Intern körningsmotor för Fabric Spark
Den inbyggda körningsmotorn är en banbrytande förbättring för Apache Spark-jobbkörningar i Microsoft Fabric. Den här vektoriserade motorn optimerar prestanda och effektivitet för dina Spark-frågor genom att köra dem direkt på lakehouse-infrastrukturen. Motorns sömlösa integrering innebär att den inte kräver några kodändringar och undviker leverantörslåsning. Det stöder Apache Spark-API:er och är kompatibelt med Runtime 1.3 (Apache Spark 3.5) och fungerar med både Parquet- och Delta-format. Oavsett dina datas plats i OneLake, eller om du kommer åt data via genvägar, maximerar den interna körningsmotorn effektivitet och prestanda.
Den interna körningsmotorn höjer frågeprestanda avsevärt samtidigt som driftskostnaderna minimeras. Den ger en anmärkningsvärd hastighetsförbättring och ger upp till fyra gånger snabbare prestanda jämfört med traditionell OSS (programvara med öppen källkod) Spark, vilket verifieras av TPC-DS 1 TB benchmark. Motorn är skicklig på att hantera en mängd olika databearbetningsscenarier, allt från rutinmässig datainmatning, batchjobb och ETL-uppgifter (extrahera, transformera, läsa in) till komplexa datavetenskapsanalyser och dynamiska interaktiva frågor. Användarna drar nytta av snabbare bearbetningstider, ökat dataflöde och optimerad resursanvändning.
Den interna körningsmotorn baseras på två viktiga OSS-komponenter: Velox, ett C++-databasaccelerationsbibliotek som introducerades av Meta och Apache Gluten (inkubering), ett mellanlager som ansvarar för att avlasta JVM-baserade SQL-motorers körning till inbyggda motorer som introducerades av Intel.
Kommentar
Den interna körningsmotorn är för närvarande i offentlig förhandsversion. Mer information finns i de aktuella begränsningarna. Vi rekommenderar att du aktiverar den interna körningsmotorn för dina arbetsbelastningar utan extra kostnad. Du kommer att dra nytta av snabbare jobbkörning utan att betala mer - i själva verket betalar du mindre för samma arbete.
När du ska använda den inbyggda körningsmotorn
Den interna körningsmotorn erbjuder en lösning för att köra frågor på storskaliga datauppsättningar. den optimerar prestanda med hjälp av de inbyggda funktionerna i underliggande datakällor och minimerar de omkostnader som vanligtvis associeras med dataflytt och serialisering i traditionella Spark-miljöer. Motorn stöder olika operatorer och datatyper, inklusive sammanslagningshashaggregat, BNLJ (broadcast nested loop join) och exakta tidsstämpelformat. Men för att dra full nytta av motorns funktioner bör du överväga dess optimala användningsfall:
- Motorn är effektiv när du arbetar med data i Parquet- och Delta-format, som den kan bearbeta internt och effektivt.
- Frågor som omfattar invecklade omvandlingar och sammansättningar drar stor nytta av motorns funktioner för kolumnbearbetning och vektorisering.
- Prestandaförbättringar är mest anmärkningsvärda i scenarier där frågorna inte utlöser återställningsmekanismen genom att undvika funktioner eller uttryck som inte stöds.
- Motorn passar bra för frågor som är beräkningsintensiva snarare än enkla eller I/O-bundna.
Information om operatorer och funktioner som stöds av den interna körningsmotorn finns i Dokumentation om Apache Gluten.
Aktivera den inbyggda körningsmotorn
För att kunna använda de fullständiga funktionerna i den inbyggda körningsmotorn under förhandsversionsfasen krävs specifika konfigurationer. Följande procedurer visar hur du aktiverar den här funktionen för notebook-filer, Spark-jobbdefinitioner och hela miljöer.
Viktigt!
Den interna körningsmotorn stöder den senaste GA-körningsversionen, som är Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Med lanseringen av den inbyggda körningsmotorn i Runtime 1.3 har stödet för den tidigare versionen – Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4)– upphört. Vi rekommenderar att alla kunder uppgraderar till den senaste Runtime 1.3. Om du använder Native Execution Engine på Runtime 1.2 kommer native acceleration snart att inaktiveras.
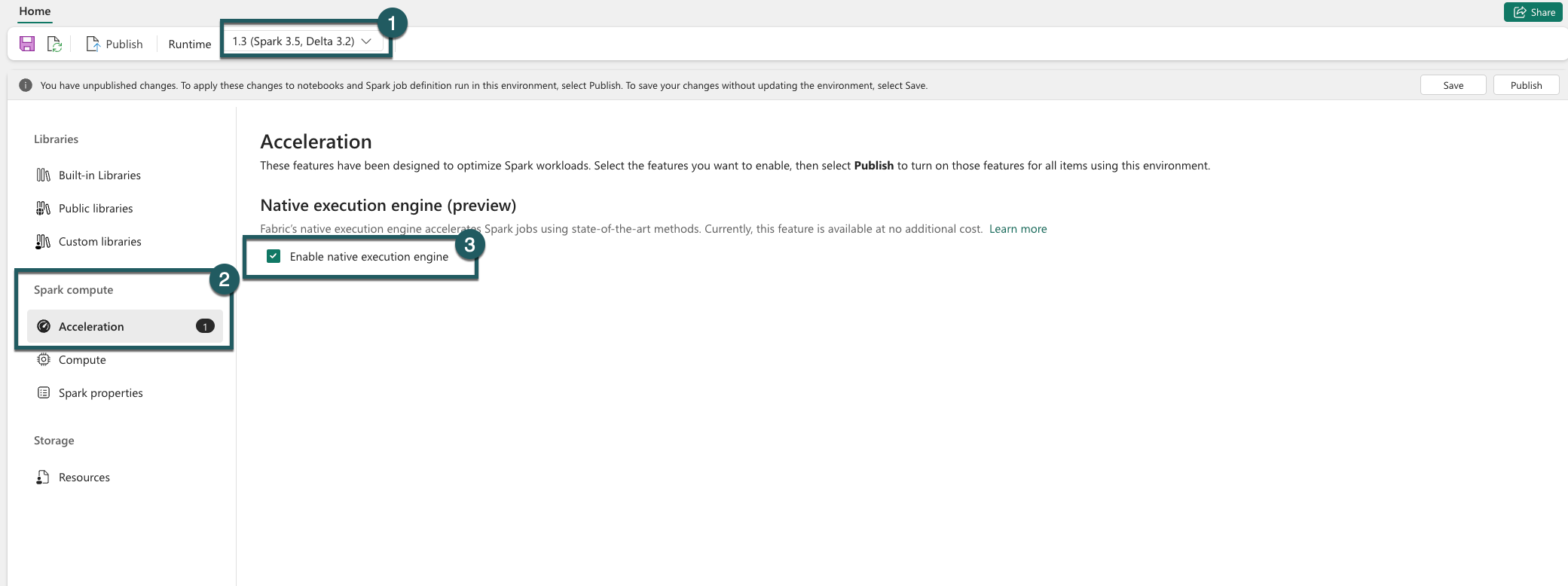
Aktivera på miljönivå
För att säkerställa en enhetlig prestandaförbättring aktiverar du den inbyggda körningsmotorn för alla jobb och notebook-filer som är associerade med din miljö:
Gå till miljöinställningarna.
Gå till Spark-beräkning.
Gå till fliken Acceleration .
Markera kryssrutan Aktivera inbyggd körningsmotor .
Spara och publicera ändringarna.

När de är aktiverade på miljönivå ärver alla efterföljande jobb och notebook-filer inställningen. Det här arvet säkerställer att alla nya sessioner eller resurser som skapas i miljön automatiskt drar nytta av de förbättrade körningsfunktionerna.
Viktigt!
Tidigare aktiverades den interna körningsmotorn via Spark-inställningar i miljökonfigurationen. Med vår senaste uppdatering (distribution pågår) har vi förenklat detta genom att introducera en växlingsknapp på fliken Acceleration i miljöinställningarna. Återaktivera den interna körningsmotorn med hjälp av den nya växlingsknappen – om du vill fortsätta med den interna körningsmotorn går du till fliken Acceleration i miljöinställningarna och aktiverar den via växlingsknappen. Den nya växlingsinställningen i användargränssnittet prioriteras nu framför tidigare Spark-egenskapskonfigurationer. Om du tidigare har aktiverat Native Execution Engine via Spark-inställningar inaktiveras den tills den återaktiveras via UI-växlingen.
Aktivera för en notebook- eller Spark-jobbdefinition
Om du vill aktivera den interna körningsmotorn för en enskild notebook-fil eller Spark-jobbdefinition måste du lägga till nödvändiga konfigurationer i början av körningsskriptet:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
För notebook-filer infogar du nödvändiga konfigurationskommandon i den första cellen. För Spark-jobbdefinitioner inkluderar du konfigurationerna i frontlinjen för din Spark-jobbdefinition. Den interna körningsmotorn är integrerad med livepooler, så när du aktiverar funktionen börjar den gälla omedelbart utan att du behöver starta en ny session.
Viktigt!
Konfigurationen av den interna körningsmotorn måste göras innan Spark-sessionen initieras. När Spark-sessionen har startats spark.shuffle.manager blir inställningen oföränderlig och kan inte ändras. Se till att dessa konfigurationer anges i %%configure blocket i notebook-filer eller i Spark-sessionsverktyget för Spark-jobbdefinitioner.
Kontroll på frågenivå
Mekanismerna för att aktivera den interna körningsmotorn på klient-, arbetsytans och miljöns nivåer, sömlöst integrerade med användargränssnittet, är under aktiv utveckling. Under tiden kan du inaktivera den interna körningsmotorn för specifika frågor, särskilt om de omfattar operatorer som för närvarande inte stöds (se begränsningar). Om du vill inaktivera anger du Spark-konfigurationen spark.native.enabled till false för den specifika cell som innehåller din fråga.
%%sql
SET spark.native.enabled=FALSE;

När du har kört frågan där den interna körningsmotorn är inaktiverad måste du återaktivera den för efterföljande celler genom att ange spark.native.enabled till true. Det här steget är nödvändigt eftersom Spark kör kodceller sekventiellt.
%%sql
SET spark.native.enabled=TRUE;
Identifiera åtgärder som körs av motorn
Det finns flera metoder för att avgöra om en operator i ditt Apache Spark-jobb bearbetades med den interna körningsmotorn.
Spark-användargränssnitt och Spark-historikserver
Gå till Spark-användargränssnittet eller Spark-historikservern för att hitta den fråga som du behöver inspektera. Om du vill komma åt Spark-webbgränssnittet går du till Spark-jobbdefinitionen och kör det. På fliken Kör väljer du ... bredvid Programnamn och väljer Öppna Spark-webbgränssnittet. Du kan också komma åt Spark-användargränssnittet från fliken Övervaka på arbetsytan. Välj anteckningsboken eller pipelinen, på övervakningssidan finns det en direktlänk till Spark-användargränssnittet för aktiva jobb.

I frågeplanen som visas i Gränssnittet för Spark letar du efter eventuella nodnamn som slutar med suffixet Transformer, *NativeFileScan eller VeloxColumnarToRowExec. Suffixet anger att den interna körningsmotorn körde åtgärden. Noder kan till exempel märkas som RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer eller BroadcastNestedLoopJoinExecTransformer.

Förklara dataram
Du kan också köra kommandot i anteckningsboken df.explain() för att visa körningsplanen. Leta efter samma Transformer, *NativeFileScan eller VeloxColumnarToRowExec suffix i utdata. Den här metoden ger ett snabbt sätt att bekräfta om specifika åtgärder hanteras av den interna körningsmotorn.

Reservmekanism
I vissa fall kanske den inbyggda körningsmotorn inte kan köra en fråga på grund av orsaker som att funktioner inte stöds. I dessa fall återgår åtgärden till den traditionella Spark-motorn. Den här automatiska återställningsmekanismen säkerställer att arbetsflödet inte avbryts.


Övervaka frågor och dataramar som körs av motorn
För att bättre förstå hur den interna körningsmotorn tillämpas på SQL-frågor och DataFrame-åtgärder, och för att öka detaljnivån för steg- och operatornivåerna, kan du läsa Mer detaljerad information om körningen av den interna motorn i Spark-användargränssnittet och Spark History Server.
Fliken Intern körningsmotor
Du kan gå till den nya fliken Gluten SQL/DataFrame för att visa information om Gluten-kompilering och frågekörning. Tabellen Frågor ger insikter om antalet noder som körs på den interna motorn och de som faller tillbaka till JVM för varje fråga.

Diagram över frågekörning
Du kan också välja på frågebeskrivningen för visualiseringen av Apache Spark-frågeutförandeplanen. Körningsdiagrammet innehåller intern körningsinformation mellan faser och deras respektive åtgärder. Bakgrundsfärger skiljer körningsmotorerna åt: grönt representerar den interna körningsmotorn, medan ljusblå anger att åtgärden körs på JVM-standardmotorn.

Begränsningar
Den inbyggda körningsmotorn förbättrar prestandan för Apache Spark-jobb, men observera dess aktuella begränsningar.
- Vissa Delta-specifika åtgärder stöds inte ännu eftersom vi aktivt arbetar med det, inklusive sammanslagningsoperationer, kontrollpunktsskanningar och borttagningsvektorer.
- Vissa Spark-funktioner och -uttryck är inte kompatibla med den interna körningsmotorn, till exempel användardefinierade funktioner (UDF:er) och
array_containsfunktionen samt Spark-strukturerad strömning. Användning av dessa inkompatibla åtgärder eller funktioner som en del av ett importerat bibliotek kommer också att orsaka återställning till Spark-motorn. - Genomsökningar från lagringslösningar som använder privata slutpunkter stöds inte (men vi arbetar aktivt med det).
- Motorn stöder inte ANSI-läge, så den söker, och när ANSI-läget är aktiverat återgår det automatiskt till vanilj-Spark.
När du använder datumfilter i frågor är det viktigt att se till att datatyperna på båda sidor av jämförelsen matchar för att undvika prestandaproblem. Felmatchade datatyper kanske inte ger ökad frågekörning och kan kräva explicit gjutning. Se alltid till att datatyperna på vänster sida (LHS) och höger sida (RHS) för en jämförelse är identiska, eftersom felmatchade typer inte alltid kommer att kastas automatiskt. Om en typmatchning inte kan undvikas använder du explicit gjutning för att matcha datatyperna, till exempel CAST(order_date AS DATE) = '2024-05-20'. Frågor med oförenliga datatyper som kräver konvertering accelereras inte av Native Execution Engine, så det är viktigt att säkerställa typkonsekvens för att bibehålla prestandan. Till exempel, i stället för order_date = '2024-05-20' var order_date är DATETIME och strängen är DATE, uttryckligen gjuten order_date för att DATE säkerställa konsekventa datatyper och förbättra prestanda.