โยกย้ายเมตาดาต้า Hive Metastore จาก Azure Synapse Analytics ไปยัง Fabric
ขั้นตอนแรกในการโยกย้าย Hive Metastore (HMS) เกี่ยวข้องกับการกําหนดฐานข้อมูล ตาราง และพาร์ติชันที่คุณต้องการถ่ายโอน ไม่จําเป็นต้องโยกย้ายทุกอย่าง คุณสามารถเลือกฐานข้อมูลที่เฉพาะเจาะจงได้ เมื่อระบุฐานข้อมูลสําหรับการโยกย้าย ตรวจสอบให้แน่ใจว่ามีการจัดการหรือตาราง Spark ภายนอกหรือไม่
สําหรับข้อควรพิจารณาของ HMS โปรดดูความแตกต่างระหว่าง Azure Synapse Spark และ Fabric
หมายเหตุ
อีกวิธีหนึ่งคือ หาก ADLS Gen2 ของคุณมีตาราง Delta คุณสามารถสร้าง ทางลัด OneLake ไปยังตาราง Delta ใน ADLS Gen2 ได้
ข้อกำหนดเบื้องต้น
- ถ้าคุณยังไม่มี พื้นที่ทํางาน Fabric ในผู้เช่าของคุณ
- ถ้าคุณยังไม่มี ให้ สร้าง Fabric lakehouse ในพื้นที่ทํางานของคุณ
ตัวเลือกที่ 1: ส่งออกและนําเข้า HMS ไปยังทะเลสาบเมตาสโตร์
ทําตามขั้นตอนหลักเหล่านี้สําหรับการโยกย้าย:
- ขั้นตอนที่ 1: ส่งออกเมตาดาต้าจากแหล่งข้อมูล HMS
- ขั้นตอนที่ 2: นําเข้าเมตาดาต้าลงใน Fabric lakehouse
- ขั้นตอนหลังโยกย้าย: ตรวจสอบเนื้อหา
หมายเหตุ
สคริปต์คัดลอกวัตถุแค็ตตาล็อก Spark ไปยัง Fabric lakehouse เท่านั้น สมมติฐานคือข้อมูลถูกคัดลอกแล้ว (ตัวอย่างเช่น จากตําแหน่งคลังสินค้าไปยัง ADLS Gen2) หรือพร้อมใช้งานสําหรับตารางที่มีการจัดการและภายนอก (ตัวอย่างเช่นผ่านทางลัด—ที่ต้องการ) ลงใน Fabric lakehouse
ขั้นตอนที่ 1: ส่งออกเมตาดาต้าจากแหล่งข้อมูล HMS
จุดมุ่งเน้นของขั้นตอนที่ 1 คือการส่งออกเมตาดาต้าจากแหล่งที่มา HMS ไปยังส่วนไฟล์ของ Fabric lakehouse ของคุณ กระบวนการนี้มีดังนี้:
1.1) นําเข้าเมตาดาต้าส่งออก HMS ลงในพื้นที่ทํางาน Azure Synapse ของคุณ สมุดบันทึก นี้จะคิวรีและส่งออกเมตาดาต้า HMS ของฐานข้อมูล ตาราง และพาร์ติชันไปยังไดเรกทอรีระดับกลางใน OneLake (ยังไม่รวมฟังก์ชัน) แค็ตตาล็อก API ภายใน Spark ถูกใช้ในสคริปต์นี้เพื่ออ่านออบเจ็กต์แค็ตตาล็อก
1.2) กําหนดค่าพารามิเตอร์ ในคําสั่งแรกเพื่อส่งออกข้อมูลเมตาดาต้าไปยังที่เก็บข้อมูลระดับกลาง (OneLake) ส่วนย่อยต่อไปนี้ถูกใช้เพื่อกําหนดค่าพารามิเตอร์ต้นทางและปลายทาง ตรวจสอบให้แน่ใจว่าได้แทนที่ด้วยค่าของคุณเอง
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) เรียกใช้คําสั่ง สมุดบันทึกทั้งหมดเพื่อส่งออกวัตถุแค็ตตาล็อกไปยัง OneLake เมื่อเซลล์เสร็จสมบูรณ์ โครงสร้างโฟลเดอร์นี้ภายใต้ไดเรกทอรีผลลัพธ์ระดับกลางจะถูกสร้างขึ้น
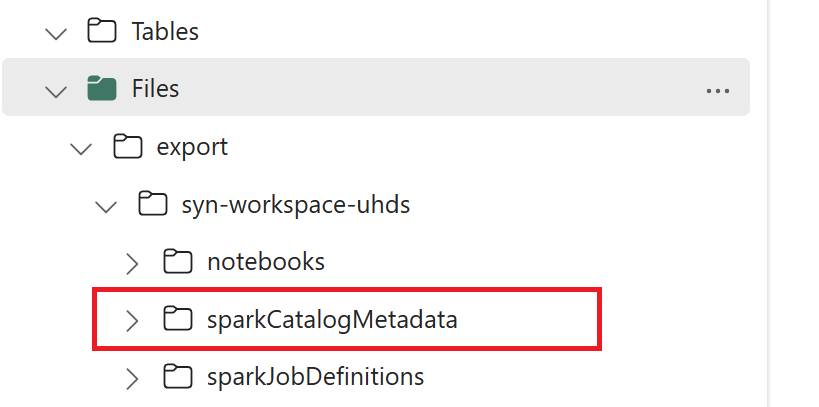
ขั้นตอนที่ 2: นําเข้าเมตาดาต้าลงใน Fabric lakehouse
ขั้นตอนที่ 2 คือเมื่อมีการนําเข้าเมตาดาต้าจริงจากที่เก็บข้อมูลระดับกลางลงใน Fabric lakehouse ผลลัพธ์ของขั้นตอนนี้คือการโยกย้ายเมตาดาต้า HMS (ฐานข้อมูล ตาราง และพาร์ติชัน) ทั้งหมด กระบวนการนี้มีดังนี้:
2.1) สร้างทางลัดภายในส่วน "ไฟล์" ของเลคเฮ้าส์ ทางลัดนี้ต้องชี้ไปยังไดเรกทอรีคลัง Spark ต้นทางและใช้ในภายหลังเพื่อทําการแทนที่สําหรับตารางที่มีการจัดการ Spark ดูตัวอย่างทางลัดที่ชี้ไปยังไดเรกทอรี Spark warehouse:
- เส้นทางทางลัดไปยังไดเรกทอรีคลัง Azure Synapse Spark:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - เส้นทางทางลัดไปยังไดเรกทอรีคลังข้อมูล Azure Databricks:
dbfs:/mnt/<warehouse_dir> - เส้นทางทางลัดไปยังไดเรกทอรีคลัง HDInsight Spark:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- เส้นทางทางลัดไปยังไดเรกทอรีคลัง Azure Synapse Spark:
2.2) นําเข้าเมตาดาต้า HMS นําเข้าสมุดบันทึก ไปยังพื้นที่ทํางาน Fabric ของคุณ นําเข้า สมุดบันทึก นี้เพื่อนําเข้าฐานข้อมูล ตาราง และพาร์ติชันวัตถุจากที่เก็บข้อมูลระดับกลาง แค็ตตาล็อก API ภายใน Spark ถูกใช้ในสคริปต์นี้เพื่อสร้างวัตถุแค็ตตาล็อกใน Fabric
2.3) กําหนดค่าพารามิเตอร์ ในคําสั่งแรก ใน Apache Spark เมื่อคุณสร้างตารางที่มีการจัดการ ข้อมูลสําหรับตารางนั้นจะถูกจัดเก็บไว้ในตําแหน่งที่จัดการโดย Spark เอง โดยทั่วไปจะอยู่ภายในไดเรกทอรีคลังสินค้าของ Spark ตําแหน่งที่แน่นอนจะถูกกําหนดโดย Spark ซึ่งตรงกันข้ามกับตารางภายนอกที่คุณระบุตําแหน่งที่ตั้งและจัดการข้อมูลเบื้องต้น เมื่อคุณย้ายเมตาดาต้าของตารางที่มีการจัดการแล้ว (โดยไม่ต้องย้ายข้อมูลจริง) เมตาดาต้าจะยังคงประกอบด้วยข้อมูลตําแหน่งที่ตั้งดั้งเดิมที่ชี้ไปยังไดเรกทอรีคลัง Spark เก่า ดังนั้นสําหรับตาราง
WarehouseMappingsที่มีการจัดการจะถูกใช้เพื่อทําการแทนที่โดยใช้ทางลัดที่สร้างขึ้นในขั้นตอนที่ 2.1 ตารางที่มีการจัดการต้นทางทั้งหมดจะถูกแปลงเป็นตารางภายนอกโดยใช้สคริปต์นี้LakehouseIdหมายถึงเลคเฮ้าส์ที่สร้างขึ้นในขั้นตอนที่ 2.1 ที่มีทางลัด// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) เรียกใช้คําสั่ง สมุดบันทึกทั้งหมดเพื่อนําเข้าวัตถุแค็ตตาล็อกจากเส้นทางระดับกลาง
หมายเหตุ
เมื่อนําเข้าหลายฐานข้อมูล คุณสามารถ (i) สร้างเลคเฮ้าส์ต่อฐานข้อมูล (วิธีที่ใช้ที่นี่) หรือ (ii) ย้ายตารางทั้งหมดจากฐานข้อมูลที่แตกต่างกันไปยังเลคเฮ้าส์เพียงแห่งเดียว สําหรับอย่างหลัง ตารางที่โยกย้ายทั้งหมดอาจเป็น <lakehouse>.<db_name>_<table_name>และคุณจะต้องปรับสมุดบันทึกนําเข้าให้สอดคล้องกัน
ขั้นตอนที่ 3: ตรวจสอบเนื้อหา
ขั้นตอนที่ 3 คือที่ที่คุณตรวจสอบว่าเมตาดาต้าได้รับการโยกย้ายเรียบร้อยแล้ว ดูตัวอย่างที่แตกต่างกัน
คุณสามารถดูฐานข้อมูลที่นําเข้าโดยการเรียกใช้:
%%sql
SHOW DATABASES
คุณสามารถตรวจสอบตารางทั้งหมดในเลคเฮ้าส์ (ฐานข้อมูล) โดยการเรียกใช้:
%%sql
SHOW TABLES IN <lakehouse_name>
คุณสามารถดูรายละเอียดของตารางเฉพาะโดยการเรียกใช้:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
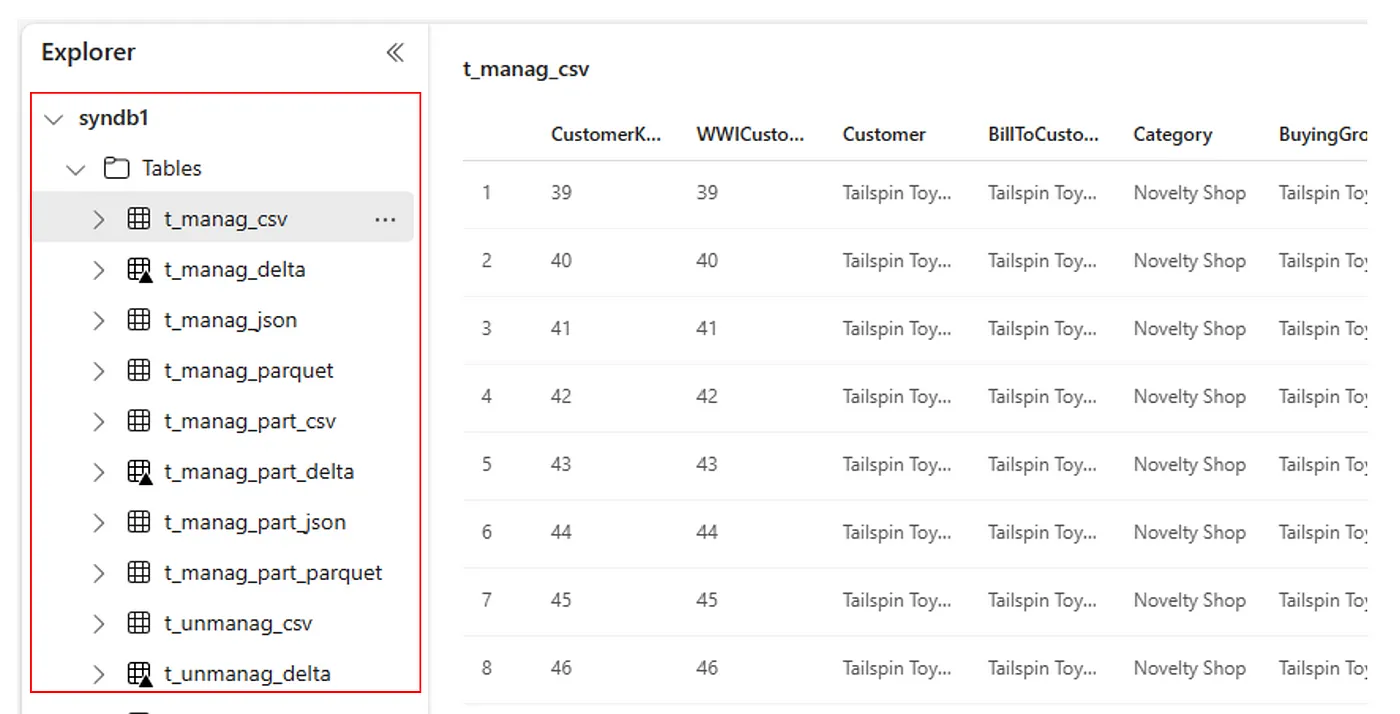
อีกวิธีหนึ่งคือ ตารางที่นําเข้าทั้งหมดจะสามารถมองเห็นได้ภายในส่วนตาราง UI ของ Lakehouse explorer สําหรับแต่ละ lakehouse
ข้อควรพิจารณาอื่นๆ
- ความสามารถในการปรับขนาด: โซลูชันนี้ใช้ API แค็ตตาล็อก Spark ภายในเพื่อนําเข้า/ส่งออก แต่ไม่ได้เชื่อมต่อโดยตรงกับ HMS เพื่อรับออบเจ็กต์แค็ตตาล็อก ดังนั้นโซลูชันจึงไม่สามารถปรับขนาดได้ดีหากแค็ตตาล็อกมีขนาดใหญ่ คุณจะต้องเปลี่ยนตรรกะการส่งออกโดยใช้ HMS DB
- ความแม่นยําของข้อมูล: ไม่มีการรับประกันการแยกใด ๆ ซึ่งหมายความว่าถ้าเครื่องคํานวณ Spark กําลังทําการแก้ไขที่เกิดขึ้นพร้อมกันกับ Metastore ในขณะที่สมุดบันทึกการโยกย้ายกําลังทํางาน สามารถนําข้อมูลที่ไม่สอดคล้องกันมาใช้ได้ใน Fabric lakehouse
เนื้อหาที่เกี่ยวข้อง
- Fabric vs. Azure Synapse Spark
- เรียนรู้เพิ่มเติมเกี่ยวกับตัวเลือกการโยกย้ายสําหรับพูล การกําหนดค่า ไลบรารี สมุดบันทึก และข้อกําหนดงาน Spark