Förbereda för att använda Apache Spark
Apache Spark är ett distribuerat databehandlingsramverk som möjliggör storskalig dataanalys genom att samordna arbete över flera bearbetningsnoder i ett kluster, som i Microsoft Fabric kallas för en Spark-pool. Mer enkelt uttryckt använder Spark en "divide and conquer"-metod för att snabbt bearbeta stora mängder data genom att distribuera arbetet över flera datorer. Processen för att distribuera uppgifter och sortera resultat hanteras åt dig av Spark.
Spark kan köra kod som skrivits på en mängd olika språk, inklusive Java, Scala (ett Java-baserat skriptspråk), Spark R, Spark SQL och PySpark (en Spark-specifik variant av Python). I praktiken utförs de flesta arbetsbelastningar för datateknik och analys med hjälp av en kombination av PySpark och Spark SQL.
Spark-pooler
En Spark-pool består av beräkningsnoder som distribuerar databearbetningsuppgifter. Den allmänna arkitekturen visas i följande diagram.
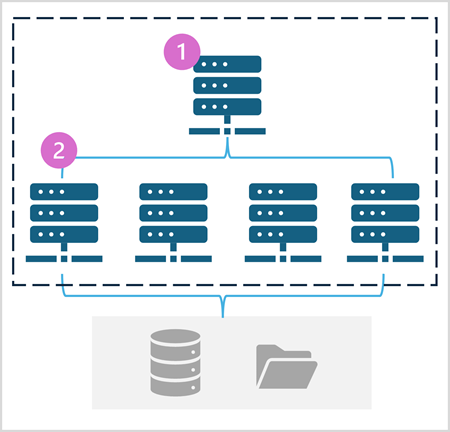
Som visas i diagrammet innehåller en Spark-pool två typer av noder:
- En huvudnod i en Spark-pool samordnar distribuerade processer via ett drivrutinsprogram .
- Poolen innehåller flera arbetsnoder där körprocesser utför de faktiska databearbetningsuppgifterna.
Spark-poolen använder den här distribuerade beräkningsarkitekturen för att komma åt och bearbeta data i ett kompatibelt datalager , till exempel ett datasjöhus baserat i OneLake.
Spark-pooler i Microsoft Fabric
Microsoft Fabric tillhandahåller en startpool på varje arbetsyta, vilket gör att Spark-jobb kan startas och köras snabbt med minimal konfiguration. Du kan konfigurera startpoolen så att den optimerar de noder den innehåller i enlighet med dina specifika arbetsbelastningsbehov eller kostnadsbegränsningar.
Dessutom kan du skapa anpassade Spark-pooler med specifika nodkonfigurationer som stöder dina specifika databehandlingsbehov.
Kommentar
Möjligheten att anpassa Inställningar för Spark-pool kan inaktiveras av Infrastrukturadministratörer på infrastrukturkapacitetsnivå. Mer information finns i Inställningar för kapacitetsadministration för Dataingenjör ing och Datavetenskap i fabric-dokumentationen.
Du kan hantera inställningar för startpoolen och skapa nya Spark-pooler i avsnittet Dataingenjör ing/Vetenskap i arbetsyteinställningarna.
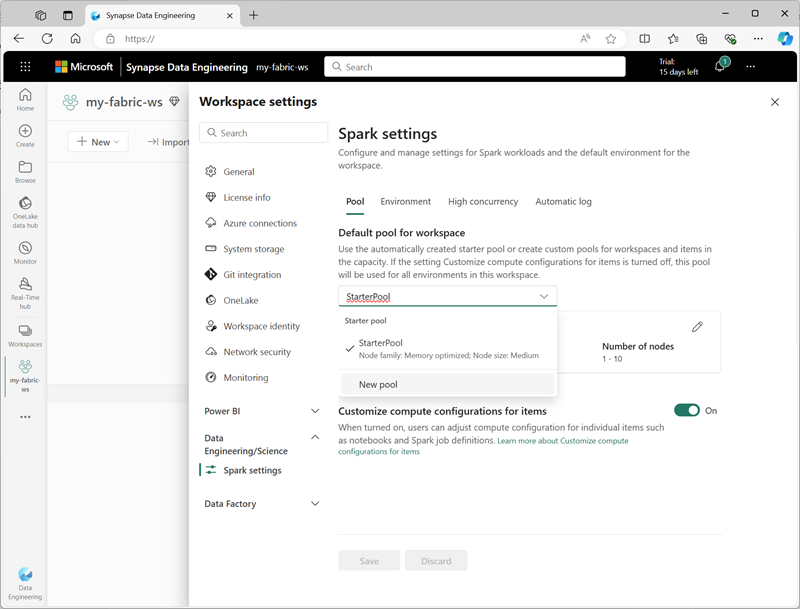
Specifika konfigurationsinställningar för Spark-pooler är:
- Nodfamilj: Den typ av virtuella datorer som används för Spark-klusternoderna. I de flesta fall ger minnesoptimerade noder optimala prestanda.
- Autoskalning: Om noder ska etableras automatiskt efter behov och i så fall det initiala och maximala antalet noder som ska allokeras till poolen.
- Dynamisk allokering: Om körprocesser ska allokeras dynamiskt på arbetsnoderna baserat på datavolymer.
Om du skapar en eller flera anpassade Spark-pooler på en arbetsyta kan du ange en av dem (eller startpoolen) som standardpool som ska användas om en specifik pool inte har angetts för ett visst Spark-jobb.
Dricks
Mer information om hur du hanterar Spark-pooler i Microsoft Fabric finns i Konfigurera startpooler i Microsoft Fabric och Skapa anpassade Spark-pooler i Microsoft Fabric i Microsoft Fabric-dokumentationen.
Körningar och miljöer
Spark-öppen källkod ekosystemet innehåller flera versioner av Spark-körningen, som avgör vilken version av Apache Spark, Delta Lake, Python och andra viktiga programvarukomponenter som är installerade. Inom en körning kan du dessutom installera och använda ett brett urval av kodbibliotek för vanliga (och ibland mycket specialiserade) uppgifter. Eftersom en hel del Spark-bearbetning utförs med PySpark säkerställer det stora utbudet av Python-bibliotek att det förmodligen finns ett bibliotek att hjälpa till med oavsett vilken uppgift du behöver utföra.
I vissa fall kan organisationer behöva definiera flera miljöer för att stödja en mängd olika databehandlingsuppgifter. Varje miljö definierar en specifik körningsversion samt de bibliotek som måste installeras för att utföra specifika åtgärder. Datatekniker och forskare kan sedan välja vilken miljö de vill använda med en Spark-pool för en viss uppgift.
Spark-runtimes Microsoft Fabric
Microsoft Fabric stöder flera Spark-körningar och fortsätter att lägga till stöd för nya körningar när de släpps. Du kan använda gränssnittet för arbetsyteinställningar för att ange Spark-körningen som används som standardmiljö när en Spark-pool startas.
Dricks
Mer information om Spark-körningar i Microsoft Fabric finns i Apache Spark Runtimes i Fabric i Microsoft Fabric-dokumentationen.
Miljöer i Microsoft Fabric
Du kan skapa anpassade miljöer på en Infrastruktur-arbetsyta så att du kan använda specifika Spark-körningsmiljöer, bibliotek och konfigurationsinställningar för olika databearbetningsåtgärder.
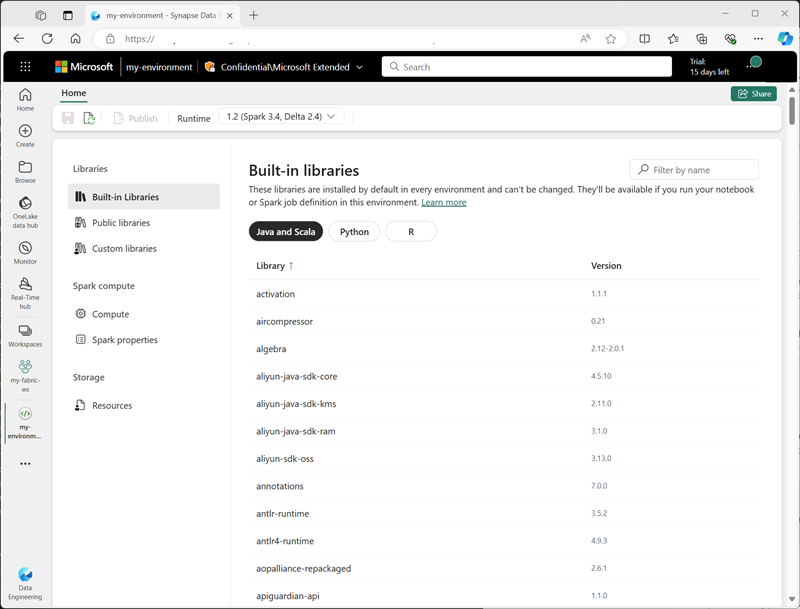
När du skapar en miljö kan du:
- Ange den Spark-körning som ska användas.
- Visa de inbyggda bibliotek som är installerade i varje miljö.
- Installera specifika offentliga bibliotek från Python Package Index (PyPI).
- Installera anpassade bibliotek genom att ladda upp en paketfil.
- Ange den Spark-pool som miljön ska använda.
- Ange Egenskaper för Spark-konfiguration för att åsidosätta standardbeteendet.
- Ladda upp resursfiler som måste vara tillgängliga i miljön.
När du har skapat minst en anpassad miljö kan du ange den som standardmiljö i arbetsyteinställningarna.
Dricks
Mer information om hur du använder anpassade miljöer i Microsoft Fabric finns i Skapa, konfigurera och använda en miljö i Microsoft Fabric i Microsoft Fabric-dokumentationen.
Ytterligare Konfigurationsalternativ för Spark
Att hantera Spark-pooler och miljöer är de primära sätten på vilka du kan hantera Spark-bearbetning på en infrastrukturarbetsyta. Det finns dock några ytterligare alternativ som du kan använda för att göra ytterligare optimeringar.
Intern körningsmotor
Den inbyggda körningsmotorn i Microsoft Fabric är en vektoriserad bearbetningsmotor som kör Spark-åtgärder direkt på lakehouse-infrastrukturen. Om du använder den interna körningsmotorn kan du avsevärt förbättra prestandan för frågor när du arbetar med stora datauppsättningar i Parquet- eller Delta-filformat.
Om du vill använda den inbyggda körningsmotorn kan du aktivera den på miljönivå eller i en enskild notebook-fil. Om du vill aktivera den inbyggda körningsmotorn på miljönivå anger du följande Spark-egenskaper i miljökonfigurationen:
- spark.native.enabled: true
- spark.shuffle.manager: org.apache.spark.shuffle.sort.ColumnarShuffleManager
Om du vill aktivera den interna körningsmotorn för ett visst skript eller en anteckningsbok kan du ange dessa konfigurationsegenskaper i början av koden, så här:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
Dricks
Mer information om den interna körningsmotorn finns i Intern körningsmotor för Fabric Spark i Microsoft Fabric-dokumentationen.
Läge för hög samtidighet
När du kör Spark-kod i Microsoft Fabric initieras en Spark-session. Du kan optimera effektiviteten för Spark-resursanvändning med hjälp av läget för hög samtidighet för att dela Spark-sessioner mellan flera samtidiga användare eller processer. När läget för hög samtidighet är aktiverat för notebook-filer kan flera användare köra kod i notebook-filer som använder samma Spark-session, samtidigt som kodisolering säkerställs för att undvika att variabler i en notebook-fil påverkas av kod i en annan notebook-fil. Du kan också aktivera läge för hög samtidighet för Spark-jobb, vilket möjliggör liknande effektivitet för samtidiga icke-interaktiva Spark-skriptkörningar.
Du aktiverar läge för hög samtidighet, använder avsnittet Dataingenjör ing/Science i gränssnittet för arbetsyteinställningar.
Dricks
Mer information om läget för hög samtidighet finns i Läget för hög samtidighet i Apache Spark för Infrastruktur i Microsoft Fabric-dokumentationen.
Automatisk MLFlow-loggning
MLFlow är ett öppen källkod bibliotek som används i datavetenskapsarbetsbelastningar för att hantera maskininlärningsträning och modelldistribution. En viktig funktion i MLFlow är möjligheten att logga modelltränings- och hanteringsåtgärder. Som standard använder Microsoft Fabric MLFlow för att implicit logga maskininlärningsexperimentaktivitet utan att dataexperten behöver inkludera explicit kod för att göra det. Du kan inaktivera den här funktionen i arbetsyteinställningarna.
Spark-administration för en infrastrukturkapacitet
Administratörer kan hantera Spark-inställningar på infrastrukturkapacitetsnivå så att de kan begränsa och åsidosätta Spark-inställningar på arbetsytor i en organisation.
Dricks
Mer information om hur du hanterar Spark-konfiguration på infrastrukturkapacitetsnivå finns i Konfigurera och hantera datateknik- och datavetenskapsinställningar för Infrastruktur-kapaciteter i Microsoft Fabric-dokumentationen.