Skapa anpassade Spark-pooler i Microsoft Fabric
I det här dokumentet förklarar vi hur du skapar anpassade Apache Spark-pooler i Microsoft Fabric för dina analysarbetsbelastningar. Apache Spark-pooler gör det möjligt för användare att skapa skräddarsydda beräkningsmiljöer baserat på deras specifika krav, vilket säkerställer optimal prestanda och resursanvändning.
Du anger de minsta och högsta noderna för automatisk skalning. Baserat på dessa värden hämtar systemet dynamiskt och drar tillbaka noder när jobbets beräkningskrav ändras, vilket resulterar i effektiv skalning och bättre prestanda. Den dynamiska allokeringen av exekutorer i Spark-pooler minskar också behovet av manuell körkonfiguration. I stället justerar systemet antalet utförare beroende på datavolym och beräkningsbehov på jobbnivå. Med den här processen kan du fokusera på dina arbetsbelastningar utan att behöva oroa dig för prestandaoptimering och resurshantering.
Obs
Om du vill skapa en anpassad Spark-pool behöver du administratörsåtkomst till arbetsytan. Kapacitetsadministratören måste aktivera alternativet anpassade arbetsytepooler i avsnittet Spark Compute i Kapacitetsadministratörsinställningar. Mer information finns i Spark-beräkningsinställningar för infrastrukturresurser.
Skapa anpassade Spark-pooler
Så här skapar eller hanterar du Spark-poolen som är associerad med din arbetsyta:
Gå till din arbetsyta och välj Arbetsyteinställningar.
Välj alternativet Data Engineering/Science för att expandera menyn och välj sedan Spark-inställningar.
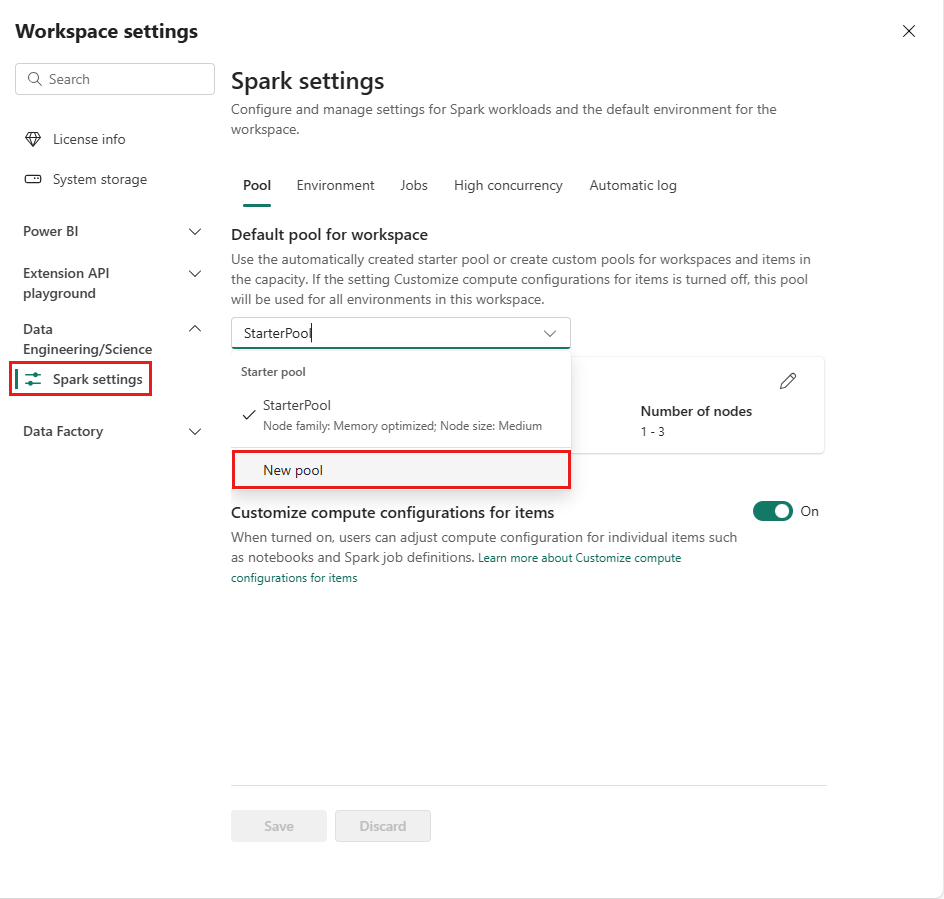
Välj alternativet Ny pool. På skärmen Skapa pool namnger du Spark-poolen. Välj även Node-familjenoch välj en Node-storlek från de tillgängliga storlekarna (Small, Medium, Large, X-Largeoch XX-Large) baserat på beräkningskrav för dina arbetsbelastningar.
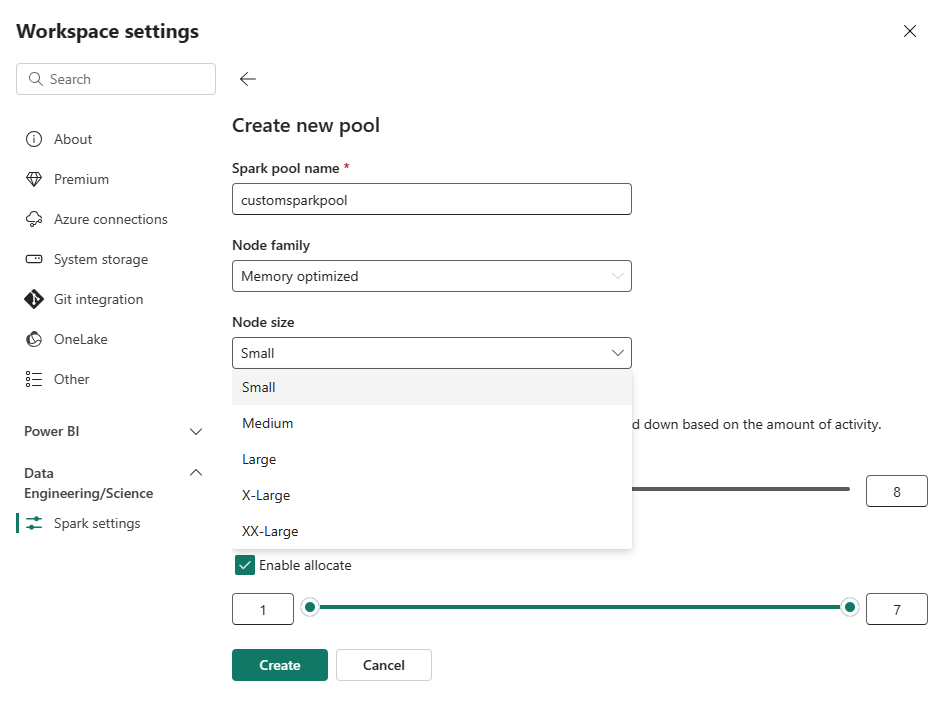
Du kan ange den minsta nodkonfigurationen för dina anpassade pooler till 1. Eftersom Fabric Spark ger återställningsbar tillgänglighet för kluster med en enda nod behöver du inte bekymra dig om jobbfel, förlust av session under fel eller över att betala för beräkning för mindre Spark-jobb.
Du kan aktivera eller inaktivera automatisk skalning för dina anpassade Spark-pooler. När autoskalning är aktiverat hämtar poolen dynamiskt nya noder upp till den maximala nodgräns som användaren har angett och drar sedan tillbaka dem efter jobbkörningen. Den här funktionen ger bättre prestanda genom att justera resurser baserat på jobbkraven. Du får justera storleken på noderna, som passar inom de kapacitetsenheter som köpts som en del av Fabric-kapacitetens SKU.
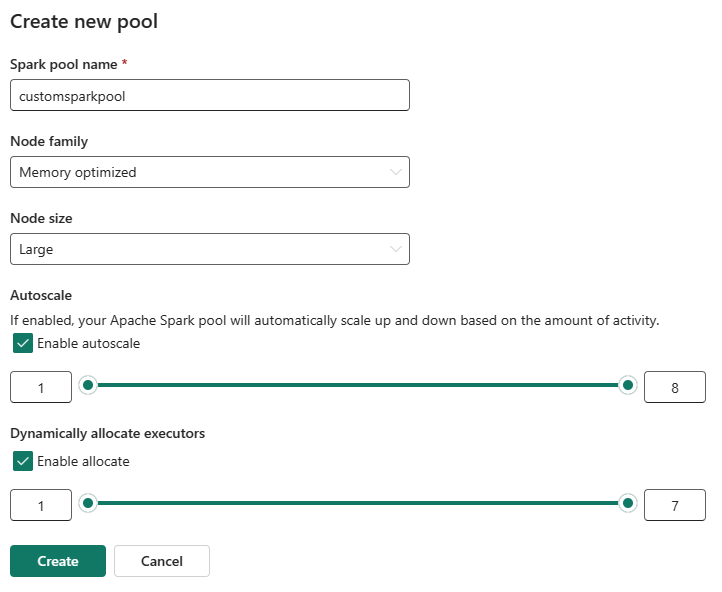
Du kan också välja att aktivera dynamisk körallokering för Spark-poolen, vilket automatiskt avgör det optimala antalet köre inom den användardefinierade maximala gränsen. Den här funktionen justerar antalet utförare baserat på datavolym, vilket resulterar i bättre prestanda och resursanvändning.

Dessa anpassade pooler har en standardtid på 2 minuter för autopaus. När varaktigheten för autopaus har nåtts upphör sessionen att gälla och klustren är oallokerade. Du debiteras baserat på antalet noder och hur länge de anpassade Spark-poolerna används.
Relaterat innehåll
- Läs mer i den offentliga dokumentationen för Apache Spark .
- Kom igång med administrationsinställningarna för Spark-arbetsytor i Microsoft Fabric.