLineCount指明要跳过的行数。 如果文件的剩余部分包含标头行,则也可指定firstRowAsHeader。 如果同时指定了skipLineCount和firstRowAsHeader,则先跳过代码行,然后从输入文件读取标头信息
JSON 格式(旧版)
注意
从 JSON 格式一文中了解新模型。 依旧按原样支持基于文件的数据存储数据集的以下配置,以实现后向兼容性。 建议你今后使用新模型。
若要在 Azure Cosmos DB 中按原样导入/导出 JSON 文件,请参阅将数据移入/移出 Azure Cosmos DB 一文中的“导入/导出 JSON 文档”部分。
要分析 JSON 文件或以 JSON 格式写入数据,请将 format 节中的 type 属性设置为 JsonFormat。 也可在 format 节指定以下可选属性。 请参阅 JsonFormat 示例部分,了解如何进行配置。
| 属性 | 描述 | 必须 |
|---|---|---|
| filePattern | 指示每个 JSON 文件中存储的数据模式。 允许的值为:setOfObjects 和 arrayOfObjects。 默认值为 setOfObjects。 请参阅 JSON 文件模式部分,详细了解这些模式。 | 否 |
| jsonNodeReference | 若要进行迭代操作,以同一模式从数组字段中的对象提取数据,请指定该数组的 JSON 路径。 只有从 JSON 文件复制数据时,才支持此属性。 | 否 |
| jsonPathDefinition | 为每个使用自定义列名映射的列指定 JSON 路径表达式(开头为小写)。 只有从 JSON 文件复制数据时,才支持此属性,而且用户可以从对象或数组提取数据。 对于根对象下的字段,请以根 $ 开头;对于按 jsonNodeReference 属性选择的数组中的字段,请以数组元素开头。 请参阅 JsonFormat 示例部分,了解如何进行配置。 |
否 |
| encodingName | 指定编码名称。 有关有效编码名称的列表,请参阅:Encoding.EncodingName 属性。 例如:windows-1250 或 shift_jis。 默认值为 :UTF-8。 | 否 |
| nestingSeparator | 用于分隔嵌套级别的字符。 默认值为“.”(点)。 | 否 |
注意
对于将数组中的数据交叉应用到多行的情况(案例 1 ->JsonFormat 示例中的示例 2),只能选择使用属性 jsonNodeReference 展开单个数组。
JSON 文件模式
复制活动可分析以下 JSON 文件模式:
类型 I:setOfObjects
每个文件包含单个对象,或者以行分隔/串连的多个对象。 在输出数据集中选择此选项时,复制活动将生成单个 JSON 文件,其中每行包含一个对象(以行分隔)。
单一对象 JSON 示例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }行分隔的 JSON 示例
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}串连的 JSON 示例
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
类型 II:arrayOfObjects
每个文件包含对象的数组。
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
JsonFormat 示例
案例 1:从 JSON 文件复制数据
示例 1:从对象和数组中提取数据
在此示例中,预期要将一个根 JSON 对象映射到表格结果中的单个记录。 如果 JSON 文件包含以下内容:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
并且你想要通过从对象和数组中提取数据,使用以下格式将该文件复制到 Azure SQL 表:
| ID | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
JsonFormat 类型的输入数据集定义如下(部分定义,仅包含相关部件)。 更具体地说:
-
structure节定义自定义列名以及在转换为表格数据时的相应数据类型。 本节为可选,除非需要进行列映射。 有关详细信息,请参阅将源数据集列映射到目标数据集列。 -
jsonPathDefinition为每个列指定 JSON 路径,表明从何处提取数据。 若要从数组中复制数据,可以使用array[x].property从xth对象中提取给定属性的值,或者使用array[*].property从包含此类属性的任何对象中查找该值。
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
示例 2:使用数组中的相同模式交叉应用多个对象
在此示例中,预期要将一个根 JSON 对象转换为表格结果中的多个记录。 如果 JSON 文件包含以下内容:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
而用户需要按以下格式通过平展数组中数据的方式将其复制到 Azure SQL 表中,并使用常见的根信息进行交叉联接:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
JsonFormat 类型的输入数据集定义如下(部分定义,仅包含相关部件)。 更具体地说:
-
structure节定义自定义列名以及在转换为表格数据时的相应数据类型。 本节为可选,除非需要进行列映射。 有关详细信息,请参阅将源数据集列映射到目标数据集列。 -
jsonNodeReference指示在数组orderlines下以同一模式从对象中循环访问数据并提取数据。 -
jsonPathDefinition为每个列指定 JSON 路径,表明从何处提取数据。 在以下示例中,ordernumber、orderdate和city位于 JSON 路径以“$.”开头的根对象下,而order_pd和order_price在定义时使用的路径派生自没有“$.”的数组元素。
"properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
请注意以下几点:
- 如果未在数据集中定义
structure和jsonPathDefinition,复制活动将检测第一个对象的架构,并平展整个对象。 - 如果 JSON 输入包含数组,则默认情况下,复制活动会将整个数组值转换为字符串。 可以选择使用
jsonNodeReference和/或jsonPathDefinition通过它提取数据,也可以不在jsonPathDefinition中指定它,从而将它跳过。 - 如果同一级别存在重复的名称,复制活动将选择最后一个名称。
- 属性名称区分大小写。 名称相同但大小写不同的两个属性被视为两个不同的属性。
案例 2:将数据写入 JSON 文件
如果 SQL 数据库中存在以下表:
| ID | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
每个记录将按以下格式写入到 JSON 对象中:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
JsonFormat 类型的输出数据集定义如下(部分定义,仅包含相关部件)。 更具体说来,structure 节用于定义目标文件中的自定义属性名称,nestingSeparator(默认为“.”)则用于标识名称中的嵌套层。 本节为可选,除非需要将属性名称更改为与源列名不同的名称,或者需要嵌套部分属性。
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Parquet 格式(旧版)
注意
从 Parquet 格式一文中了解新模型。 依旧按原样支持基于文件的数据存储数据集的以下配置,以实现后向兼容性。 建议你今后使用新模型。
若要分析 Parquet 文件或以 Parquet 格式写入数据,请将 formattype 属性设置为 ParquetFormat。 不需在 typeProperties 节的 Format 节中指定任何属性。 示例:
"format":
{
"type": "ParquetFormat"
}
请注意以下几点:
- 不支持复杂数据类型(MAP、LIST)。
- 不支持列名称中的空格。
- Parquet 文件提供以下压缩相关的选项:NONE、SNAPPY、GZIP 和 LZO。 该服务支持以这些压缩格式中的任意一种格式从 Parquet 文件中读取数据 - 但 LZO 格式除外,它使用元数据中的压缩编解码器来读取数据。 但是,写入 Parquet 文件时,服务会选择 SNAPPY,这是 Parquet 格式的默认选项。 目前没有任何选项可以重写此行为。
重要
对于由自承载集成运行时(例如,在本地与云数据存储之间)支持的复制,如果不是按原样复制 Parquet 文件,则需要在 IR 计算机上安装 64 位 JRE 8(Java 运行时环境)或 OpenJDK。 请参阅下面段落中的更多详细信息。
对于使用 Parquet 文件序列化/反序列化在自承载集成运行时上运行的复制,该服务将通过首先检查 JRE 的注册表项 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) 来查找 Java 运行时,如果未找到,则会检查系统变量 JAVA_HOME 来查找 OpenJDK。
- 若要使用 JRE:64 位 IR 需要 64 位 JRE。 可在此处找到它。
- 若要使用 OpenJDK:从 IR 版本 3.13 开始受支持。 将 jvm.dll 以及所有其他必需的 OpenJDK 程序集打包到自承载 IR 计算机中,并相应地设置系统环境变量 JAVA_HOME。
提示
如果使用自承载集成运行时将数据复制为 Parquet 格式或从 Parquet 格式复制数据,并遇到“调用 java 时发生错误,消息: java.lang.OutOfMemoryError:Java 堆空间”的错误,则可以在托管自承载 IR 的计算机上添加环境变量 _JAVA_OPTIONS,以便调整 JVM 的最小/最大堆大小,以支持此类复制,然后重新运行管道 。
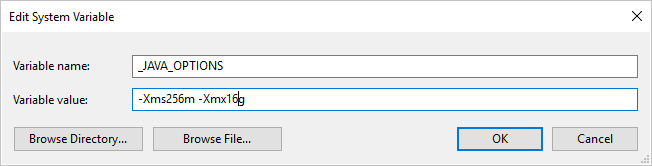
示例:将变量 _JAVA_OPTIONS 的值设置为 -Xms256m -Xmx16g。 标志 Xms 指定 Java 虚拟机 (JVM) 的初始内存分配池,而 Xmx 指定最大内存分配池。 这意味着 JVM 初始内存为 Xms,并且能够使用的最多内存为 Xmx。 默认情况下,该服务最少使用 64 MB 且最多使用 1 G。
Parquet 文件的数据类型映射
| 临时服务数据类型 | Parquet 基元类型 | Parquet 原始类型(反序列化) | Parquet 原始类型(串行化) |
|---|---|---|---|
| 布尔 | 布尔 | 空值 | 空值 |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/二进制 | UInt64 | 小数 |
| Single | Float | 空值 | 空值 |
| Double | Double | 空值 | 空值 |
| 小数 | 二进制 | 小数 | 小数 |
| String | 二进制 | Utf8 | Utf8 |
| DateTime | Int96 | 空值 | 空值 |
| TimeSpan | Int96 | 空值 | 空值 |
| DateTimeOffset | Int96 | 空值 | 空值 |
| ByteArray | 二进制 | 空值 | 空值 |
| Guid | 二进制 | Utf8 | Utf8 |
| Char | 二进制 | Utf8 | Utf8 |
| CharArray | 不支持 | 空值 | 不可用 |
ORC 格式(旧版)
注意
从 ORC 格式一文了解中新模型。 依旧按原样支持基于文件的数据存储数据集的以下配置,以实现后向兼容性。 建议你今后使用新模型。
若要分析 ORC 文件或以 ORC 格式写入数据,请将 formattype 属性设置为 OrcFormat。 不需在 typeProperties 节的 Format 节中指定任何属性。 示例:
"format":
{
"type": "OrcFormat"
}
请注意以下几点:
- 不支持复杂数据类型(STRUCT、MAP、LIST、UNION)。
- 不支持列名称中的空格。
- ORC 文件有三个压缩相关的选项:NONE、ZLIB、SNAPPY。 该服务支持从使用其中任一压缩格式的 ORC 文件中读取数据。 它使用元数据中的压缩编解码器来读取数据。 但是,写入 ORC 文件时,该服务会选择 ZLIB,这是 ORC 的默认选项。 目前没有任何选项可以重写此行为。
重要
对于由自承载集成运行时(例如,在本地与云数据存储之间)支持的复制,如果不是按原样复制 ORC 文件,则需要在 IR 计算机上安装 64 位 JRE 8(Java 运行时环境)或 OpenJDK。 请参阅下面段落中的更多详细信息。
对于使用 ORC 文件序列化/反序列化在自承载集成运行时上运行的复制,该服务将通过首先检查 JRE 的注册表项 (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) 来查找 Java 运行时,如果未找到,则会检查系统变量 JAVA_HOME 来查找 OpenJDK。
- 若要使用 JRE:64 位 IR 需要 64 位 JRE。 可在此处找到它。
- 若要使用 OpenJDK:从 IR 版本 3.13 开始受支持。 将 jvm.dll 以及所有其他必需的 OpenJDK 程序集打包到自承载 IR 计算机中,并相应地设置系统环境变量 JAVA_HOME。
ORC 文件的数据类型映射
| 临时服务数据类型 | ORC 类型 |
|---|---|
| 布尔 | 布尔 |
| SByte | Byte |
| Byte | Short |
| Int16 | Short |
| UInt16 | int |
| Int32 | int |
| UInt32 | Long |
| Int64 | Long |
| UInt64 | String |
| Single | Float |
| Double | Double |
| 小数 | 小数 |
| String | 字符串 |
| DateTime | Timestamp |
| DateTimeOffset | Timestamp |
| TimeSpan | Timestamp |
| ByteArray | 二进制 |
| Guid | String |
| Char | Char(1) |
AVRO 格式(旧版)
注意
从 Avro 格式一文中了解新模型。 依旧按原样支持基于文件的数据存储数据集的以下配置,以实现后向兼容性。 建议你今后使用新模型。
若要分析 Avro 文件或以 Avro 格式写入数据,请将 formattype 属性设置为 AvroFormat。 不需在 typeProperties 节的 Format 节中指定任何属性。 示例:
"format":
{
"type": "AvroFormat",
}
若要在 Hive 表中使用 Avro 格式,可以参考 Apache Hive 教程。
请注意以下几点:
- 不支持复杂数据类型(记录、枚举、数组、映射、联合与固定值)。
压缩支持(旧版)
在复制期间,该服务支持压缩/解压缩数据。 在输入数据集中指定 compression 属性时,复制活动从源读取压缩的数据并对其进行解压缩;在输出数据集中指定属性时,复制活动将压缩数据并将其写入到接收器。 下面是一些示例方案:
- 从 Azure Blob 读取 GZIP 压缩的数据,将其解压缩,然后将结果数据写入 Azure SQL 数据库。 使用值为 GZIP 的
compressiontype属性定义输入 Azure Blob 数据集。 - 从来自本地文件系统的纯文本文件读取数据、使用 GZip 格式进行压缩并将压缩的数据写入到 Azure Blob。 使用值为 GZip 的
compressiontype属性定义输出 Azure Blob 数据集。 - 从 FTP 服务器读取 .zip 文件,将它解压缩以获取文件内容,然后将这些文件加入 Azure Data Lake Store。 使用值为 ZipDeflate 的
compressiontype属性定义输入 FTP 数据集。 - 从 Azure Blob 读取 GZIP 压缩的数据,将其解压缩、使用 BZIP2 将其压缩,然后将结果数据写入 Azure Blob。 通过将
compressiontype设为 GZIP 来定义输入 Azure Blob 数据集,通过将compressiontype设为 BZIP2 来定义输出数据集。
若要为数据集指定压缩,请在数据集 JSON 中使用 compression 属性,如以下示例所示:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
compression 节包含两个属性:
Type: 压缩编解码器,可以是 GZIP、Deflate、BZIP2 或 ZipDeflate。 请注意,使用复制活动解压缩 ZipDeflate 文件并写入到基于文件的接收器数据存储时,会将文件提取到文件夹:
<path specified in dataset>/<folder named as source zip file>/。Level: 压缩比,可以是 Optimal 或 Fastest。
最快: 尽快完成压缩操作,不过,无法以最佳方式压缩生成的文件。
最佳:以最佳方式完成压缩操作,不过,需要耗费更长的时间。
有关详细信息,请参阅 Compression Level(压缩级别)主题。
注意
目前采用 AvroFormat、OrcFormat 或 ParquetFormat 的数据不支持压缩设置。 读取采用这些格式的文件时,该服务将检测并使用元数据中的压缩编解码器。 在采用这些格式的文件中写入数据时,服务将选择适用于该格式的默认压缩编解码器。 例如,为 OrcFormat 使用 ZLIB,为 ParquetFormat 使用 SNAPPY。
不支持的文件类型和压缩格式
可以使用可扩展性功能来转换不受支持的文件。 两个选项包括 Azure Functions 和使用 Azure Batch 的自定义任务。
可以看到一个示例,它使用 Azure 函数提取 tar 文件的内容。 有关详细信息,请参阅 Azure Functions 活动。
还可以使用自定义 dotnet 活动构建此功能。 更多的信息可以在这里找到
相关内容
从支持的文件格式和压缩中了解最新的受支持文件格式和压缩。