Konfigurera startpooler i Microsoft Fabric
I den här artikeln förklarar vi hur du anpassar startpooler i Microsoft Fabric för dina analysarbetsbelastningar. Startpooler är ett snabbt och enkelt sätt att använda Spark på Microsoft Fabric-plattformen inom några sekunder. Du kan använda Spark-sessioner direkt i stället för att vänta på att Spark ska konfigurera noderna åt dig, vilket hjälper dig att göra mer med data och få insikter snabbare.
Startpooler har Spark-kluster som alltid är på och redo för dina begäranden. De använder medelstora noder och kan skalas upp baserat på dina arbetsbelastningskrav.
Du kan ange maximalt antal noder för automatisk skalning baserat på arbetsbelastningskraven för datateknik eller datavetenskap. Baserat på de maximala noder som du konfigurerar hämtar systemet dynamiskt och drar tillbaka noder när jobbets beräkningskrav ändras, vilket resulterar i effektiv skalning och bättre prestanda.
Du kan också ange den maximala gränsen för exekutorer i startpooler och med dynamisk allokering aktiverat justerar systemet antalet utförare beroende på datavolym och beräkningsbehov på jobbnivå. Med den här processen kan du fokusera på dina arbetsbelastningar utan att behöva oroa dig för prestandaoptimering och resurshantering.
Kommentar
Om du vill anpassa en startpool behöver du administratörsåtkomst till arbetsytan.
Konfigurera startpooler
Så här hanterar du den startpool som är associerad med din arbetsyta:
Gå till din arbetsyta och välj inställningarna för Arbetsyta.

Välj sedan alternativet Dataingenjör ing/Vetenskap för att expandera menyn.
Välj alternativet StarterPool.

Du kan ange maximal nodkonfiguration för dina startpooler till ett tillåtet nummer baserat på den köpta kapaciteten eller minska standardkonfigurationen för maxnoder till ett mindre värde när du kör mindre arbetsbelastningar.
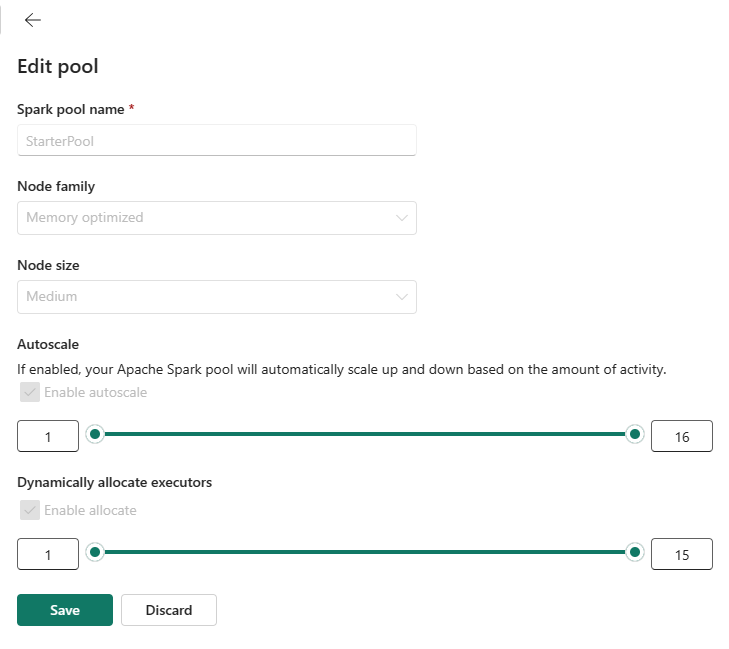

I följande avsnitt visas olika standardkonfigurationer och de maximala nodgränser som stöds för startpooler baserat på SKU:er för Microsoft Fabric-kapacitet:
| SKU-namn | Kapacitetsenheter | Virtuella Spark-kärnor | Nodstorlek | Maximalt antal standardnoder | Maximalt antal noder |
|---|---|---|---|---|---|
| F2 | 2 | 4 | Medium | 1 | 1 |
| F4 | 4 | 8 | Medium | 1 | 1 |
| F8 | 8 | 16 | Medium | 2 | 2 |
| F16 | 16 | 32 | Medium | 3 | 4 |
| F32 | 32 | 64 | Medium | 8 | 8 |
| F64 | 64 | 128 | Medium | 10 | 16 |
| (Utvärderingskapacitet) | 64 | 128 | Medium | 10 | 16 |
| F128 | 128 | 256 | Medium | 10 | 32 |
| F256 | 256 | 512 | Medium | 10 | 64 |
| F512 | 512 | 1024 | Medium | 10 | 128 |
| F1024 | 1024 | 2048 | Medium | 10 | 200 |
| F2048 | 2048 | 4096 | Medium | 10 | 200 |
Kommentar
Om du vill anpassa en startpool behöver du administratörsåtkomst till arbetsytan.
Relaterat innehåll
- Läs mer i den offentliga Dokumentationen om Apache Spark.
- Kom igång med Administrationsinställningar för Spark-arbetsytor i Microsoft Fabric.